 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Knowing that the jump to exascale will require novel architectural approaches capable of delivering dramatic efficiency and performance gains, researchers around the world are hard at work on next-generation HPC systems.
In Europe, the DEEP project has successfully built a next-generation heterogeneous architecture based on an innovative “cluster-booster” approach. The new architecture can dynamically assign individual code parts in a simulation to different hardware components based on which component can deliver the highest computational efficiency. It also provides a foundation for a modular type of supercomputing where a variety of top-level system components, such as a memory module or a data analytics module for example, could be swapped in and out based on workload characteristics. Recently, Norbert Eicker, head of the Cluster Computing research group at Jülich Supercomputing Centre (JSC), explained how the DEEP and DEEP-ER projects are advancing the idea of “modular supercomputing” in pursuit of exascale performance.
Why go DEEP?
Eicker says that the use of vectorization or multi-core processors have become the two main strategies for acceleration. He noted that the main advantages in general purpose multi-core processors include high single-thread performance due to relatively high frequency along with their ability to do out-of-order processing. Their downsides include limited energy efficiency and a higher cost per FLOP. Accelerators, such as the Intel Xeon Phi coprocessor or GPUs, on the other hand are more energy efficient but harder to program.
Given the different characteristics of general purpose processors and accelerators, it was only a matter for time before researchers began looking for ways to integrate different types of compute modules into an overall HPC system. Eicker said that most efforts have involved building heterogeneous clusters wherein standard cluster nodes are connected using a fabric and then accelerators are attached to each cluster node.
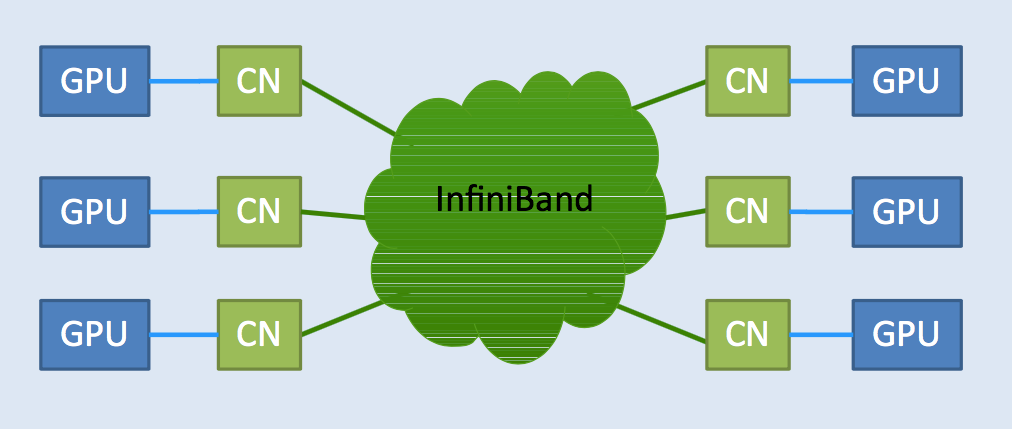
Per Eicker, this heterogeneous approach has drawbacks, including the need for static assignment of accelerators to CPUs. Since some applications benefit greatly from accelerators and others not at all, getting the ratio of CPUs to accelerators right is tricky and inevitably leads to inefficiencies. Eicker explained that the idea behind the DEEP project was to combine compute resources into a common fabric and make the accelerating resources more autonomous. The goal was to not only enable dynamic assignments between cluster nodes and the accelerator, but also to enable the accelerators to run a kind of MPI so the system could offload more complex kernels to the accelerators rather than needing to always rely on the CPU.
The building blocks of a successful prototype
Work on the prototype Dynamical Exascale Entry Platform (DEEP) system began in 2011, and was mostly finalized toward the end of 2015. It took the combined efforts of 20 partners to complete the European Commission funded project. The 500 TFLOP/s DEEP prototype system includes a “cluster” component with general-purpose Intel Xeon processors and a “booster” component with Intel Xeon Phi coprocessors along with a software stack capable of dynamically separating code parts in a simulation based on concurrency levels and sending them to the appropriate hardware component. The University of Heidelberg developed the fabric, which has been commercialized by EXTOLL and dubbed the EXTOLL 3D Torus Network.
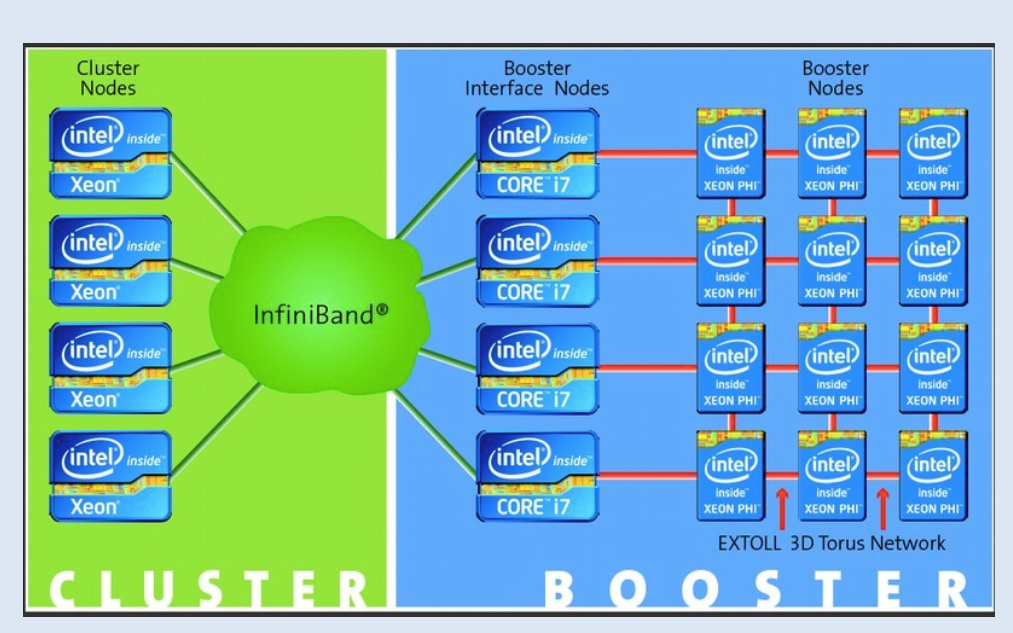
Given the unusual architecture, the project team knew it would need to modify and test applications from a variety of HPC fields on the DEEP system to prove its viability. The team analyzed each selected application to determine which parts would run better on the cluster and which would run better on the booster, and modified the applications accordingly. One example is a climate application from Cyprus Institute. The standard climate model part of the application runs on the cluster side while an atmospheric chemical simulation runs on the booster side, with both sides interacting with each other from time to time to exchange data.
The new software architecture
One of the most important developments of the DEEP project is a software architecture that includes new communication protocols for transferring data between network technologies, programming model extensions and other important advancements.

While left- and right-hand sides of the architecture in figure 3 are identical to the standard MPI-based software-stacks of most present day HPC architectures, the components in the middle add some important new capabilities. Eicker explained that in the DEEP software architecture, the main part of applications and less scalable code are only run on the cluster nodes and everything starts on the cluster side. What’s different is that the cluster part of the application can collectively start a crowd of MPI-processes on the right-hand side using a global MPI.
The spawn for the booster is a collective operation of cluster processes that creates an inter-communicator containing all parents on one side and all children on the other. For example, the MPI_COMM_WORLD or a subset of processes on the cluster side, collectively called the MPI_Comm_spawn function, can create a new MPI_COMM WORLD on the booster side that is capable of standard MPI communication. Once started, the processes on the booster side can communicate amongst each other and exchange messages, making it possible to offload complex kernels to the booster.
Using MPI to bridge between the different fabrics in the cluster and booster may seem like it would significantly complicate the lives of application developers. However, Barcelona Supercomputing Center invented what is basically a source-to-source compiler, called the OmpSs Offload Abstraction compiler that does much of the work. Developers see a familiar looking cluster side with an Infiniband-based MPI and a booster side with an EXTOLL-based MPI. Their job is to annotate the code to tell the compiler which parts should run on the cluster versus the booster. The OmpSs compiler introduces the MPI_Comm_spawn call and the other required communication calls for sharing data between the two code parts.
Eicker explained that the flexible DEEP approach has many advantages, including options for multiple operational modes that enable much more efficient use of system resources. Beyond the specialized symmetric mode described above, the booster can be used discretely, or as a pool of accelerators. He used applications that could scale on the Blue Gene system as an example, noting they be run entirely on the booster side with no cluster interaction.
From DEEP to DEEP-ER
Plans for the DEEP-ER (Dynamical Exascale Entry Platform – Extended Reach) phase include updating the booster to include the latest generation of Intel Xeon Phi processors. The team is also exploring how on-node Non-Volatile Memory (NVM), network attached memory and a simplified interface can improve the overall system capabilities.

Eicker said that since Xeon Phi processors are self-booting, the upgrade will make the hardware implementation easier. The team also significantly simplified the interface by using the EXTOLL fabric throughout the entire system. The global use of the EXTOLL fabric enabled the team to eliminate the booster interface nodes and the DEEP cluster-booster protocol. The DEEP-ER system will use a standard EXTOLL protocol running the two types of nodes. The EXTOLL interconnect also enables the system to take advantage of the network attached memory.
One of the main objectives of the DEEP-ER project is to explore scalable I/O. To that end, the project team is investigating the integration of different storage types, starting from the disks using NVM while also making use of the network attached memory. Eicker said the team is using the BeeGFS file system and extensions that enable smart caching to local NVMe devices in the common namespace of the file system to help improve performance as well as SIONlib, a scalable I/O library developed by JSC for parallel access to task-local files, to enable more efficient local tasking of I/O. Exascale10 I/O software from Seagate also sits on top of the BeeGFS file system, enabling the MPI I/O to make use of the file system cache extensions.
Beyond I/O, the DEEP-ER project is also exploring how to improve resiliency. Eicker noted that because the offloaded parts of programs are stateless in the DEEP approach, it’s possible to improve the overall resiliency of the software and make functions like checkpoint restart a lot more efficient than standard approaches.
Toward modular supercomputing
Each phase of the DEEP project is an important step forward toward modular supercomputing. Eicker said that the DEEP cluster-booster concept showed that it’s possible to integrate heterogeneous systems in new ways. With DEEP-ER, the combination of the NAM and network attached storage add what is essentially a memory booster module. Moving forward, there are all kinds of possibilities for new modules, according to Eicker. He mentioned an analytics module that might look like a cluster, but include more memory or different types of processors, or a module that acts as a graphics cluster for online visualization.
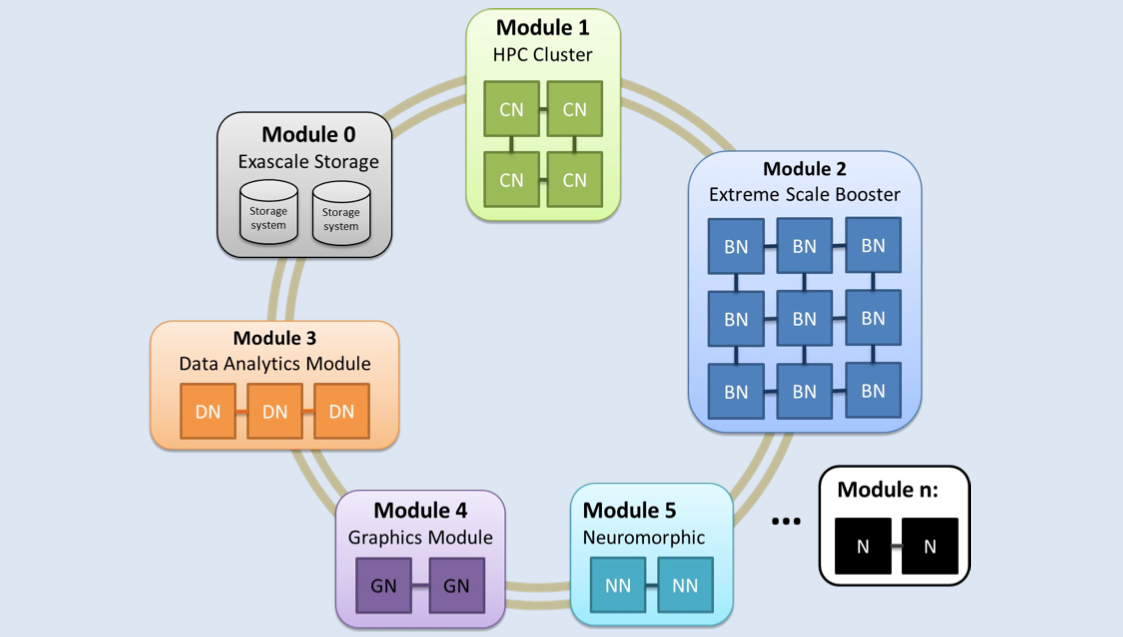
The ultimate goal of the DEEP project is to build a flexible modular supercomputer that allows users to organize applications for efficient use of the various system modules. Eicker said that the DEEP-ER team hopes to extend its JURECA cluster with the next-generation Xeon Phi processor-based booster. Then the team will begin exploring new possibilities for the system, which could include adding new modules, such as a graphics, storage and data analytics modules. The next steps could even include a collaboration with the Human Brain Project on neuromorphic computing. And these ideas are only the beginning. The DEEP approach could enable scientists to dream up new modules for tackling their specific challenges. Eicker acknowledges that there is much work to be done, but he believes the co-design approach used by the DEEP team will continue to drive significant steps forward.
Watch a short video capturing highlights of Eicker’s presentation.
About the Author
Sean Thielen, the founder and owner of Sprocket Copy, is a freelance writer from Portland, Oregon who specializes in high-tech subject matter.


























































