 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Perhaps ‘heresies’ is a bit strong, but HPC in the cloud, even for academics, is a fast-changing domain that’s increasingly governed by a new mindset, says Tim Carroll, head of ecosystem development and sales at Cycle Computing, an early pioneer in HPC cloud orchestration and provisioning software. The orthodoxy of the past – an emphatic focus on speeds and feeds, if you will – is being erased by changing researcher attitudes and the advancing capabilities of public (AWS, Microsoft, Google et al.) and private (Penguin, et al.) clouds.
Maybe this isn’t a revelation in enterprise settings where cost and time-to-market usually trump fascination with leading edge technology. True enough, agrees Carroll, but the maturing cloud infrastructure’s ability to handle the majority of science workflows – from simple Monte Carlo simulations to many demanding deep learning and GPU-accelerated workloads – is not only boosting enterprise HPC use, but also catching the attention of government and academic researchers. The job logjam (and hidden costs) when using institutional and NSF resources is prompting researchers to seek ways to avoid long queues, speed time-to-result, exercise closer control over their work and (potentially) trim costs, he says.
 If all of that sounds like a good marketing pitch, well Carroll is after all in sales. No matter, he is also a long-time industry veteran who has watched the cloud’s evolution for years and has played a role in mainstreaming HPC, notably including seven years at Dell (first as senior manager HPC and later executive director emerging enterprise), before joining Cycle in 2014.
If all of that sounds like a good marketing pitch, well Carroll is after all in sales. No matter, he is also a long-time industry veteran who has watched the cloud’s evolution for years and has played a role in mainstreaming HPC, notably including seven years at Dell (first as senior manager HPC and later executive director emerging enterprise), before joining Cycle in 2014.
As a provider of a software platform that links HPC users to clouds, Cycle has a front row seat on changing HPC cloud user demographics and attitudes as well as cloud provider strengths and weaknesses. In this interview with HPCwire, Carroll discusses market and technology dynamics shaping HPC use in the cloud. Technology is no longer the dominant driver, he says. See if you agree with Carroll’s survey of the changing cloud landscape.
HPCwire: The democratization of HPC has been bandied about for quite awhile with the cloud portrayed as a critical element. There’s also a fair amount of argument around how much of the new HPC really is HPC. Let’s start at the top. How is cloud changing HPC and why is there so much debate over it?
Tim Carroll: Running HPC in the cloud runs antithetical to how most people were brought up in what was essentially an infrastructure centric world. Most of what you did [with] HPC was improve your ability to break through performance ceilings or to handle corners cases that were not traditional enterprise problems; so it was an industry that prided itself on breakthrough performance and corner cases. That was the mindset.
What HPC in the cloud is saying is “All of the HPC people who for years have been saying how big this industry is going to grow were exactly right, but not $25B being spent by people worrying about limits and corner cases. A healthy part of the growth came from people who didn’t care about anything but getting their work done. Some people still care about the traditional definition, but I would say there are a whole bunch of people who don’t even define it, they just see a way to do things that they couldn’t do five years ago or ten years ago.
HPCwire: So are the new users not really running HPC workloads and has the HPC definition changed?
![]() Carroll: HPC workloads are always changing and perhaps the definition of the HPC along with it, but I think what’s really happening is the customer demographics are changing. It’s a customer demographic defined not by the software or the system, but the answer. When you ask someone in the research environment what their job is, they say I’m a geneticist or I am a computational chemist. Speak with an industrial engineer and they describe themselves as, no surprise, an industrial engineer. No one describes themselves as an “HPCer.” They all say I‘ve got a job to do and I’ve got to get it done in a certain amount of time at a certain price point. Their priority is the work.
Carroll: HPC workloads are always changing and perhaps the definition of the HPC along with it, but I think what’s really happening is the customer demographics are changing. It’s a customer demographic defined not by the software or the system, but the answer. When you ask someone in the research environment what their job is, they say I’m a geneticist or I am a computational chemist. Speak with an industrial engineer and they describe themselves as, no surprise, an industrial engineer. No one describes themselves as an “HPCer.” They all say I‘ve got a job to do and I’ve got to get it done in a certain amount of time at a certain price point. Their priority is the work.
I think what we did at Dell (now Dell EMC) was a huge step towards democratizing HPC. The attitude was that TOP500 was not the measure of success. Our goal very early on was to deliver more compute to academic researchers than another vendor. We did not strive for style points or the number of flops of any one particular system but we were determined to enable more scientists using more Dell flops than anybody else. That was our strategy and Dell was very successful with it.
HPCwire: That sounds a little too easy, as if they don’t need to know any or at least much computational technology. It’s clear systems vendors are racing to create easier-to-use machines and efforts like OpenHPC are making progress in creating a reference HPC stack. What do users need to know?
Carroll: Users and researchers absolutely need to understand the capabilities of their software and what can they actually do relative to the problem they need to solve, but they should not be required to know much more than that. For the last 20 years engineers and researchers defined the size of the problem they could tackle by the resources they knew they could get access. So if I know I have only got a 40-node cluster, what do I do? I start sizing my problems to fit on my cluster. Self-limiting happened unconsciously. But it doesn’t matter; the net effect was an artificial cap on growth.
So today, we’re not saying get rid of that 40-node cluster and make it bigger, but give people the choice to go bigger. Today, an engineer should be able to go to their boss and say, “I think I can deliver this research four months ahead of schedule if I have the ability to access 60 million core hours over a two week period and it’s going to cost – I am just making up numbers – $100,000.” Then the engineer and her boss go to the line of business and see if they want to come up with opex that will cover that and pull in their schedule by three months. Cloud gives people and organizations choice.
HPCwire: Stepping away from the enterprise for a moment, what’s the value proposition for academic and government researchers many of whom are very well versed indeed in HPC? Aren’t they simply likely to use internal resources or NSF cyberinfrastructure as opposed to the public cloud?
Carroll: The academic portion is really interesting because of how important the funding models are and the rules set by funding agencies. Because of that, it’s not always obvious if cloud is even an option. It also depends how the individual institutions charge for the other pieces [of a cloud deployment] that are being done. Often there is overhead and so it doesn’t matter how cost effective the cloud is because by the time it gets to the researcher, the landed cost to them is going to be prohibitive.
![]() As a result, cloud for academic HPC has been murky for the last couple of years. People aren’t ready to get there yet. Jetstream was a step in the right direction (NSF-funded initiative) but I’m wondering if anyone put themselves in the shoes of users, big and small, to judge how that experience compares to the public cloud providers.
As a result, cloud for academic HPC has been murky for the last couple of years. People aren’t ready to get there yet. Jetstream was a step in the right direction (NSF-funded initiative) but I’m wondering if anyone put themselves in the shoes of users, big and small, to judge how that experience compares to the public cloud providers.
The cloud thing is going to be here this year, and next year, and many years after. And guess what there’s also going to be a refresh cycle on internal hardware next year and a refresh cycle the year after. People are going to have to get more and more granular in their justification for deploying in their internal infrastructure versus using public cloud. And I am not saying that’s an either or proposition. But if the demand for compute is growing at 50 percent per year and budgets are going up a lot less, how are you going to fill that gap providing the researcher what they need to get their jobs done. What is the value proposition of longer job queues?
How can academia or the funding agencies not embrace what is arguably the fastest moving, innovating, cost-effective platform in order to fill the compute demand gap. Cloud is just one more tool, but if one views it as the Trojan Horse to get inside academia eliminate infrastructure, that is just wrong. Cloud is going to get its portion of the overall market where it makes sense for certain workloads, but not necessarily entire segments. Embrace it.
HPCwire: What’s been the Cycle experience in dealing with the academic community?
Carroll: I am still somewhat surprised at the amount of pushback I get from the academic community based on anecdotal information – the number of people who talk about what can and can’t be done although they haven’t tried. And there are so many people at the public cloud providers who would love to help them. Who knows, it may work out that they run the workload to see how much it would cost and the data says it is still twice as expensive as [internally]. That’s great, now we have a hard data point rather than something anecdotal.
One of the great things cloud will do for academia is to clear the decks for people who are truly building specialized infrastructure to solve really hard problems. What’s typically happened is that institutions had to support a breadth of researchers and were faced with the challenge solving diverse needs from a demanding community. The result was commodity clusters became the best middle ground; good enough for the middle but not really what the high and the low needed. In trying to serve a diverse market with a single architecture, few people got exactly what their research required. What you are going to see is that bell curve is going to get turned upside down and centers are going to reallocate capex to specialized systems and run high throughput workloads on public cloud.
I should note that the major cloud providers all have enormous respect for the HPC market segment and appreciate the fact that the average customer at the high end probably consumes ten to several hundred times the compute of a typical enterprise customer. They are all staffing up with very talented people and are eager to collaborate with academia to deliver solutions to them.
HPCwire: What will be the big driver of cloud computing in academic research centers, beyond NSF resources I mean?
Carroll: In the last ten years universities have become far more competitive as far as attracting the right researchers. It used to be that every new researcher got his or her cluster in a startup package and that model is flat-out unsustainable. But it’s a small enough community that researchers will quickly hear when the word is “ABC University has a great system and their researchers have no queue times, with no workload limits.” Who cares where the compute is performed, the university will have generated a reputation that if you’re a researcher there, you just get what you need to get the job done. Competition for talent is going to drive larger cloud adoption in academia.
It can also be powerful for individual researchers working on small projects. There’s a professor who reached out to us who wanted to include [cloud computing] in her class as part of her teaching and doing real science. She wanted to start the job when the semester began and have it finish by the time it ended. We said, how about if instead of taking four months like you thought, we knock it down to a couple of days. It is not grant based research but the cost fit within her discretionary budget. So she is not doing it as an academic exercise. This is a piece of science that would not be done were it not for this. And it is part of the teaching.
HPCwire: How do you characterize the cloud providers and how does Cycle fit in?
Carroll: We (Cycle) are a software platform that gives people the ability to run their workloads under their control on whichever cloud is best for them. It is not a SaaS model. Users can still protect their corporate IP, with their existing workload, and run multiple workloads for multiple users across multiple clouds from a single control point. We fit in with the cloud providers by helping them and their users do what they do best.
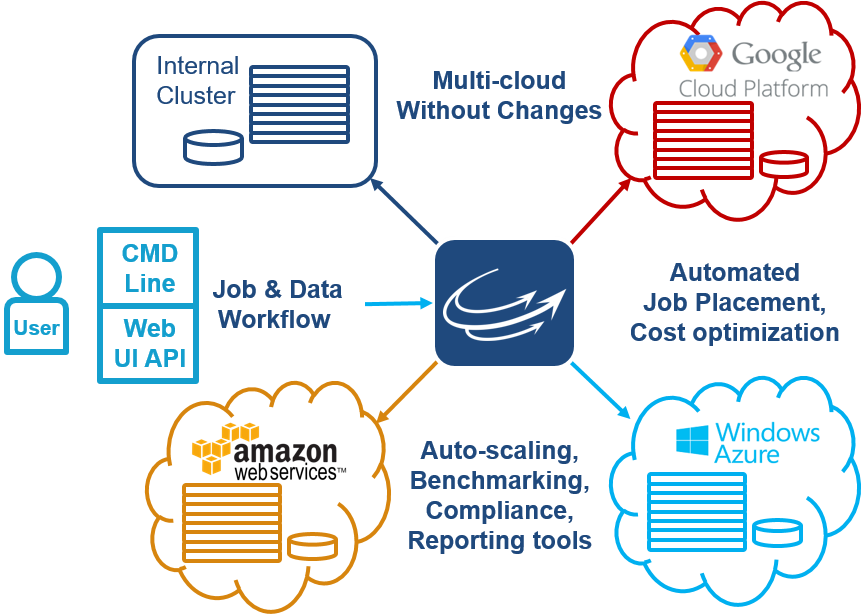
My experience is that customers are not looking for “cloud”; they have a problem and a deadline and they are just trying to figure out how can they run workloads securely and cost effectively that can’t get run today on their internal infrastructure. If I came and said it’s the public cloud, that would be ok. Private cloud, ok. If I said we would pull a trailer stuffed with servers to their building, they’d say ok. They will make their choice based on how much it costs; is it secure, how much work is required to get started and keep it running. It just so happens that the winner is increasingly public cloud.
Back to your earlier question about change within HPC. Cloud is not causing infrastructure to disappear, it is causing labels to disappear. Customers who have been early adopters are now on their sixth or eighth or tenth workload and are starting to get into workloads that are considered “traditional HPC.” But they did not label the first workloads as “non-HPC.” They just view them as compute intensive applications and don’t care whether it is called HPC or something else.


























































