 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Intel made a flurry of announcements at SC16 today. Artificial intelligence figured prominently with new offerings and portfolio details. (Intel held back some news for an AI day planned this Thursday in San Francisco.) There was a fair amount of strutting for Xeon Phi’s (Knights landing) and OmniPath’s (OPA) strong showing in the TOP500. A new Broadwell chip was announced. So was the Intel HPC Orchestrator, a proprietary version of the open source HPC software stack from OpenHPC, the Linux Foundation project that Intel helped launch at SC15.
In the pre-briefing press call last week, Charlie Wuischpard, vice president, Scalable Data Center Solutions Group, warned those on the line there was a fair amount of material to cover. Here are a few highlights:
- Knights Landing. The latest Intel Xeon Phi processor was in nine new systems on the TOP500, including two systems in the top 10, with the Cori system ranking fifth and Oakforest-PAC system ranking sixth. Additionally, Intel was the prime contractor supporting the Collaboration of Oak Ridge, Argonne and Lawrence Livermore (CORAL) in a top 20 system, the Argonne Theta system. (For more coverage see HPCwire article, US, China Vie for Supercomputing Supremacy.)
- OmniPath. Shipping for just nine months, Intel’s 100GB Omni-Path Architecture was deployed in 28 of the top 500 and “now has 66 percent of the 100GB market” according to Intel. TOP500 designs include Oakforest-PACS, MIT Lincoln Lab and CINECA. Intel says OPA is double “the number of InfiniBand EDR systems and now accounts for around 66 percent of all 100GB systems.”
- Artificial Intelligence. Intel debuted a Deep Learning Inference Accelerator card; it’s a field-programmable gate array (FPGA)-based hardware and software solution for neural network acceleration. It has an Arria 10 FPGA optimized for targeted topologies of convolutional neural networks and will be available in 2017.
 Broadwell. Intel introduced new Xeon processor E5-2699A v4 which becomes its fastest two-socket processor. The company cited the addition of the new top sku in the product line as evidence of its commitment to Broadwell.
Broadwell. Intel introduced new Xeon processor E5-2699A v4 which becomes its fastest two-socket processor. The company cited the addition of the new top sku in the product line as evidence of its commitment to Broadwell.

Launch of the Intel HPC Orchestrator was not unexpected. Intel, of course, was a driving force behind creation of OpenHPC, which was formalized as a Linux Foundation Open Collaborative Project in June and introduced its first 1.1. version then. The straightforward idea is that providing an open source HPC software stack and associated tools will ease HPC deployment, particularly in the enterprise.
There were early concerns over Intel’s prominent role, and IBM has declined to join, but the stamp of Linux Foundation has eased worries somewhat. ARM is an enthusiastic member and has announced it would be supported in OpenHPC v 1.2.0.
OpenHPC says there have been roughly 200K downloads and 30K website visits to date. (See HPCwire articles, ARM Will Be Part of OpenHPC 1.2 Release at SC16; OpenHPC Pushes to Prove its Openness and Value at SC16.)
The Intel HPC Orchestrator is essentially a supported version of the OpenHPC stack with a few Intel optimizations and tools (see figure). For example, Intel has validated configurations for Xeon Phi and OmiPath. Cluster checker, formally part of the Intel cluster readiness product, is now included in Intel HPC Orchestrator as is Intel Lustre Enterprise edition. Wuischpard said Lustre’s use in nine of the top ten supercomputer demonstrates its traction and noted Seagate has struck a deal to adopt Intel Lustre Enterprise Edition over its own version.
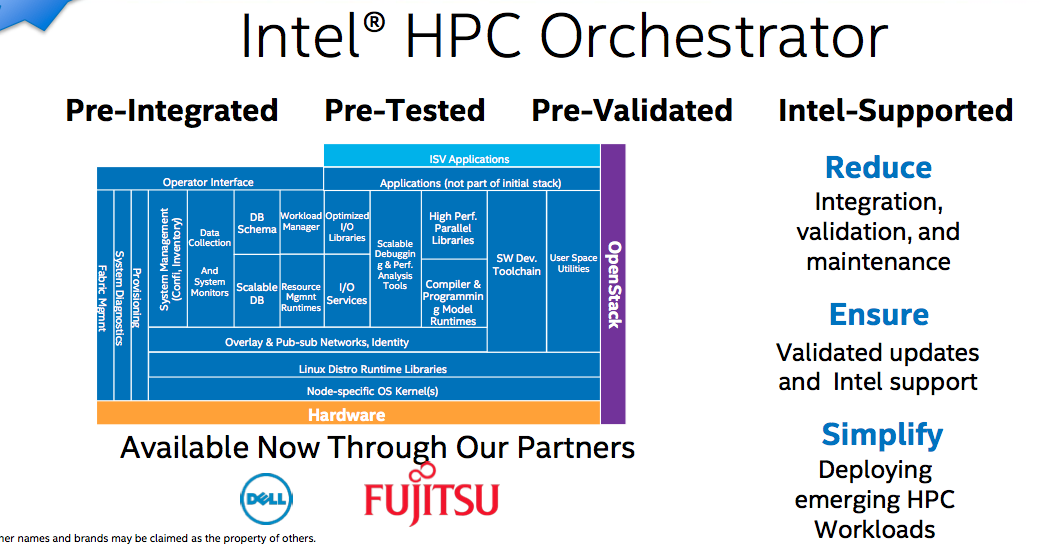
There are open source elements in Intel’s offering. “People may have a scheduler of choice and they have the ability to plug in a scheduler, so it (Intel HPC Orchestrator) is not completely hardened into a one solid piece,” said Wuischpard. “You can expect to see more from us around the software stack and software enablement in terms of not just delivering systems at these scales but particularly for work were doing at the top end of the supercomputing world.”
The AI announcements were among the more interesting. Indeed at SC16 this year, many technology vendors have pivoted to so-called AI as the clarion call. Barry Davis, GM, Intel’s Accelerated Workload Group, said Intel’s approach to AI is a departure from its past practice. “We are working on providing all the tools necessary to OEMs and end user customers to actually implement an AI solution,” he said (see figure below).
“We’ve augmented our data analytics acceleration library. We’ve also brought out Intel distributions for Python, which is a growing language for AI. Optimizing open frameworks is a huge area for us. One of the beauties of AI is most of the programming happens at a higher level on top of these open industry frameworks.”
At ISC, Intel introduced Intel Caffe and optimized one of the most popular AI frameworks in use today. “We are working on Spark, on Theano, Torch, etc., and we have one called the Neon framework which is actually part of our acquisition of Nervana which happened several months ago,” Davis said. Nervana, of course, is essentially full AI development platform.

Intel plans to eventually offer AI solution blueprints, “We don’t have anything to talk about these right now but are working on reference platforms across many different industries once again focused on AI workloads.”
He briefly touched on Knights Mill, Intel’s first AI specific product first discussed back in August. “It is a variation of KNL and once again more to be said on 11/17, but what we are saying here is that it is a host CPU, bootable processor, with mixed precision performance for machine learning. What that means is we’ve augmented our capabilities for double precision with high performance single precision and other reduced precision formats for AI space,” he said.
The new Deep Learning Inference Accelerator, said Davis, has a full set of convolutional neural algorithms commonly used in things like image detection and fraud detection integrated that with all the libraries and other programming tools. He says it provides a four-fold performance per watt improvement over Xeon product.
Talking about the new Broadwell offering, Wuischpard said, “I know everyone’s familiar with the product Skylake, available next year, and many thought we weren’t going to be enhancing the current Broadwell or v4 line of products. There’s a couple of things to read in here. We continue to enhance the current product line. Every little bit of performance counts. And our customers are kind of driving us in that direction.
“The other notable thing is that it’s a good indication of the health of our 14 nanometer manufacturing process because as yields improve, as the manufacturing process improves, you can drive more performance out of the process. This is a good indication of that. So if you think of Skylake being on the same manufacturing process I think it’s a real promise in terms of what you can expect.”
Perhaps worth mentioning is Wuischpard’s assertion of Intel’s commitment to HPC and the developer ecosystem around it. “[In] the code modernization program, to date we’ve actually touched 2.5 million developers, trained 400,000 directly, 200,000 indirectly, and the number is growing,” said Wuischpard.
























































