 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Researchers from Baidu’s Silicon Valley AI Lab (SVAIL) have adapted a well-known HPC communication technique to boost the speed and scale of their neural network training and now they are sharing their implementation with the larger deep learning community.
The technique, a modified version of the OpenMPI algorithm “ring all-reduce,” is being used at Baidu to parallelize the training of their speech recognition model, Deep Speech 2, across many GPU nodes. The two pieces of software Baidu is announcing today are the baidu-allreduce C library, as well as a patch for TensorFlow, which allows people who have already modeled in TensorFlow to compile this new version and use it for parallelizing across many devices. The codes are available on GitHub.
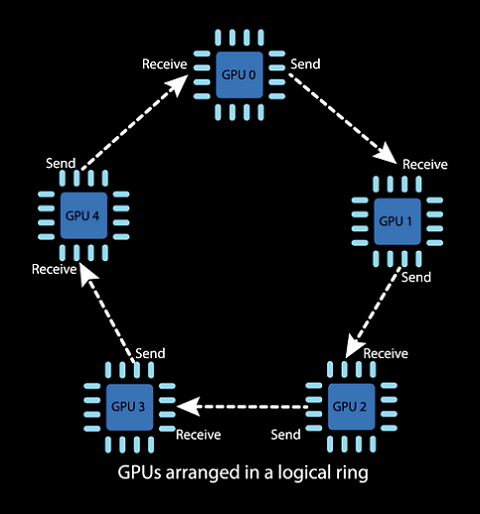
Baidu’s SVAIL team developed the approach about two years ago for their internal deep learning framework, named Gene and Majel (in tribute to the famous Star Trek creator and the actress who voiced the onboard computer interfaces for the series). The technique is commonplace in HPC circles, but underused within artificial intelligence and deep learning, according to Baidu.
Many of the researchers in the SVAIL group had come from the high performance computing space and recognized the competitive edge it offered.
“The algorithm is actually part of OpenMPI, but the OpenMPI implementation is not as fast,” comments Baidu Research Scientist Shubho Sengupta. “So the way we stumbled upon it was we started using OpenMPI for doing training and we realized it was not scaling to the extent that we want it to scale. I started digging through the OpenMPI source, found the algorithm, saw that it’s not very efficient, and reimplemented it.”
The SVAIL researchers wrote their own implementation of the ring algorithm for higher performance and better stability. The key distinction from the OpenMPI version is that the SVAIL implementation avoids extraneous copies between the CPU and GPU.
Explains Sengupta, “Once OpenMPI does the communication of these matrices, if the matrices are in GPU memory, it actually copies to CPU memory to do the reduction part of it – that’s actually quite wasteful. You don’t really need to do a copy, you could just write a small kernel that does the reduction in GPU memory space itself. And this especially helps when you are doing all-reduce within a node and all the GPUs are within a PCI root complex, then it doesn’t do any of the copies actually – it can just do everything in GPU memory space. This very simple idea of eliminating this copy resulted in this speedup in scaling over OpenMPI’s own implementation.”
Employing this algorithm along with SVAIL’s focus on fast networking (InfiniBand) and careful hardware-software codesign has enabled the team to get linear GPU scaling up to 128 GPUs, an achievement that was detailed in their December 2015 paper, “Deep Speech 2: End-to-End Speech Recognition in English and Mandarin.”
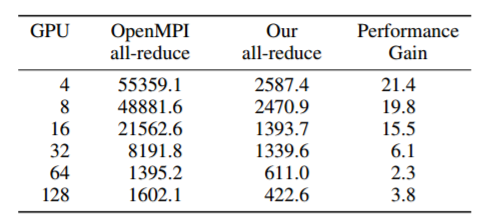
With their internal implementation of ring all-reduce, the team achieves between a 2.3-21.4X speedup over OpenMPI (version 1.8.5) depending on the number of GPUs.
Sengupta notes that their implementation is fastest for a small number of GPUs. “At 8 GPUs it’s about 20x faster, then as you increase the number of GPUs, it drops because now you actually have to copy data to the CPU to send across the network. But for the internal framework, we can scale all the way up to 128 GPUs and get linear scaling.”
Sengupta’s teammate Baidu Research Scientist Andrew Gibiansky says similar benefits can now be seen with TensorFlow: “In terms of the TensorFlow implementation, we get the same linear scaling path past eight. In terms of a comparison with running on a single GPU, it ends up being about 31x faster at 40 GPUs.”
After the Deep Speech 2 paper was published, the SVAIL team began getting requests from the community who wanted to know more about the implementation. Given that the algorithm is pretty tightly coupled to SVAIL’s proprietary deep learning framework, they needed to come up with a different way to release it, so they created two new implementations, one specifically for TensorFlow and one that is more general.
Gibiansky, who led the work on the TensorFlow patch, describes their multi-pronged approach to disseminating the information. “You can read the blog post [for a thorough technical explanation] and figure it out. If you’re using TensorFlow, you can use our modification to train your own models with this. And if you’re a deep learning author, you can look at our C library and integrate that. The goal is really to take this idea we’ve found to be really successful internally and try to start spreading it so that other people can also take advantage of it.”
Sengupta shares an interesting perspective on the opportunities to be mined for deep learning within HPC.
“With MPI – people [in deep learning] think that it is this old technology, that it is not relevant, but I think because of our work we have shown that you can build very fast collectives using MPI and that allows you to do synchronous gradient descent which converges faster, gives you deterministic results and you don’t need to do asynchronous gradient descent with parameter servers which was the dominant way of doing this when we first started,” says Sengupta.
As for the reduced-copy approach propagating back to MPI, Gibiansky notes that if you look at some of the other MPI implementations, they’re slowly moving their collectives to GPU versions. “MVPICH recently introduced an all-gather that doesn’t end up copying to CPU – so OpenMPI will probably get there, it just might take a while. Potentially giving this a little more visibility, we can spur that on.”
“There’s a lot of interest now in collectives and one thing we also realized is the all-reduce operation used in traditional HPC setups, it actually transfers data that’s actually not very large,” Sengupta adds. “What it usually does, when I talk to HPC people, it’s trying to figure out the status of something across a bunch of machines – while in deep learning we are transferring these large matrices – like 2048×2048, essentially 4 million 32-bit floating points. For the traditional HPC community, this is a very atypical input for all-reduce. The traditional HPC community does not actually use all-reduce with really large data sizes. I think with deep learning, more and more people are realizing that collective operations for really large matrices is also very important.”
A detailed explanation of ring all-reduce and Baidu’s GPU implementation is covered in this technical blog post, published today by Baidu Research. A variant of the technique is also used to provide high-performance node-local scaling for PaddlePaddle, the company’s open source deep learning framework.

























































