 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Co-design has long been a vibrant discussion point in the HPC community. The need to coordinate development across hardware, software, and system architecture in the face of constraints from a declining Moore’s Law is a given. The question is how to do it. In this brief Q&A, Sadasivan (Sadas) Shankar, visiting lecturer at Harvard and former senior principal engineer in Intel’s Technology and Manufacturing Organization, glimpses into his invited SC16 talk, Co-Design 3.0 – Configurable Extreme Computing, Leveraging Moore’s Law for Real Applications.
HPCWire: Co-design means different things to different people and your talk is positioned as a discussion around emerging Co-design 3.0. What’s your definition of co-design and maybe talk a bit about the six scaling paradigm you suggest are relevant to co-design.

Sadas Shankar: Co-design refers to the methodology in which architecture of the computing platform, hardware, software, and applications are concurrently designed for a global optimum. In other words, it is the antithesis of the traditionally serial (or mostly serial) way of addressing the problem.
The six scaling paradigms are given below:
- Scale of physical and man-made entities
- Combinatorial Scaling
- Scaling of algorithms
- Technology scaling
- Economics of scaling
- Scaling of applications
Currently most of the thinking revolves around Moore’s law and cost (paradigms 4 and 5), with focus on big data analytics (part of paradigm 6). Till now, Moore’s law was the main driver for information technology, which in turn was driving the ecosystem. However, there are more ecosystems and collaterals changing that need to be addressed.
One specific example is can we could use the algorithms that have been developed for big data (paradigm 3 & 6) to accelerate drug development or design a new battery (paradigm 6) or solve environmental toxicity (paradigms 2 and 6). This is starting to happen, but not in a large scale. The key maybe that the current paradigm in which a given architecture-hardware combination on which software-algorithms are developed for a given application is too restricted and non-optimal. Ideally, it should be available to users to be able to customize it as they need it (See the last question).
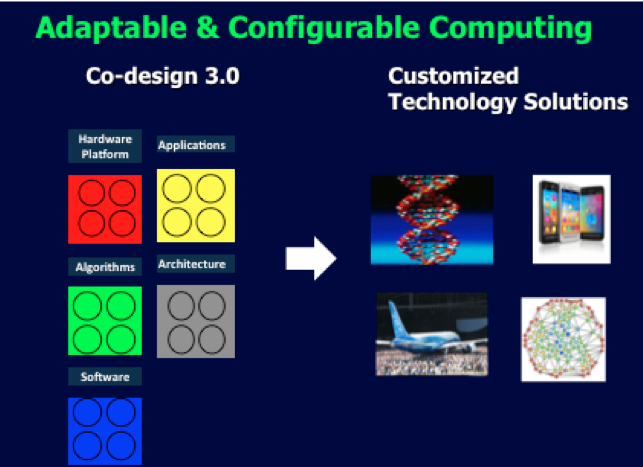 HPCWire: You use a Lego metaphor for how systems components – hardware, applications, algorithms, architecture, software – must become more easily integrated; yet doing this has proven challenging. How should differing domain expertise and different communities (academia, industry, government) be incented and organized to work together?
HPCWire: You use a Lego metaphor for how systems components – hardware, applications, algorithms, architecture, software – must become more easily integrated; yet doing this has proven challenging. How should differing domain expertise and different communities (academia, industry, government) be incented and organized to work together?
Shankar: Within United States, at the governmental level, Department of Energy, NSA and related organizations are the biggest consumers of computation. The hardware vendors put together components, microprocessors to certain high level specifications. The users compile software and use them depending on the applications. The business model for HPC has been like this since the advent of the mainframe. But recently, things have shifted. Silicon Valley and the entrepreneurs are starting to disrupt this model at low cost. Examples are given in the talk.
The question is can we put together a hybrid model in which an initiative in which academics, national labs and other federal agencies, and industry can come together to develop an evolving and flexible initiative. The main difference between this and traditional HPC or Computational centers is bringing in Silicon Valley start-up thinking into the mix. The ability to make Co-design an evolving effort with low cost business model and long-term sustainability is important to make this happen. For this both academics and industrial partners need to be part of this as well.
There is another problem brewing in the horizon; HPC (from the era of Thinking Machines, Cray, CDC etc.) is not considered an exciting area for students to specialize in or do research in. This means that the pipeline for HPC may dry up. Hence the need to tying Co-design with the academia in addition to just the national labs.
HPCWire: What is different about Co-Design 3.0, compared to what is already being done or why do we need it?
Shankar: Co-design 3.0 is both about a thinking shift and more distributed ecosystem in which not just the high-end users, but all get to design computing for their purposes. In order to financially and intellectually sustain and grow such a system, it needs the academic and industrial participants in addition to research labs and federal agencies. Coming back to the example of Lego blocks, players could make a truck or a car depending on the need. This ability is due to modularity, integrability and re-usability of the blocks. If I can personalize a smart phone (with “apps”), should this Co-design have “blocks” and “apps”? We don’t know yet, but should test out the different possibilities.
HPCWire: Two technologies getting a lot of attentions today are neuromorphic computing and quantum computing, each in its own way representing different computing paradigms. Looking at the implications flowing from Co-design 3.0 what’s your sense of emerging computing technologies that will be important in Post Moore’s era?
Shankar: Co-design 3.0 is meant to address these kinds of shifting paradigms. Both of these computing platforms may be optimal for specific applications such as neuromorphic computing for pattern recognition, and quantum computing for cryptography. This is in line with Co-design 3.0 thinking-one should not have to be locked into a given hardware and architecture for all applications. This is possible as long as the building “blocks” are reasonably modular enough, but yet can be assembled depending on the applications and disassembled without a large cost penalty. Although this is more difficult for quantum computing (QC) where information processing itself is based on qubits, there is still ability to develop the blocks such that part of a given larger problem can be solved in QC, while the remaining part can be solved in conventional HPC architectures. We will touch upon some of the challenges that need to be addressed by research, development, and application. Co-design 3.0 is as much a thinking paradigm as well as a framework to make it happen by some of the best minds from academia to government to Silicon Valley.
 HPCWire: Finally, in your abstract, you note developing a class at Harvard in which students are “taught hands-on about using extreme computing to address real applications.” Could you briefly describe the effort and how it is working?
HPCWire: Finally, in your abstract, you note developing a class at Harvard in which students are “taught hands-on about using extreme computing to address real applications.” Could you briefly describe the effort and how it is working?
Shankar: As we mentioned before, students seem to be losing interest in HPC as an area for future career growth. In order to get the students excited, we offered a class, possibly for the first time in US or elsewhere on “Extreme Computing for Real Applications”. We wanted the students t get excited that they could solve problems of societal importance by using hardware and software at the limits of what computing could accomplish. The course gave the students hands-on experience on 3 different applications (social networking, cancer genomics, battery modeling), on 3 different computing hardware platforms (cloud computing, cluster computing, supercomputer in Department of Energy Laboratory).
This course was taught by faculty from Harvard, in collaboration with the visitors from National Cancer Institute and Argonne National Laboratories, and had both lectures explaining the basis of theory and methods and computer lab sessions in which the students actually solved the problem. We are planning to offer the class again in Fall 2017. More write-up of the class is given in the web link below: Computing that goes to extremes
Shankar’s SC16 talk is Thursday at 10:30 am: http://sc16.supercomputing.org/presentation/?id=inv109&sess=sess261
Presenter Bio
Sadasivan (Sadas) Shankar is the first Margaret and Will Hearst Visiting Lecturer in Computational Science and Engineering at the Harvard John A. Paulson School of Engineering and Applied Sciences. In fall 2013, as the first Distinguished Scientist in Residence at the Institute of Applied Computational Sciences in Harvard, along with Dr. Tim Kaxiras, he developed and co-instructed with Dr. Brad Malone, a graduate-level class on Computational Materials Design, which covered fundamental atomic and quantum techniques and practical applications for new materials by design.
Shankar was also senior principal engineer and led materials design in the Design and Technology Group within the Intel Technology and Manufacturing Organization. Over his tenure in research and development in the semiconductor industry, he and his team have worked on several new initiatives; using modeling to optimize semiconductor processing and equipment for several technology generations, advanced process control using physics-based models, thermo-mechanical reliability of microprocessors, thermal modeling of 3D die stacking, and using thermodynamic principles to estimate energy efficiency of ideal computing architectures.

























































