 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
As its mission, the high performance computing center for the U.S. Department of Energy Office of Science, NERSC (the National Energy Research Supercomputer Center), supports a broad spectrum of forefront scientific research across diverse areas that includes climate, material science, chemistry, fusion energy, high-energy physics and many others.
![]() “We have about 6,000 users – with 700 different codes – who are doing research across all fields of interest to the Office of Science and we support them all,” said Richard Gerber, NERSC HPC department head and senior science advisor. “That means that all our users and all their codes have to run, and run well, on our systems. One of our challenges is to get our entire workload to run efficiently and effectively on next-generation supercomputers. This goal has become known as ‘Many core for the masses,’ and that’s what we will be spending a lot of time working on in the upcoming year.”
“We have about 6,000 users – with 700 different codes – who are doing research across all fields of interest to the Office of Science and we support them all,” said Richard Gerber, NERSC HPC department head and senior science advisor. “That means that all our users and all their codes have to run, and run well, on our systems. One of our challenges is to get our entire workload to run efficiently and effectively on next-generation supercomputers. This goal has become known as ‘Many core for the masses,’ and that’s what we will be spending a lot of time working on in the upcoming year.”
By definition then, many-cores for the masses at NERSC includes getting all the Office of Science applications running on NERSC’s new Cori supercomputer with 9,300 Intel Xeon Phi processors (formerly known as Knights Landing or KNL) and 1,900 Intel Xeon compute nodes.
“Cori is NERSC’s first manycore system and is on the path to exascale,” Gerber continued. “In particular it’s the first system where single-thread performance may be lower than single-thread performance on the previous system. This presents a real challenge for some users.” The Cori supercomputer also presents a deeper memory/storage hierarchy from the Intel Xeon Phi processor on-package MCDRAM, to DDR, to a burst buffer flash storage layer and all the way through to the Lustre file system.
In preparing for Cori over the past two years, the NERSC team launched NESAP (the NERSC Exascale Science Applications Program), which is a collaborative effort where NERSC partners with code teams, library and tools developers, Intel, Cray and the HPC community to prepare for the Cori many-core architecture. Twenty projects were selected for NESAP based on computational and scientific reviews by NERSC and other DOE staff. These projects represent about half of the runtime hours utilized on the NERSC supercomputers.
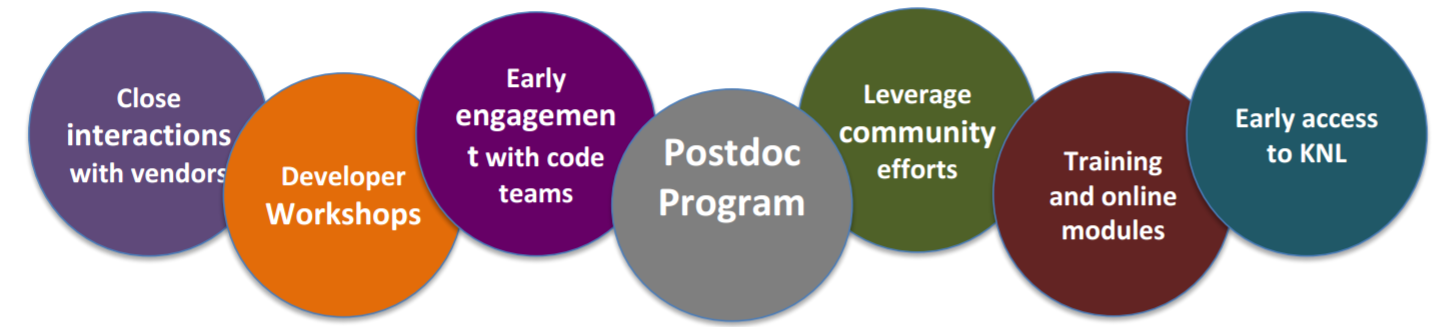
The idea is to provide training for staff and postdocs and apply the lessons learned to the broad NERSC user community. These lessons are also widely applicable to the general Intel Xeon and Intel Xeon Phi processors user community. “As we learn things, a big part of our strategy is to take that knowledge and spread it out to the community – the community of our 6,000 users but also the worldwide community,” Gerber pointed out in the NERSC talk at the recent Intel HPC Developer conference, Many Cores for the Masses: Lessons Learned from Application Readiness Efforts at NERSC for the Knights Landing Based Cori System.
Jack Deslippe, who leads the NESAP effort and the NERSC Application Performance Group, reiterated the point that, “Cori represents the first machine that NERSC has procured where doing nothing means that a user’s code can actually run slower on the new system node-per-node.” That is why the NESAP program is an “all hands on deck” effort to work at a much deeper level with user code than the NERSC has done before. “This effort has touched every group at NERSC,” he said, “and has created a level of collaboration with Cray and Intel engineers on apps that has never occurred at the center before.”
Optimization for the Masses
When talking to scientists and users, the NERSC team likens the optimization process to that of an ant farm — an analogy that has become popular, no doubt, due to its silliness. Deslippe noted in an SC16 talk “This sort of out-of-the-box thinking that gives you a promotion at Berkeley,” which garnered a hearty laugh from the audience. The truth as reflected by the ant hill model (shown below) is that optimizing code is not always a straightforward process. In particular, Deslippe observed that, “it is easy to get lost in the weeds” – especially with Intel Xeon Phi processors due to the wealth of new architectural features on these devices that a programmer might want to target.
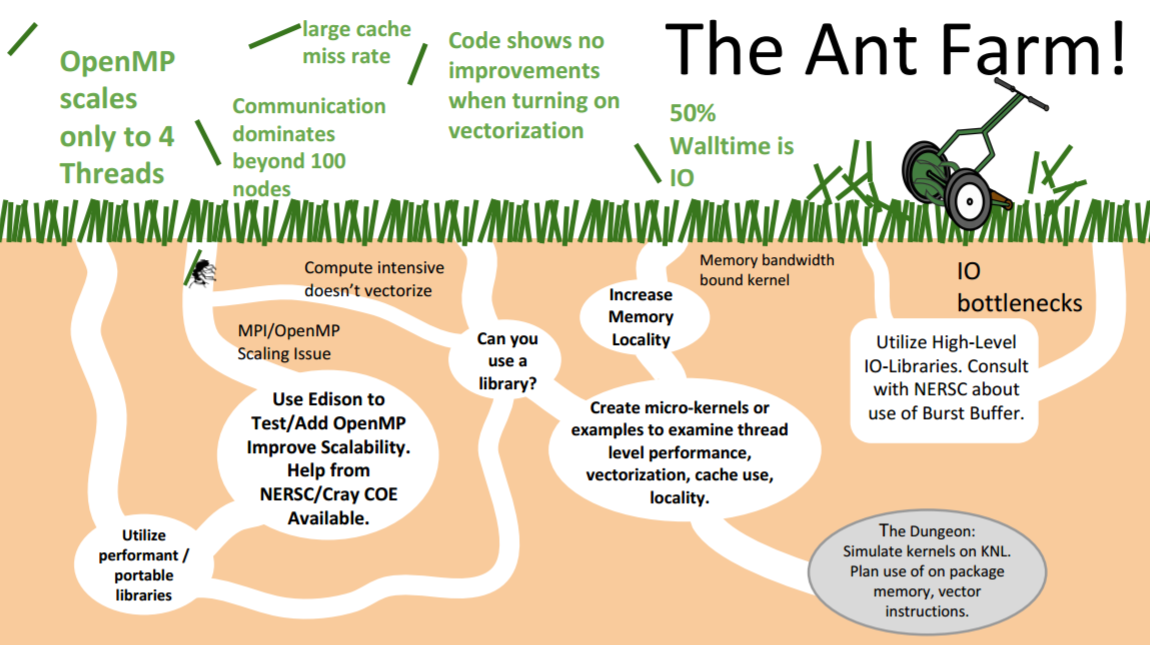
Profiling your code is, “like a lawnmower that constantly finds and knocks down the next tallest blade of grass” he said, an analogy to optimizing the next section of code that consumes the greatest amount of runtime. The programmers then take the code section away for investigation. In order to bring order to the ant farm, NERSC has employed the use of the roofline model, which tells the programmer not only how much they are improving the code according to an absolute measure of performance (shown on the y-axis below), but it also tells them which architectural features might help. The positions of code performance relative to the ceilings in the model show where the potential performance gains can be achieved be it via vectorization (AVX), code restructuring via Instruction Level Parallelism (ILP) or focusing on efficient use of the High Bandwidth memory (HBM).

The ability to easily collect accurate roofline performance data is the result of collaboration between Intel and NERSC staff. (See http://www.nersc.gov/users/application-performance/measuring-arithmetic-intensity for more information.) The NERSC team is actively working with Intel on the co-design of performance tools in the Intel Advisor utility that now includes the roofline model. Early access can be found here.
Early CORI Intel Xeon Phi processor single node results
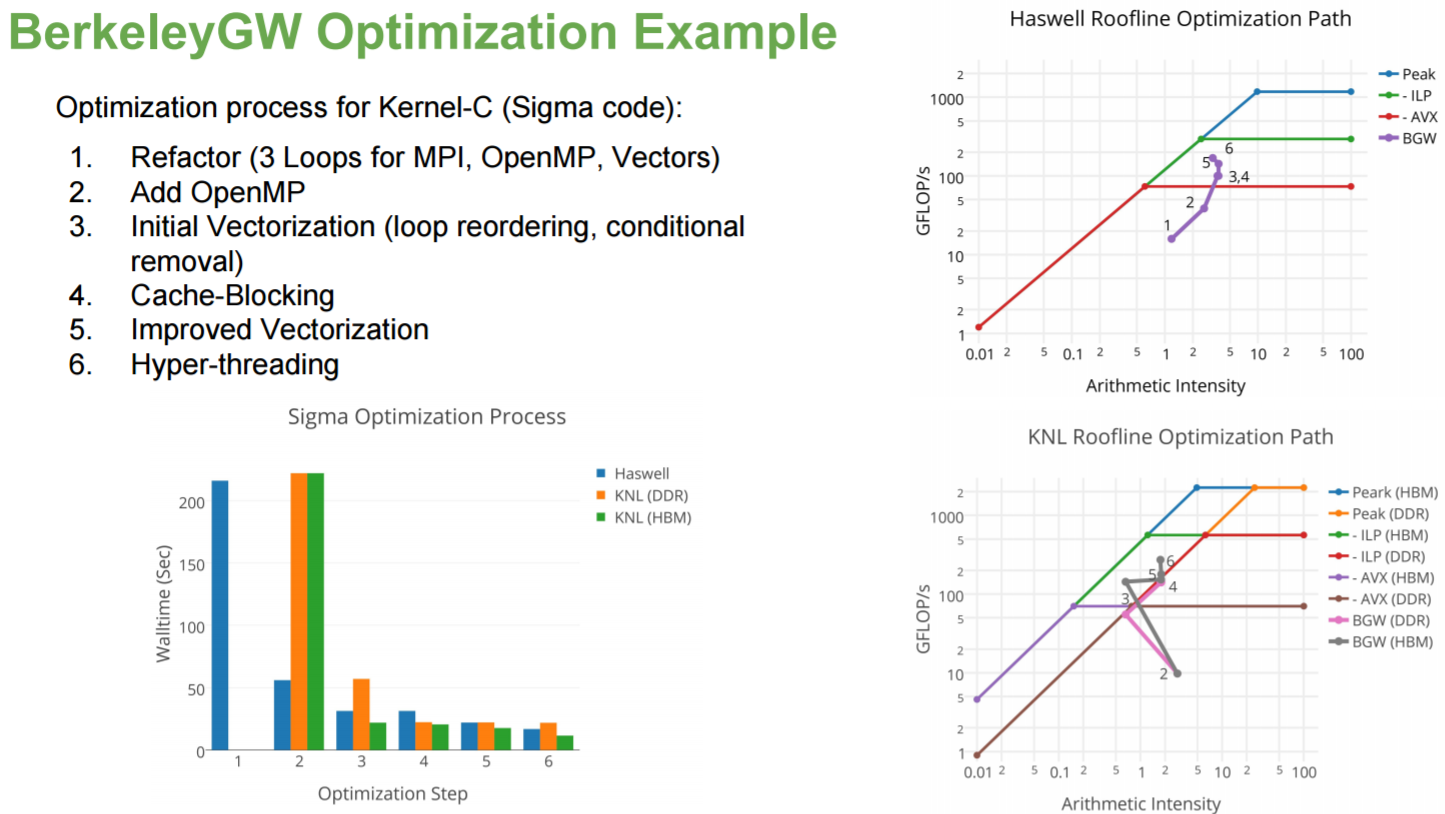
Early single Intel Xeon Phi processor node results show excellent speedups on the NESAP codes with a maximum speedup of 13x for the BerkeleyGW package, a set of computer codes written at Berkeley that calculate the quasiparticle properties and optical responses for a large variety of materials.
The optimization process of one of the kernels (Kernel-C) utilized the roofline model and the performance impact of six optimization steps is shown below. Note that the optimization process also delivered significant performance increases on the Intel Xeon processors as well.
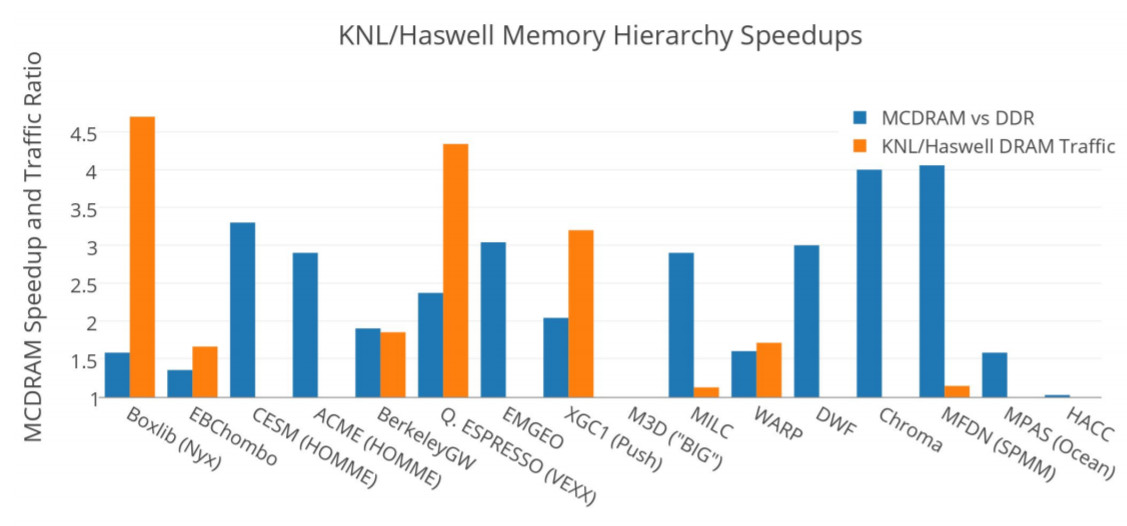
Overall the NESAP optimization process delivered significant increases in performance on both the Intel Xeon and Intel Xeon Phi processor Cori computational nodes. Intel Xeon processor results are shown in orange below and the Intel Xeon Phi processor results are shown in blue. In most cases, the speedup was greater on Intel Xeon Phi processors than on the Intel Xeon processors. Doug Doeffler noted that, “Haswell tends to be more forgiving of unoptimized code.” The Boxlib code is one exception because it started as a bandwidth limited code that fit into the Intel Xeon Phi processor MCDRAM memory.
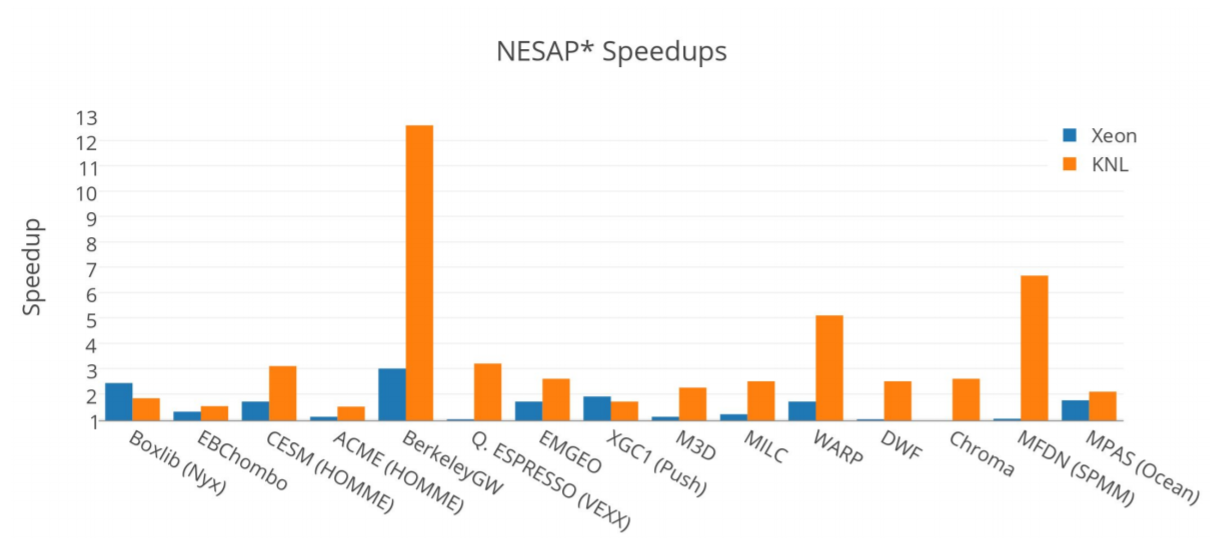
In general, the MCDRAM system benefitted most of the NESAP applications.
Early Cori Scaling Studies
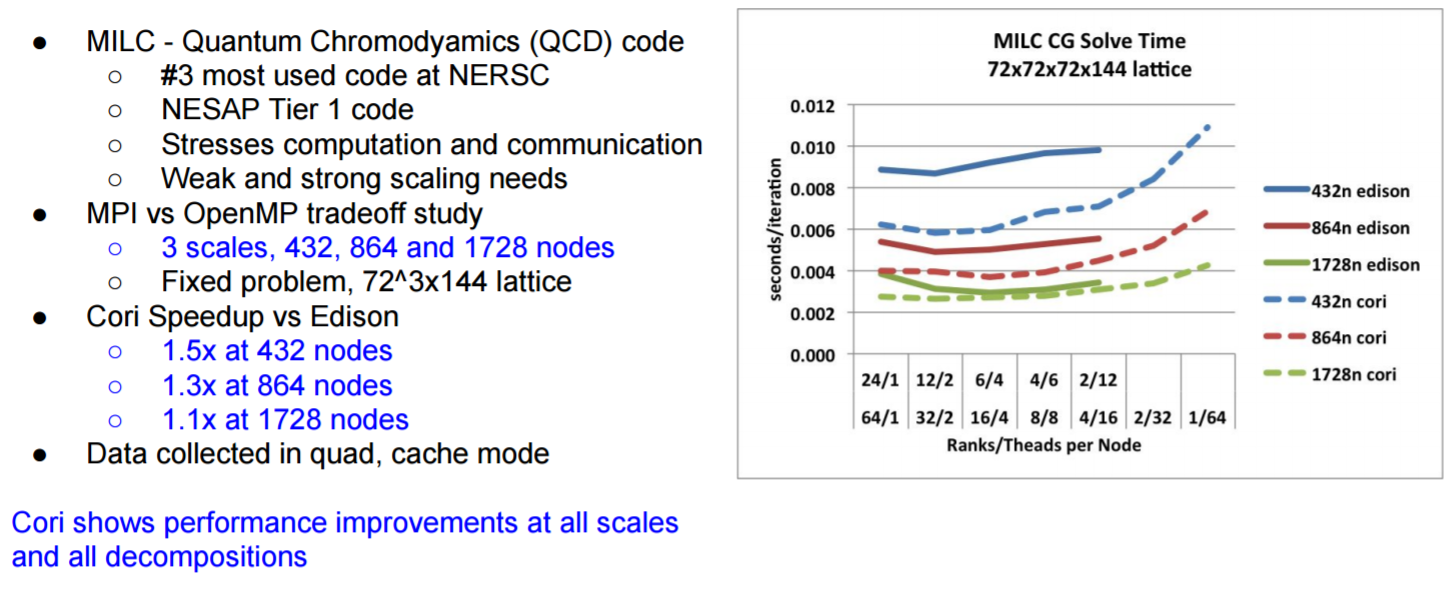
Cori contains a large number of computational nodes, so scaling is a key factor in efficiently utilizing the machine. Of concern is the observation that the Intel Xeon Phi computational nodes deliver roughly one-third the sequential performance of a Haswell/Broadwell Xeon core. However this lower performance core must support both the application and much of the communication stack and processing of the MPI communications calls.
Summarized in the following graphic, NERSC has found that Cori shows performance improvements at all scales and decompositions.
Summary
In a majority of the reporting NESAP codes and kernels, single node runs on the Intel Xeon Phi nodes outperformed single node runs on the Intel Xeon processor (Haswell) nodes. However, the superior Intel Xeon Phi processor performance only happened after optimization guided by the roofline model.
About the Author
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He was also the editor of Parallel Programming with OpenACC. Rob can be reached at [email protected].


























































