 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Computational science is often not the strongest suit for life scientists and that’s been a factor in the relatively modest adoption of the cloud for genomics research. Last week Amazon took a step towards easing the path for bioscience researchers with a series of blogs explaining how to set up genomics workflows on AWS.
The series of four blogs by Aaron Friedman, healthcare and life sciences architect, and Angel Pizarro, scientific computing technical business development manager at AWS, are reasonably detailed and includes samples of code as well as descriptions of various workflows. The first blog covers the general architecture and highlights three common layers in a batch workflow – job, batch, and workflow.
“At its core, a genomics pipeline is similar to a series of Extract Transform and Load (ETL) steps that convert raw files from a DNA sequencer to a list of variants for one or more individuals. Each step extracts a set of input files from a data source, processes them as a compute-intensive workload (transform), and then loads the output into another location for subsequent storage or analysis,” write Friedman and Pizarro in the introductory first blog.
“These steps are often chained together to build a flexible genomics processing workflow. The files can then be used for downstream analysis, such as population scale analytics with Amazon Athena or Spark on Amazon EMR. These ETL processes can be represented as individual batch steps in an overall workflow.”
As described by Amazon the remaining three blogs tackle:
- Part 2 covers the job layer. We demonstrate how you can package bioinformatics applications in Docker containers, and discuss best practices when developing these containers for use in a multitenant batch environment.
- Part 3 dives deep into the batch, or data processing layer. We discuss common considerations for deploying Docker containers to be used in batch analysis as well as demonstrate how you can use AWS Batch for a scalable and elastic batch engine.
- Part 4 dives into workflow layer orchestration. We show how you might architect that layer with AWS services. You take the components built in parts 2 and 3 and combine them into an entire secondary analysis workflow. This workflow manages dependencies as well as continually checking the progress of existing jobs. We conclude by running a secondary analysis end-to-end for under $1 and discuss some extensions you can build on top of this core workflow.
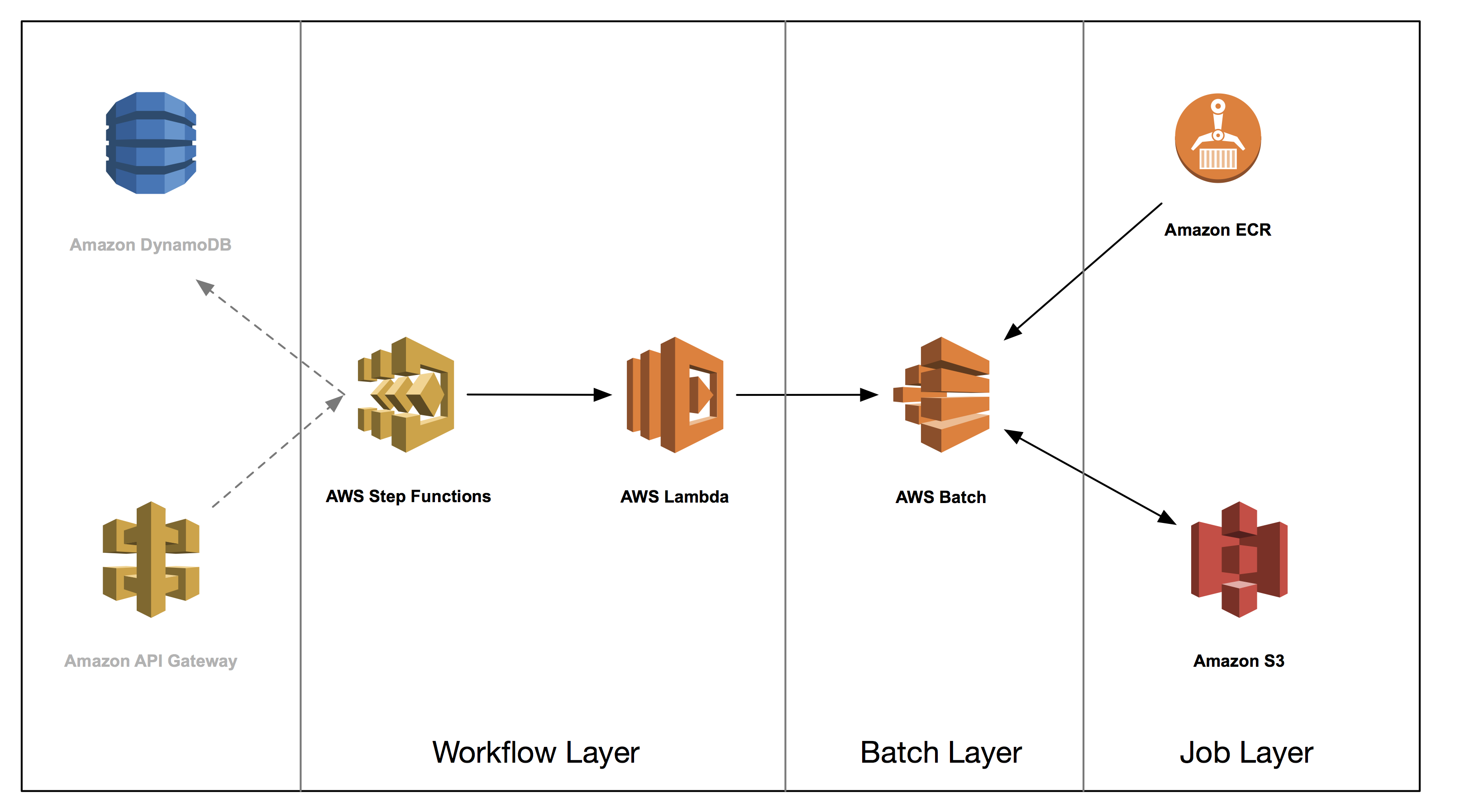
Interestingly, AWS argues its approach to batch processing can be generalized to any type of batch workflow, such as post-trade analytics or fraud surveillance in financial services, or rendering and transcoding in media and entertainment.
Amazon claims the genomics workflow blogs will users show how to optimize Amazon EC2 Spot Instances use and save up to 90% off of traditional On-Demand prices. A fifth blog introduces Amazon life science partners who can facilitate implementing genomics workflows and singles out: BioTeam; DNAnexus; Illumina; Seven Bridges.


























































