 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
When it comes to the true performance of the latest silicon, every end user knows that the best processor is the one that works best for their application. An interim step between touted “peak” specs and real-world performance is where benchmarking comes in as a useful exercise that can reveal new insights.
With Nvidia’s Pascal-based Tesla P100 GPU now deployed in several Top500 supercomputers and hitting its cloud stride, many end users have already made the jump from the previous Kepler-architecture or are considering it. To provide guidance to high-performance computing professionals in the financial services sector, the HPC software specialists at Xcelerit conducted a comparison study of these two accelerators using selected applications from their in-house Xcelerit Quant Benchmark Suite.
The Pascal-based P100 provides 1.6x more double-precision flops than the Kepler-generation K80: 4.7 teraflops for the PCIe-based P100 versus 2.91 teraflops for the K80. Further, “P100’s stacked memory features 3x the memory bandwidth of the K80, an important factor for memory-intensive applications,” says Xcelerit. NVLink-connected P100s, although not used for this benchmarking study, offer a 2-3x improvement in GPU-GPU communication (bandwidth) compared to PCIe.
“Beyond compute instructions, many other factors influence performance, such as memory and cache latencies, thread synchronisation, instruction-level parallelism, GPU occupancy, and branch divergance,” the team writes.
The benchmarking relied on selected applications form the Xcelerit Quant Benchmark Suite, a representative set of applications widely used in quantitative finance. The hand-tuned set includes LIBOR Swaption Portfolio (Monte-Carlo), American Options (Binomial Lattice), European Options (Closed form), and Barrier Options (Monte-Carlo).
The test machine featured:
CPU: 2 sockets, Haswell (Intel Xeon E5-2698 v3)
GPU: NVIDIA Tesla K80 and NVIDIA Tesla P100 (ECC on)
OS: RedHat Enterprise Linux 7.2 (64bit)
RAM: 128GB (K80 system) and 256GB (P100 system)
CUDA Version: 8.0
CPU Backend Compiler: GCC 4.8
GPU clock: maximum boost
Precision: double performance
The full algorithm execution time was recorded from inputs to outputs, including setup of the GPU and data transfers. The results indicate each GPU’s speedup over sequential implementation on a single CPU core.
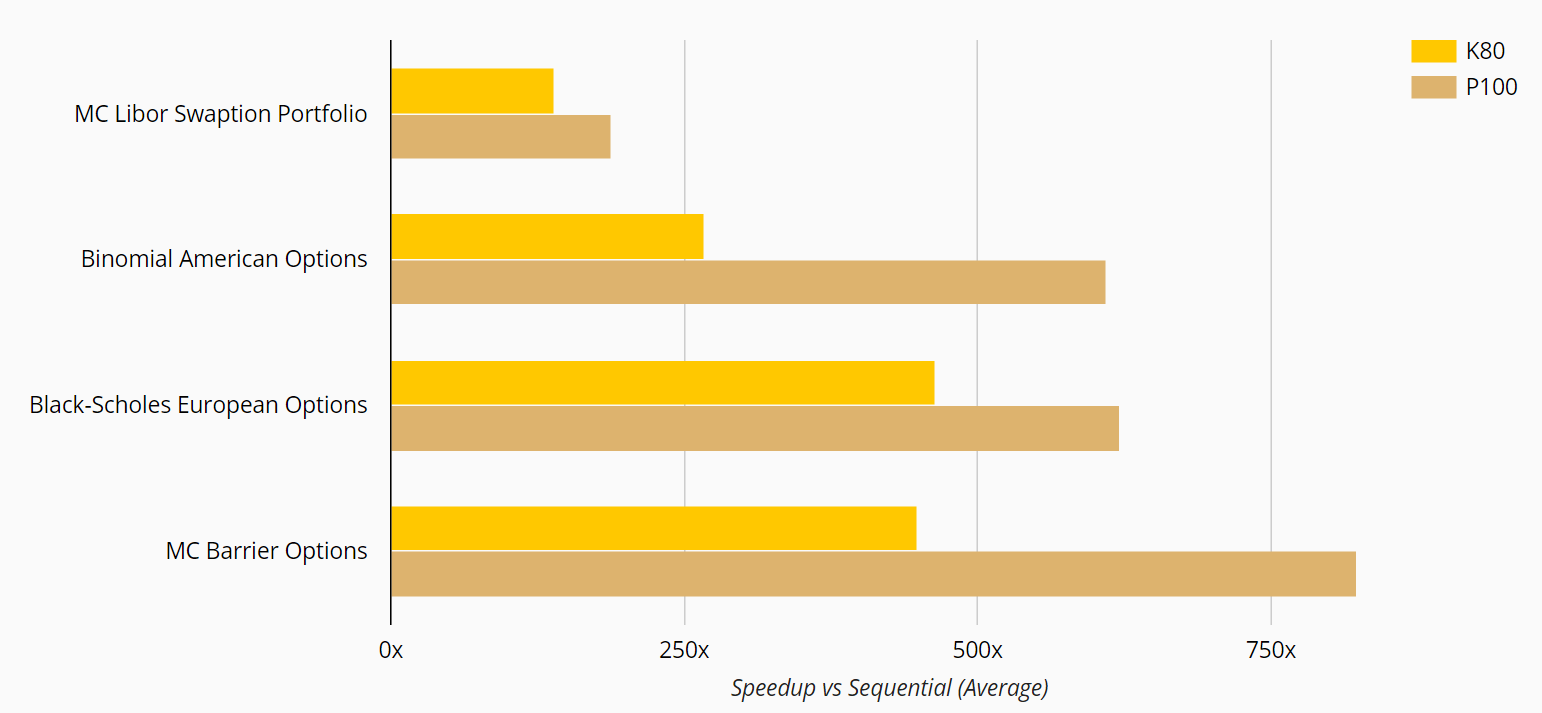
On average, the P100 delivered a 1.7X boost overall with application speedups ranging from 1.3x to 2.3x. “This high variation of the speedup across applications can be explained by the different application characteristics, in particular the relation of compute instructions to memory access operations,” writes Xcelerit.
The most compute-heavy applications with the fewest memory accesses — the LIBOR swaption portfolio and Black-Scholes option pricers — saw the least speedup; while the memory-intensive Binomial American option pricer had the biggest gain.
See the complete study here.

























































