 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
According to Al Gara (Intel Fellow, Data Center Group), high performance computing and artificial intelligence will increasingly intertwine as we transition to an exascale future using new computing, storage, and communications technologies as well as neuromorphic and quantum computing chips. Gara observes that, “The convergence of AI, data analytics and traditional simulation will result in systems with broader capabilities and configurability as well as cross pollination.”
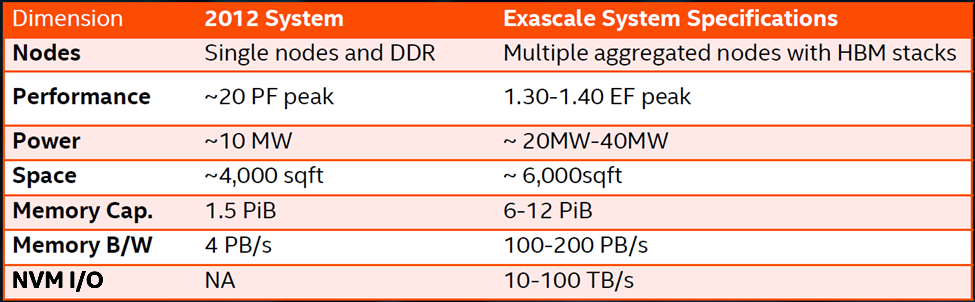
Gara sees very aggressive hardware targets being set for this intertwined HPC and AI future, where the hardware will deliver usable performance exceeding one exaflops of double precision performance (and much more for lower and reduced precision arithmetic). He believes a user focus on computation per memory capacity will pay big dividends across architectures and provide systems software and user applications the opportunity to stay on the exponential performance growth curve through exascale and beyond as shown in the performance table below.
Unification of the “3 Pillars”
The vision Gara presented is based on a unification of the “3 Pillars” of HPC: Artificial Intelligence (AI) and Machine Learning (ML); Data Analytics and Big Data; plus High Performance Computing (HPC). What this means is that users of the future will program using models that leverage each other and that interact through memory.

More concretely, Intel is working towards exascale systems that are highly configurable that can support upgrades to fundamentally new technologies including scalable processors, accelerators, neural network processors, neuromorphic chips, FPGAs, Intel persistent memory, 3D NAND, and custom hardware.

The common denominator in Gara’s vision is that the same architecture will cover HPC, AI, and Data Analytics through configuration, which means there needs to be a consistent software story across these different hardware backends to address HPC plus AI workloads.
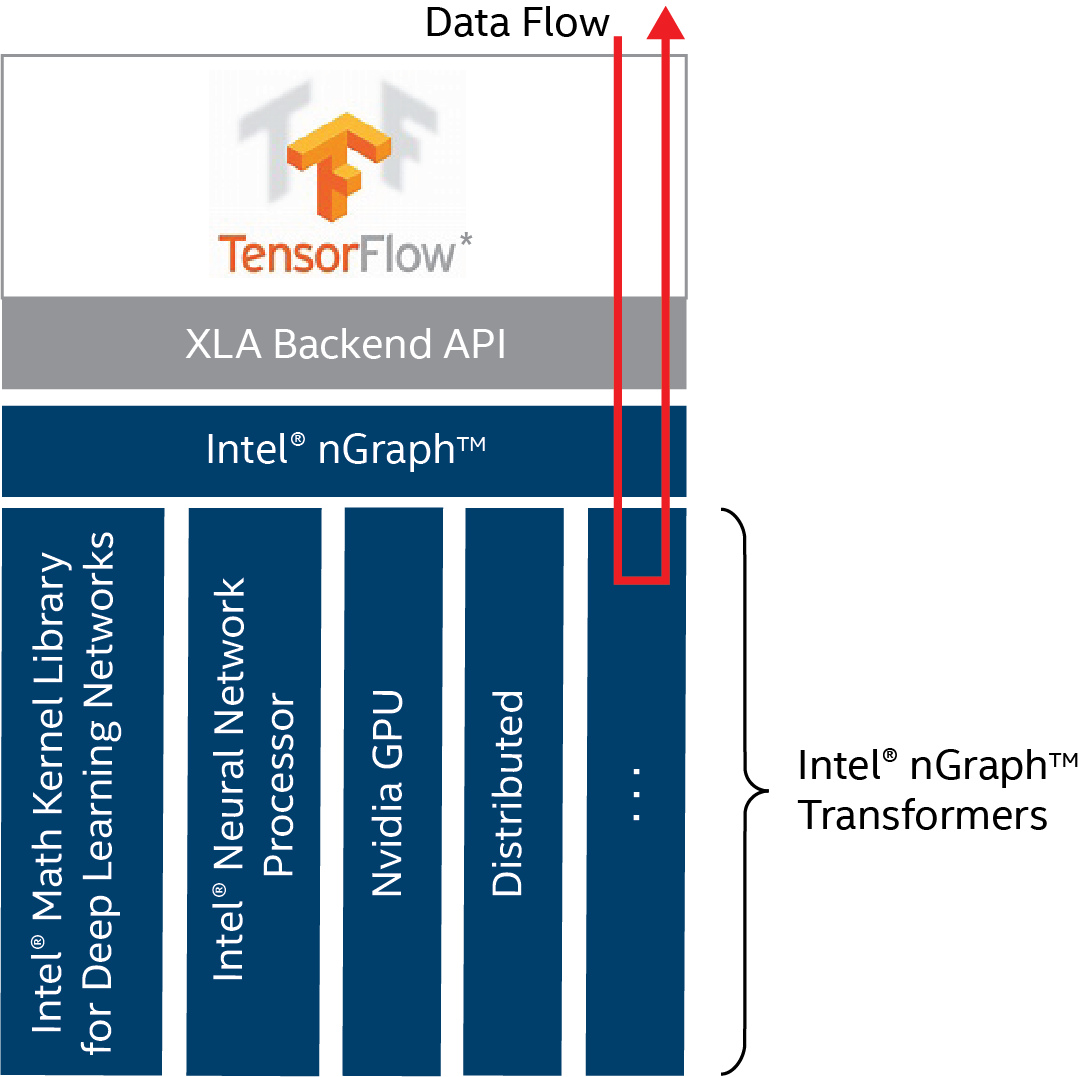
A current, very real instantiation of Gara’s vision is happening now through the use of Intel nGraphT library in popular machine learning packages such as TensorFlow. Essentially, Intel nGraph library is being used as an intermediate language (in a manner analogous to LLVM) that can deliver optimized performance across a variety of hardware platforms from CPUs to FPGAs, dedicated neural network processors, and more.
Jason Knight (CTO office, Intel Artificial Intelligence Products Group) writes, “We see the Intel nGraph library as the beginning of an ecosystem of optimization passes, hardware backends and frontend connectors to popular deep learning frameworks.”
Overall, Gara noted that “HPC is truly the birthplace of many architectures … and the testing ground” as HPC programmers, researchers, and domain scientists explore the architectural space map the performance landscape:
- Data level parallel (from fine grain to coarse grain)
- Energy efficient accelerators (compute density and energy efficiency often are correlated)
- Exploiting predictable execution at all levels (cache to coarse grain)
- Integrated fixed function data flow accelerators
- General purpose data flow accelerators
Technology Opportunities
HPC and AI scientists will have access and the ability to exploit the performance capabilities of a number of new network, storage, and computing architectures.
In particular, HPC is a big driver of optical technology as fabrics represent one of the most challenging and costly elements of a supercomputer. For this reason, Gara believes that silicon photonics is game changing as the ability to integrate silicon and optical devices will deliver significant economic and performance advantages including room to grow (in a technology sense) as we transition to linear and ring devices and optical devices that communicate using multiple wavelengths of light.
New non-volatile storage technologies such as Intel persistent memory are blurring the line between memory and storage. Gara describes a new storage stack for exascale supercomputers, but of course this stack can be implemented on general compute clusters as well.
The key, Gara observes, is that this stack is designed from the ground up to use NVM storage. The result will be high throughput IO operations at arbitrary alignment and transaction sizes because applications can perform ultra-fine grained IO through a new userspace NVMe/pmem software stack. At a systems level, this means that users will be able to manage massively distributed NVM storage using scalable communications and IO operations across homogenous, shared-nothing servers in a software managed redundant, self-healing environment. In other words, high-performance, big-capacity scalable storage to support big-data and in-core algorithms such as log-runtime algorithms and data analytics on sparse and unstructured data sets.
Researchers are exploiting the advances in memory performance and capacity to change the way that we approach AI and HPC problems. Examples of such work range from the University of Utah to King Abdullah University of Science and Technology (KAUST) in Saudi Arabia.
For example, Dr. Aaron Knoll (research scientist, Scientific Computing and Imaging Institute at the University of Utah) stresses the importance the logarithmic runtime algorithms in the Ospray visualization package. Logarithmic runtime algorithms are important for big visualizations and exascale computing. Basically the runtime increases slowly as data sizes increase. The logarithmic growth is important as the runtime increases slowly even when the data size increases by orders of magnitude. Otherwise, the runtime growth can prevent computations from finishing in a reasonable time, thus obviating the benefits of a large memory capacity computer.
As a result, large memory capacity (e.g., “fat”) compute nodes that provide low latency access to data are the enabling technology that can compete and beat massively parallel accelerators at their own game. Research at the University of Utah [PDF] shows a single large memory (three terabyte) workstation can deliver competitive and even superior interactive rendering performance compared to a 128-node GPU cluster. The University of Utah group is also exploring in-situ visualization using P-k-d trees and other fast, in-core approaches [PDF] to show that large “direct” in-core techniques are viable alternatives to traditional HPC visualization approaches.
In a second example, KAUST has been enhancing the ecosystem of numerical tools for multi-core and many-core processors in collaboration with Intel and the Tokyo Institute of Technology. Think of processing really big billion by billion sized matrices using CPU technology in a mathematically and computationally efficient manner.
The importance of these contributions in linear algebra and Fast Multi-pole Methods (FMM) can be appreciated by non-HPC scientists as numerical linear algebra is at the root of nearly all applications in engineering, physics, data science, and machine learning. The FMM method has been listed as one of the top ten algorithms of the 20th century.
Results show that HPC scientists now have the ability to solve faster and larger dense linear algebra problems and FMM related numerical problems than is possible using current highly optimized libraries such as the Intel Math Kernel Library (Intel MKL) running on the same hardware. These methods have been made available in highly optimized libraries bearing the names of ExaFMM, and HiCMA.
Looking to the future: Neuromorphic and Quantum Computing
The new neuromorphic test chips codenamed Loihi may represent a phase change in AI because they “self-learn”. Currently, data scientists spend a significant amount of time working with data to create training sets that are used to train a neural network to solve a complex problem. Neuromorphic chips eliminate the need for a human to create a training set (e.g., no human in the loop). Instead, humans need to validate the accuracy once the neuromorphic hardware has found a solution.
Succinctly, neuromorphic computing utilizes an entirely different computational model than traditional neural networks used in machine and deep learning. This model more accurately mimics how biological brains operate so neuromorphic chips can “learn” in an event driven fashion simply by observing their environment. Further, they operate in a remarkably energy efficient manner. Time will tell if and when this provides an advantage. The good news is that neuromorphic hardware is now becoming available.
Gara states that the goal is to create a programmable architecture that delivers >100x energy efficiency over current architectures to solve hard AI problems efficiently. He provided examples such as sparse coding, dictionary learning, constraint satisfaction, pattern matching, and dynamic learning and adaptation.
Finally, Gara described advances in quantum computing that are being made possible through a collaboration with Delft University to make better Qubits (a Quantum Bit), improve connectivity between Qubits, and develop scalable IO. Quantum computing is non-intuitive because most people don’t intuitively grasp the idea of entanglement or something being in multiple states at the same time. Still the web contains excellent resources such as Quantum computing 101 at the University of Waterloo to help people make sense of this technology that is rapidly improving and, if realized, will change our computing universe forever.
Quantum computing holds the possibility of solving currently intractable problems using general purpose computers. Gara highlighted applications of the current Intel quantum computing efforts in quantum chemistry, microarchitecture and algorithm co-design, and post-quantum secure cryptography.
Summary
We are now seeing the introduction of new computing, storage, and manufacturing technologies that are forcing the AI and HPC communities to rethink their traditional approaches so they can use these ever more performant, scalable, and configurable architectures. Al Gara pointed out, technologies are causing a unification of the “3 pillars” which, in turn, makes the future of AI and HPC in the data center indistinguishable from each other.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. Rob can be reached at [email protected]

























































