 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetThe nature of dark energy and the complete theory of gravity are two of the central questions currently facing cosmologists. As the universe evolved, the expansion following the Big Bang initially slowed down due to gravity’s powerful inward pull. Presently, dark energy–a mysterious substance that seems to be associated with the vacuum of space itself–is pushing the universe outwards more strongly than gravity pulls in, causing the universe to not only expand but to do so faster and faster.
While dark energy constitutes 72 percent of the universe’s current energy density, its fundamental nature remains unknown. Much of today’s scientific work is trying to understand the interplay between gravity and dark energy in an effort to understand the current state of the universe.
There is an open problem in astronomy and cosmology in computing the anisotropic (direction-dependent) and isotropic (direction-averaged) 3-point correlation (3CPF) function which provides information on the structure of the universe. According to Prabhat, Big Data Center (BDC) Director and Group Lead for the Data and Analytics and Services team at Lawrence Berkeley National Laboratory’s (Berkeley Lab) National Energy Research Scientific Computing Center (NERSC), “Cosmologists and astronomers have wanted to perform the 3-point computation for a long time but could not do so because they did not have access to scalable methods and highly optimized calculations that they could apply to datasets.”
A project called Galactos has made a major breakthrough in successfully running the 3-point correlation calculation on Outer Rim, the largest known simulated galaxy dataset that contains information for two billion galaxies. The Galactos project is part of the Big Data Center collaboration between NERSC, Berkeley Lab and Intel.
“Essentially, we performed the entire 3CPF computation on two billion galaxies in less than 20 minutes and have solved the problem of how to compute the 3-point correlation function for the next decade. This work would not be possible without the use of high performance computer (HPC) systems, efficient algorithms, specialized software and optimizations,” states Prabhat.
Overview of the Galactos Project
According to Debbie Bard, Big Data Architect, Berkeley Lab who will be hosting a poster session on this topic at the Intel HPC Developers Conference just prior to SC17, “The statistics that our team uses to characterize the structure of matter in the universe are correlation functions. Our calculations provide information on how matter is clustered as well as insights about the nature of gravity and dark energy. The 2-point correlation function (2PCF) looks at pairs of galaxies and the distribution of galaxy pairs.[1] The 3-point correlation (3PCF) calculation, which looks at triplets, provides more detail about the structure of the universe, because you’ve added an extra dimension. 3PCF is rarely studied because it is very hard to calculate and it is computationally intensive. We felt if we could solve this problem from an algorithmic and computational point of view, then we would enable scientists to access the extra information about the structure of the universe.”

| Specifications of Cori HPC System
The Galactos code ran on the NERSC Cori system at Lawrence Berkeley National Laboratory. Cori is a Cray XC40 system featuring 2,388 nodes of Intel Xeon Processor E5-2698 v3 (named Haswell) and 9,688 nodes (recently expanded from 9,304) of Intel Xeon Phi Processor 7250 (named Knights Landing). The team performed all computations on Intel Xeon Phi nodes. Each of these nodes contains 68 cores (each supporting 4 simultaneous hardware threads), 16 GB of on-package, multi-channel DRAM (“MCDRAM”), and 96 GB of DDR4-2400 DRAM. Cores are connected in a 2D mesh network with 2 cores per tile, and 1 MB cache-coherent L2 cache per tile. Each core has 32 KB instruction and 32 KB data in L1 cache. The nodes are connected via the Cray Aries interconnect. |
Process used in the 3-point Computation
Figure 2 shows the image of a simulated miniature universe containing 225,000 galaxies in a box, and provides information on how galaxies are grouped together in a structured way rather than randomly distributed. The Galactos computation process involves three major steps. Around a selected primary galaxy, the algorithm first gathers all galaxy neighbors (secondaries) within a maximum distance Rmax and bins them into spherical shells. It then rotates all coordinates so that the line of sight to the primary from an observer is along the z-axis, and transfers all of the secondaries’ separation vectors from the primary to that frame. Then the algorithm expands the angular dependence of the galaxies within each bin into spherical harmonics, a particular set of mathematical functions. This expansion is represented by the shading in the Expand portion of the graphic.
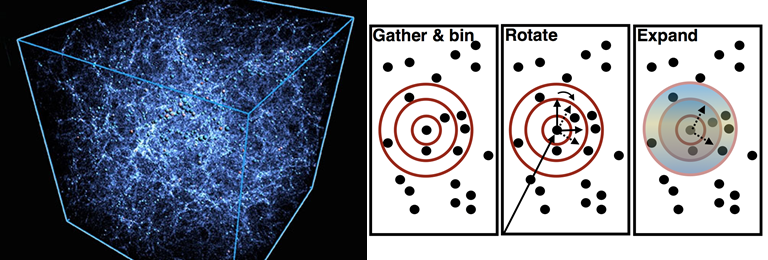
The Galactos algorithm is parallelized across nodes by taking all 2 billion galaxies in the dataset and breaking them into smaller boxes using the highly efficient k-d tree algorithm developed by Intel. There is also a halo exchange component to expand a fixed box by 200 megaparsecs (200 Mpc = 300 million light years) on each face and pull in all of the galaxies that reside within the extended region. Each node has all the galaxies it needs to determine the full 3PCF and need not communicate with any other nodes until the very end.
O(N2) Algorithm Speeds 3CPF Computation
Galactos used a highly scalable O(N2) algorithm originally created by Zachary Slepian, Einstein Fellow at Berkeley Lab, in conjunction with Daniel Eisenstein, Slepian’s PhD advisor and professor of astronomy at Harvard University. In addition, the team used optimized k-d tree libraries to perform the galaxy spatial partitioning. Brian Friesen (Berkeley Lab, HPC Consultant) and Intel worked on optimizing the code to run across all 9,636 nodes of the NERSC Cori supercomputer.
According to Slepian, “Counting all possible triangles formed by a set of objects is a combinatorially explosive challenge: there are an enormous number of possible triangles. For N objects, there are N options for the first choice, N-1 for the second, and N-2 for the third, leading to N(N-1)(N-2) triangles. If the number of objects is very large, this is roughly N3.
The key advance of our O(N2) algorithm is to reorder the counting process to reduce the scaling to N2. In practice, this means a speed-up of 500X or more over a naive, ‘just-counting’ approach.
The algorithm exploits the fact that, in cosmology, we want our result to be binned in triangle side length. For example, I might report a result for triangles with the first side between 30 and 60 million light years and second side between 90 and 120 million light years. Our algorithm manages to do this binning first, so one never has to compare combinations of three galaxies, but rather, one compares combinations of bins. There are many fewer bins than galaxies, so this is an enormous computational savings.
The algorithm does this is by writing the problem using a particular set of mathematical functions, known as a ‘basis’, that is ideal for the problem. Our basis has the same symmetries as galaxy clustering and can compactly represent the information the clustering contains. Further, this set of functions, called Legendre polynomials, can be split into spherical harmonic factors.” [2,3]
Optimizations and Vectorization used in the Galactos Project
According to Friesen, “The Galactos optimization consisted of two components including single node and multi-node scaling. The multi-node scaling uses a k-d tree algorithm, which is a multi-node k-d tree with Message Passing Interface (MPI) built in. k-d trees are used to partition a data set so that data elements that are physically near each other are close to each other in memory. In Galactos, the k-d tree helps improves performance when determining which galaxy neighbors are nearby.
“The k-d tree is also important for computational load balance between nodes on the system,” Friesen adds. “The bulk of the computation in Galactos occurs within a node, so there is very little communication between nodes. If there are large load imbalances between nodes, then the algorithm only calculates as fast as the slowest node. The team worked to make the computational load as similar as possible between nodes to increase the speed of the algorithm.”
Enabling vectorization on the Intel Xeon Phi processor required sorting the galaxies, such that pairs of galaxies separated by similar distances were adjacent in memory. This enabled the algorithm to compute the geometric properties of many galaxy pairs simultaneously using vectorization, rather than computing the properties of each galaxy pair individually.
For the Galactos project, Intel optimized performance within a single Intel Xeon Phi node and across the Cray XC40 supercomputer. Intel was earlier involved in computing the 2-point correlation function with Berkeley Lab [4]. “Our optimizations to Galactos included (1) a distributed k-d tree algorithm for partitioning the galaxies and enabling fast computation of nearest neighbors to any galaxy and (2) computation of spherical harmonics around each galaxy locally. Step 2 is the biggest computational bottleneck and was vectorized over the neighbors of a given galaxy with multiple galaxies running in parallel on different threads. We used Intel developer tools optimized for Intel Xeon Phi processors,” states Narayanan Sundaram, Intel Research Scientist. In all Galactos computations, code is compiled using the Intel C++ v17.0.1 compiler with Cray MPI. The team ran the code with one MPI process per Intel Xeon Phi compute node, using 272 threads per node (four threads per physical core).
Galactos Time to Solution Test Results for the Outer Rim Dataset
Galactos testing included performance breakdown of the code running the Outer Rim dataset with 225,000 galaxies on a single node. Its single-node performance has been highly optimized for Intel Xeon Phi processors, reaching 39 percent of peak but 80 percent of the theoretical maximum performance given the algorithm’s required instruction mix, with efficient use of vectorization and the full memory hierarchy. Galactos achieves almost perfect weak and strong scaling, and achieves a sustained 5.06 PF across 9636 nodes.


The team ran Galactos over 9,636 available nodes of the Cori system in both mixed and double precision. (In mixed precision, the k-d tree is computed in single precision and everything else is in double precision.) The time to solution to compute the 3PCF for 2 billion galaxies in mixed precision is 982.4 sec (16.37 minutes); in pure double precision, the time to solution is 1070.6 sec (17.84 minutes).
Galactos Aids in Future Cosmology Research
Prabhat states, “As computer scientists, a lot of our achievements are surpassed in a few years because our field changes rapidly. The Galactos project has enabled a previously intractable computation to run on the Cori supercomputer in 20 minutes. When the LSST comes online, the code will be able to process massive datasets in a day or two. This project has been particularly satisfying for our team, because we have not only solved the 3-pt correlation problem for the largest dataset available in 2017, but for the next decade in astronomy. How often do you get to make that claim?”
References
[1] J. Chhugani et al., “Billion-particle SIMD-friendly two-point correlation on large-scale HPC cluster systems,” High Performance Computing, Networking, Storage and Analysis (SC), 2012 International Conference for, Salt Lake City, UT, 2012, pp. 1-11.
[2] Z. Slepian & D.J. Eisenstein, Computing the three-point correlation function of galaxies in O(N2) time, Monthly Notices of the Royal Astronomical Society, Volume 454, Issue 4, p.4142-4158
hyperlink: https://arxiv.org/abs/1506.02040
[3] “A Practical Computational Method for the Anisotropic Redshift-Space 3-Point Correlation Function”, Zachary Slepian and Daniel J. Eisenstein, hyperlink: https://arxiv.org/abs/1709.10150, submitted to Monthly Notices of the Royal Astronomical Society.
[4] Galactos: Computing the Anisotropic 3-Point Correlation Function for 2 Billion Galaxies Brian Friesen, Md. Mostofa Ali Patwary, Brian Austin, Nadathur Satish, Zachary Slepian, Narayanan Sundaram, Deborah Bard, Daniel J Eisenstein, Jack Deslippe, Pradeep Dubey, Prabhat, Cornell University Library, 31 Aug 2017
hyperlink: https://arxiv.org/abs/1709.00086
About the Author
Linda Barney is the founder and owner of Barney and Associates, a technical/marketing writing, training and web design firm in Beaverton, OR.

























































