 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Intel, the subject of much speculation regarding the delayed, rewritten or potentially canceled “Aurora” contract (the Argonne Lab part of the CORAL “pre-exascale” award), parsed out additional information about the upcoming deep learning-targeted Knights Mill processor during ISC 2017 in Frankfurt this week. The Knights Mill will get at least a 2-4X speedup for deep learning workloads thanks to new instructions that provide optimizations for single, half and quarter-precision.
When Intel announced Knights Mill (KNM), the AI-focused Knights Landing (KNL) derivative, last August, the company didn’t offer much in the way of details. It would be self-hosted like Knights Landing, said Intel at the time, but would have AI-targeted design elements such as enhanced variable precision compute and high capacity memory. As Intel gets closer to its target production date, Q4 of this year, it is slowly pulling back the covers on Knights Mill. Attendees of HP-CAST were briefed ahead of ISC and a detailed presentation was delivered at the Inter-experimental Machine Learning (IML) Working Group workshop in March.
According to IML presentation slides, the addition of Quad Fused Multiply Add (QFMA) instructions enable a 2x performance gain for Knights Mill over Knights Landing on 32-bit floating point operations. Variable precision instructions enable higher throughput for machine learning tasks. With Quad Virtual Neural Network Instruction (QVNNI), 16-bit INT operations are four times faster per clock than KNL FP32, claims Intel. And thanks to INT32 accumulated output, Intel says users can achieve “similar accuracy to single-precision.”
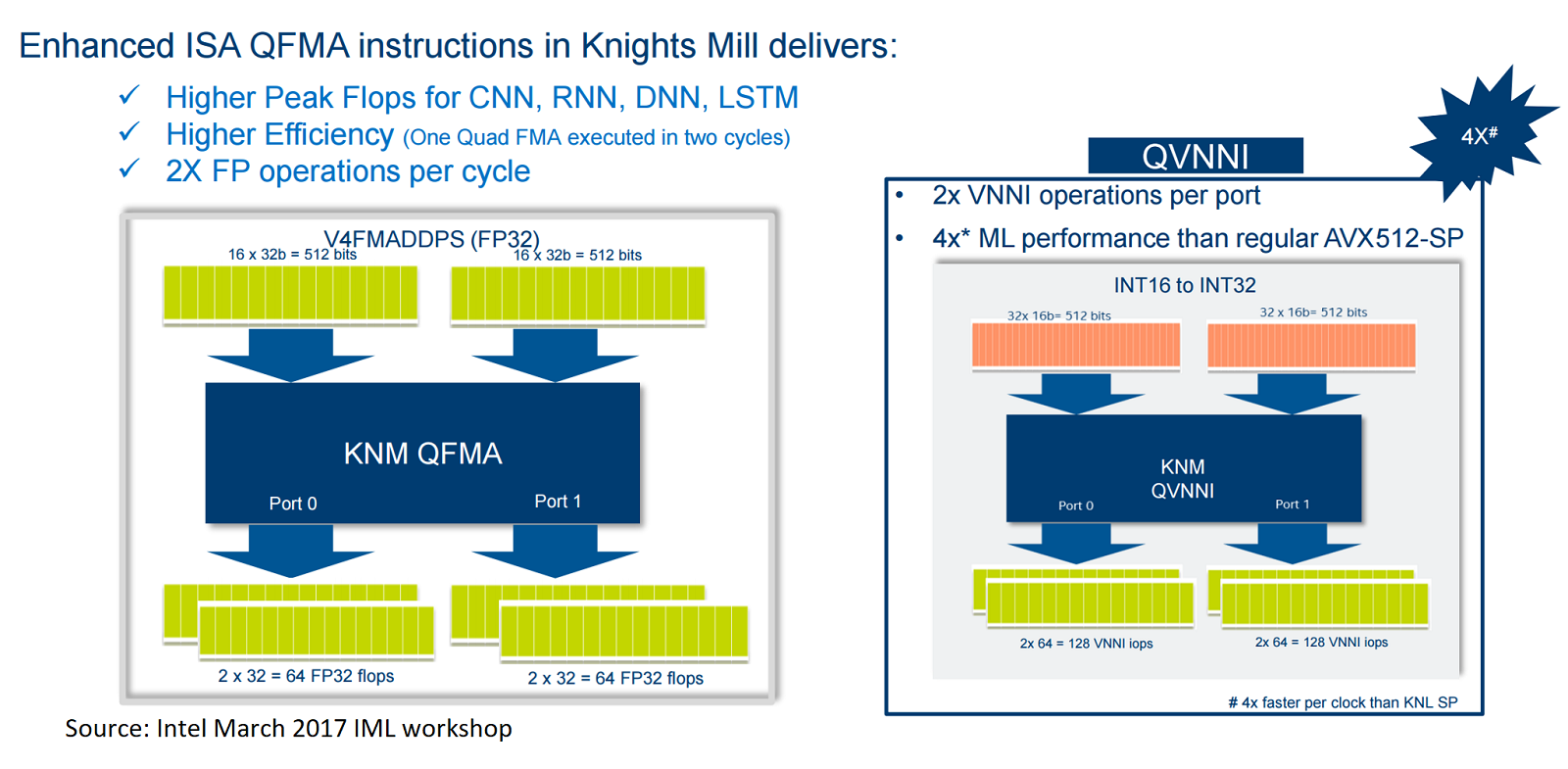
The new instruction sets also provide optimizations for 8-bit integer arithmetic, said Intel VP and GM of the technical computing initiative Trish Damkroger in a pre-show briefing with HPCwire. Our understanding is that this is accomplished within the 16-bit registers, where lanes are split to get three 8-bit operations and the fourth lane is used to do bit-mapping between registers.
There are also frequency, power and efficiency enhancements that contribute to the performance improvement of Knights Mill, but the biggest change is the deep learning optimized instructions.
“Knights Mill uses the same overarching architecture and package as Knights Landing. Both CPUs are a second-generation Intel Xeon Phi and use the same platform,” writes Intel’s Barry Davis in a blog post.
Customers will have a choice to make based on their precision requirements.
“Knights Mill uses different instruction sets to improve lower-precision performance at the expense of the double-precision performance that is important for many traditional HPC workloads,” Davis continues addressing the differentiation. “This means Knights Mill is targeted at deep learning workloads, while Knights Landing is more suitable for HPC workloads and other workloads that require higher precision.”
Here we see Intel differentiating its products for HPC versus AI, and the Nervana-based Lake Crest neural net processor also follows that strategy. Compare this with Nvidia’s Volta: despite being highly deep learning-optimized with new Tensor cores, the Tesla V100 is also a double-precision monster offering 7.5 FP64 teraflops.
Nvidia’s strategy is one GPU to rule them all, something VP of accelerated computing Ian Buck was clear about when we spoke this week.
“Our goal is to build one GPU for HPC, AI and graphics,” he shared. “That’s what’s we achieved in Volta. In the past we did different products for different segments, FP32-bit optimized products like P40, double-precision with the P100. In Volta, we were able to combine all that, so we have one processor that’s leading performance for double-precision, single-precision and AI, all in one. For folks who are in general HPC they not only get leading HPC double-precision performance, but they also get the benefits of AI in the same processor.”
So which strategy will ultimately win the hearts, minds and pocketbooks of end users and their funding bodies? In addition to its HPC success, Nvidia has captured the lion’s share of deep learning workloads, but the buzz over Google’s TPUs, activity around ASICs and FPGAs, and the proliferation of AI-silicon efforts, like Intel’s Lake Crest and the Knights Crest that will follow, reflect the huge groundswell towards application-optimized processing.

























































