 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street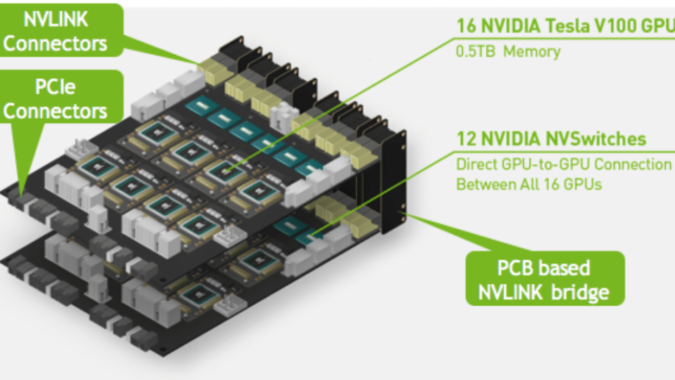
Nvidia’s updated server platform is intended as a “building block,” in the reference design sense, to support AI training and inference along with HPC workloads such as simulations.
The GPU vendor introduced its latest server platform dubbed HGX-2 on Wednesday (May 30) during a company roadshow in Taipei, Taiwan. Nvidia said the system can be throttled up or down to support precision HPC calculations from 32-bits for single-precision floating point format, or FP32, up to double-precision FP64.
Meanwhile, AI training and inference workloads are supported with FP16, or half precision, along with Int8 data. The combination is designed for varying processing requirements for a growing number of enterprise applications that combine AI with HPC, the company noted.
The HGX-2 is based on Nvidia’s Tensor Core GPUs that target AI-powered deep learning applications ranging from autonomous driving to natural speech. Released a year after the unveiling of its first HGX platform, Nvidia said the second iteration serves as a building block for manufacturers combining AI and HPC. The company claimed AI training speeds of up to 15,500 images per second based on the ResNet-50 training benchmark.
“What accelerated computing is all about is the full stack—creating a new type of processor that fuses HPC and AI, optimizing across the stack, developing switches, developing motherboards, developing systems, system software, APIs and libraries,” noted Nvidia CEO Jensen Huang.
The platform incorporates Nvidia’s NVSwitch interconnect fabric used to link 16 Tesla V100 GPUs. The combined system, capable of delivering 2 petaflops of machine learning performance (or 124.8 double-precision teraflops, if you prefer), serves as the basis of Nvidia’s recently announced DGX-2 deep learning platform. (For more on DGX-2, see our coverage from GTC18.)
Nvidia’s updated reference design further defines server classes by recommending the optimal mix of GPUs, CPUs, and interconnects for targeted workloads, i.e., training (HGX-T), inference (HGX-I), and supercomputing (SCX) applications. See chart below for more details and note the power draw starts at an energy-sipping 600 watts on the inference-themed HGX-I1, which incorporates two P4 GPUs, and shoots to 10,000 watts for the flagship HGX-T2 with 16 Voltas strapped to an NVLink backplane.

Indicative of the growing number of AI workloads handled in datacenters, Nvidia said four server makers—Lenovo, QCT, Supermicro and Wiwynn—would release systems later this year based on the HGX-2. Meanwhile, Taiwanese electronics manufacturing giant Foxconn is among a group of equipment makers planning to release cloud datacenter systems based on the new Nvidia server platform.
Those manufacturers joined other server makers and datacenter operators that have deployed the initial HGX architecture, including Amazon Web Services, Facebook and Microsoft.
Nvidia asserts its “unified computing platform” addresses the requirements of server manufacturers seeking to align datacenter infrastructure by offering a mix of CPUs, GPUs and interconnections for training, inference and HPC workloads. In a testimonial, Ed Wu, a corporate executive vice president at Foxconn, said the HGX-2 would help it “fulfill the explosive demand [for datacenter processing] from AI” and deep learning.
–Tiffany Trader contributed to this report.

























































