 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Depending on whether you’ve been caught outside during a severe hail storm, the sight of greenish tinted clouds on the horizon may cause serious knots in the pit of your stomach, or at least give you pause. There’s good reason for that instinctive reaction. Just consider that a massive hail storm that battered the Denver metro area with golf ball-size hail on May 8, 2017, is expected to result in more than 150,000 car insurance claims and an estimated $1.4 billion in damage to property in and around Denver. The fact is that even in 2017, emergency responders, airports and everyone else going about their business must gamble with forecast uncertainties about hail. So how great would it be if you could get accurate warnings highlighting the path of severe hail storms, along with expected hail size, 1–3 hours before a storm passes through?
If the Severe Hail Analysis and Prediction (SHARP) project, which is funded through a grant from the National Science Foundation (NSF), accomplishes its goal of developing an accurate “warn-on-forecast” model for severe hail storms, this could happen in the next five to 10 years. Of course, there is a lot of scientific work to be done in the meantime, along with a need for significantly more computing power.
A two-pronged approach to hail research
The Center for Analysis and Prediction of Storms (CAPS) at the University of Oklahoma (OU) undertook the SHARP project in 2014 after hypothesizing that hail representation in numerical weather prediction (NWP) models, which mathematically model atmospheric physics to predict storms, could be improved by assimilating data from a host of data sources, and that advanced data-mining techniques could improve predictions of hail size and coverage.
Nathan Snook and Amy McGovern, two of the co-principal investigators on the project, say that CAPS pursues its hail research on two fronts. On one front, large amounts of data from various weather observing systems are ingested into weather models to create very high resolution forecasts. The other uses machine learning to sift through weather model output from CAPS and the National Center for Atmospheric Research to discover new knowledge hidden in large data sets and perform post-model correction calibrations to produce more skillful forecasts. For nearly four years, these projects have relied on the Texas Advanced Computer Center’s (TACC) Stampede system, an important part of NSF’s portfolio for advanced computing infrastructure that enables cutting-edge foundational research for computational and data-intensive science and engineering.
The high-resolution modeling is currently post-event and area specific, while the machine learning analysis is done in real time on a nationwide basis. The reason for the difference comes down to workload sizes. “For the high-resolution work, we use data from interesting historical cases to try to accurately predict the size and scope of hail that passes through a specific area,” explains Snook, a CAPS research scientist who focuses on the warn-on-forecast work. “We deal with 1 to 5 TB of data for each case study that we run, and run different experiments on different days, so our computing demands are enormous and the current available resources simply aren’t powerful enough for real-time analysis.”
McGovern, an associate professor of computer science and adjunct associate professor in the School of Meteorology at OU, says that although the machine learning algorithms are computationally intensive to train, it’s no problem to run them in real time because they are at a much coarser resolution than the data sets that Snook’s team uses (3km vs. 500m) and require fewer resources. “Our resource challenges are mainly around having enough storage and bandwidth to transfer all of the data we need on a daily basis…the data sets come from all over the U.S. and they are quite large, so there are a lot of I/O challenges,” explains McGovern.
Both research efforts rely heavily on data from the NOAA Hazardous Weather Testbed (HWT) to support their experiments. “The HWT gathers a wealth of numerical forecast data by collecting forecasts from various research institutions for about five to six weeks every spring. We use that data for a lot of our high-resolution experiments as well for our machine learning. It’s ideal for the machine learning work because it’s a big data set that is relatively stable from year to year,” says Snook.
Chipping away at high-resolution, real time forecasts
CAPS primarily uses two models for its high-resolution research, including the Weather and Research Forecasting (WRF) model, a widely used mesoscale numerical weather prediction system, and in-house model called the Advanced Regional Prediction System (ARPS). Snook says ARPS is also tuned for mesoscale weather analysis and is quite effective at efficiently assimilating radar and surface observations from a lot of different sources. In fact, to achieve greater accuracy in its warn-on-forecast modeling research, the CAPS team uses models with grid points spaced every 500m, as opposed to the 3km spacing typical in many operational high-resolution models. CAPS made the six-fold increase to better support probabilistic 1-3 hour forecasts of the size of hail and the specific counties and cities it will impact. Snook notes that the National Weather Service is moving toward the use of mesoscale forecasts in severe weather operations and that his team’s progress so far has been promising. In several case studies, their high-resolution forecasts have skillfully predicted the path of individual hailstorms up to three hours in advance—one such case is shown in figure 1.
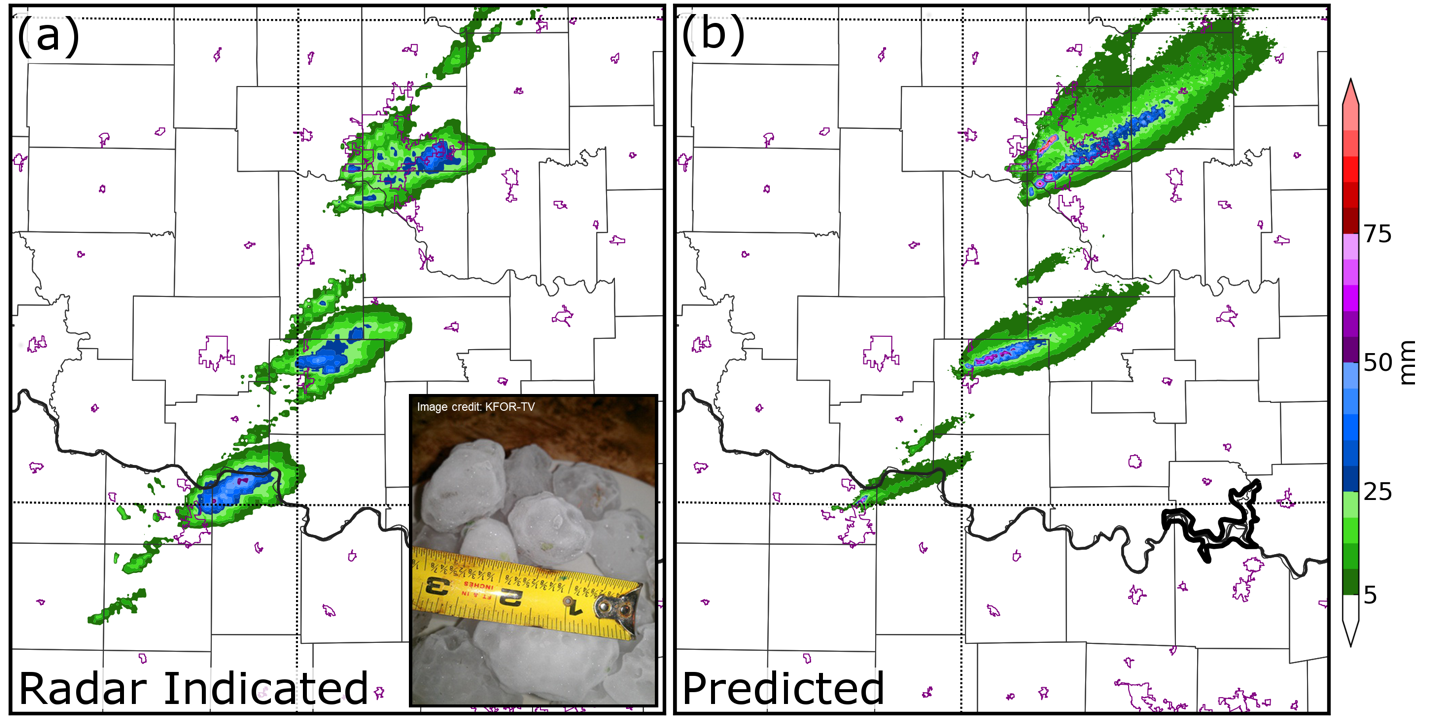
While the CAPS team is wrapping up the first phase of its research, Snook and his team have identified areas where they need to further improve their model, and are submitting a new proposal to fund additional work. “As you can imagine, we’re nowhere near the computing power needed to track every hailstone and raindrop, so we’re still dealing with a lot of uncertainty in any storm… We have to make bulk estimates about the types of particles that exist in a given model volume, so when you’re talking about simulating something like an individual thunderstorm, it’s easy to introduce small errors which can then quickly grow into large errors throughout the model domain,” explains Snook. “Our new focus is on improving the microphysics within the model—that is, the parameters the model uses to define precipitation, such as cloud water, hail, snow or rain. If we are successful at that, we could see a large improvement in the quality of hail forecasts.”
Going deeper into forecast data with machine learning
Unlike with the current high-resolution research, CAPS runs the machine learning prediction portion of the project using near real-time daily forecast data from the various groups participating in the HWT. CAPS compares daily realtime forecast data against historical HWT data sets using a variety of algorithms and techniques to flush out important hidden data in forecasted storms nationwide. “Although raw forecasts provide some value, they include a lot of additional information that’s not immediately accessible. Machine learning methods are better at predicting the probability and potential size, distribution and severity of hail 24 to 48 hours in advance,” explains McGovern. “We are trying to improve the predictions from what SPC and the current models do.”
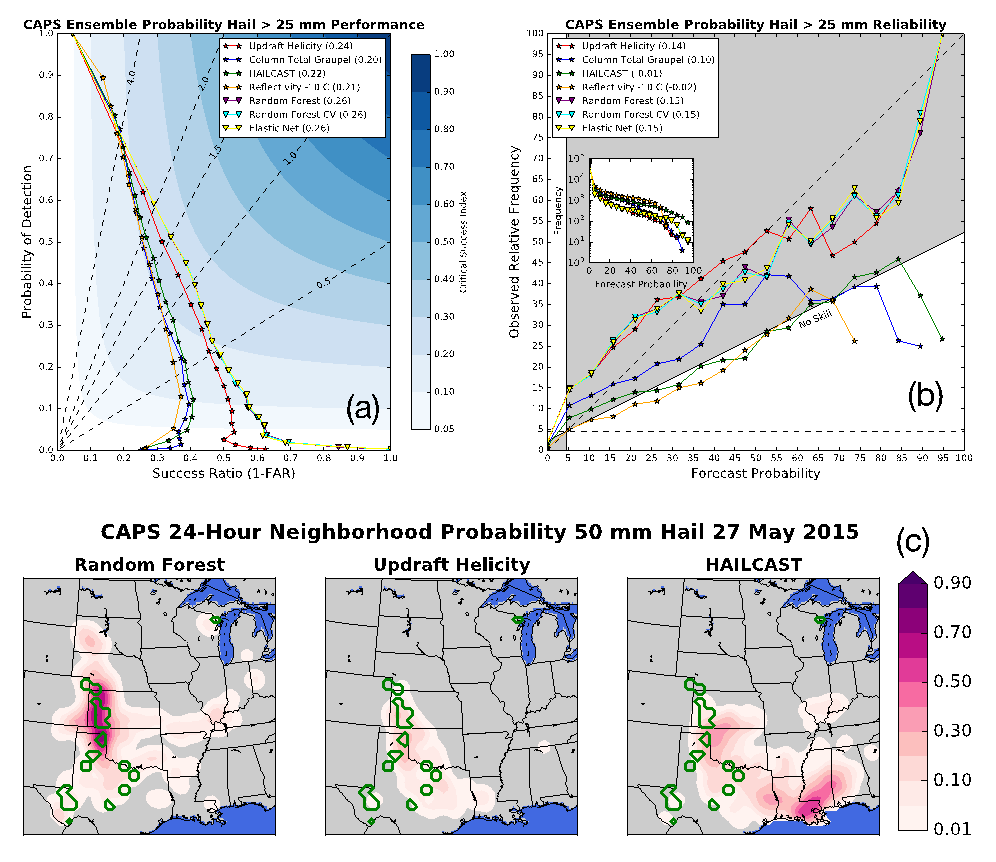
Figure 2 is a good illustration for how the machine learning models have improved the prediction of events for a specific case study. The figure, which highlights storms reported in the southern plains on May 27, 2015, compares the predictions using three different methods:
• Machine learning (left)
• A single parameter from the models, currently used to estimate hail (middle)
• A state-of-the-art algorithm currently used to estimate hail size (right)
The green circles show a 25 mile or 40 km radius around hail reports from that day, and the pink colors show the probability of severe hail, as predicted by each model. Although the updraft helicity model (middle) has the locations generally right, the probabilities are quite low. HAILCAST (right) overpredicts hail in the southeast while missing the main event in Oklahoma, Kansas, and Texas. The machine learning model (left) has the highest probabilities of hail exactly where it occurred. In general, this is a good example for how machine learning is now outperforming current prediction methods.
Currently, McGovern’s team is focusing on two aspects of hail forecasts: “First, we are working to get the machine learning methods into production in the Storm Prediction Center to support some high-resolution models they will be releasing. Second, we are improving the predictions by making use of the full 3D data available from the models,” explains McGovern.
A welcome resource boost
Snook says that the machine learning and high resolution research have generated close to 100TB of data each that they are sifting through, so access to ample computing resources is essential to ongoing progress. That’s why Snook and McGovern are looking forward to being able to utilize TACC’s Stampede2 system which, in May, began supporting early users and will be fully deployed to the research community later this summer. The new system from Dell includes 4,200 Intel Xeon Phi processors and 1,736 Intel Xeon processors as well as Intel Omni-Path Architecture Fabric, a 10GigE/40GigE management network, and more than 600 TB of memory. It is expected to double the performance of the previous Stampede system with a peak performance of up to 18 petaflops.
McGovern’s team also runs some of the machine learning work locally on the Schooner system at the OU Supercomputing Center for Education and Research (OSCER). Schooner, which includes a combination of Dell PowerEdge R430 and R730 nodes that are based on the Intel Xeon processor E5-2650 and E5-2670 product families as well as more than 450TB of storage, has a peak performance of 346.9 teraflops. “Schooner is a great resource for us because they allow ‘condo nodes’ so we can avoid lines and we also have our own disk that doesn’t get wiped every day,” says McGovern. “It’s also nice being able to collaborate directly with the HPC experts at OSCER.”
Between the two systems, Snook and McGovern expect to continue making steady progress on their research. That doesn’t mean real-time, high-resolution forecasts are right around the corner, however. “I hope that in five to 10 years, the warn-on-forecast approach becomes a reality, but it’s going to take a lot more research and computing power before we get there,” says Snook.


























































