 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Intel’s chief datacenter exec Navin Shenoy kicked off the company’s Data-Centric Innovation Summit Wednesday, the day-long program devoted to Intel’s datacenter strategy, encompassing a number of product and technology updates, including another 14nm Xeon kicker, called Cooper Lake.
The headline-stealing announcement was Intel’s chip business hitting $1 billion in artificial intelligence revenue in 2017. The bulk of that comes from inferencing workloads, Intel indicated, noting that FGPAs and IoT are not included in the total figure. The company sees that AI opportunity growing to $10 billion by 2022.

“There’s going to be a portion [of that total addressable market] that’s strictly training and a portion that’s strictly inference,” said Intel’s head of AI products Naveen Rao. “However, there are new paradigms emerging and you can see that line blurring. We expect that reinforcement learning is going to start coming on the scene in a strong way, combined with simulation capabilities, transfer learning and hybrid models. There’s a future where learning will be distributed from end point to edge to cloud.”
According to Intel’s math and its assessment of AI TAMs, the company has captured the lion’s share of the inferencing market. Nvidia may disagree.
Reached for comment, industry analyst Patrick Moorhead, president and principal analyst, Moor Insights & Strategy, said, “On the AI front, watching Intel’s event you would think Intel is a major player in the AI industry. But I have to say, I don’t hear much about Intel in AI from anyone other than Intel. Yes, $1B is $1B. But would you also say that Nvidia really is the much more the dominant force? And can we also take from today’s event that Intel didn’t make claims to being a strong player on the training side of the AI equation?”
Based on the growth of AI and analytics and its “comprehensive and consistent” IP portfolio, Intel said it is revising its total datacenter business TAM from $160 billion in 2021 to $200 billion in 2022. This is the biggest opportunity in the history of the company, said Shenoy.
With the 10nm Ice Lake delayed until 2020, Intel is continuing to expand and extend the 14nm generation. “We’re making process improvements, we’re adding architectural advancements and we’ll continue to push on the software front as well,” said Shenoy.

In laying out its Xeon roadmap, the company announced the addition of the 14nm Cooper Lake targeting a late-2019 launch. “We have created a flexible, feature-rich platform that allows our customers to select the right CPU for their workloads that will support both a new 14nm CPU called Cooper Lake and the 10nm Ice Lake product,” said Shenoy. Cooper Lake will “generate and deliver a significantly better generation-on-generation performance improvement,” according to the exec.

The next-generation Xeon, codenamed Cascade Lake, is on track to ship in late 2018. Based on 14nm technology, Cascade Lake introduces a new AI extension to Xeon called Intel Deep Learning Boost (DL Boost) that extends the Intel AVX 512, adding a new vector neural network instruction (VNNI) that can handle INT8 convolutions with fewer instructions. A performance demonstration using a simulated version* of the future Cascade Lake with DL Boost achieved an average speedup of about 11x over Skylake, running Caffe ResNet-50, a popular AI workload for image classification.
Cascade Lake also debuts Intel Optane DC persistent memory and provides enhanced security features to address Spectre and Meltdown vulnerabilities.
The recently announced Intel Optane DC persistent memory is a new class of memory and storage that enables a large persistent memory tier between DRAM and SSDs. It’s capable of up to eight times the performance of configurations with DRAM only, according to Intel. The first production units of Optane persistent memory have shipped to Google and broad availability is planned for 2019.
The follow-on to Cascade Lake, Cooper Lake, debuts another new AI extension: bfloat16. Part of the DL Boost family, it leverages AI’s tolerance of lower precision and will principally be used for training kinds of workloads. “We are aggressively standardizing on bfloat16 and infusing it into all of our products in Xeon and our Network Neural Processor (NNP) family,” said Shenoy, “and so you can expect us […] to drive an aggressive push over the course of the second half of this year into 2019 and 2020.”
 At its AI developer conference in San Francisco in May, Intel announced plans for the first commercial Nervana product, NNP L-1000 (codenamed Spring Crest), said to offer 3-4x the training performance of the development product, Lake Crest. Spring Crest is anticipated in late 2019, and Intel says it is also building a variant for the inference market, but is not ready to disclose any details.
At its AI developer conference in San Francisco in May, Intel announced plans for the first commercial Nervana product, NNP L-1000 (codenamed Spring Crest), said to offer 3-4x the training performance of the development product, Lake Crest. Spring Crest is anticipated in late 2019, and Intel says it is also building a variant for the inference market, but is not ready to disclose any details.
Speaking on the competition for AI market share, Rao said that he wanted to cut through the myth that GPUs are the only thing out there for AI. “The reality is almost all inference in the world runs on Xeon today and the performance gap between general-purpose computing and specific kinds of computing like GPU is not some enormous gap like 100x, it’s more like 3x, and that’s okay,” he said. “Because general-purpose computing has a scale that a specific solution can’t really achieve. Everything has its place. Once AI starts making its way into general-purpose computing, we’ve achieved a scale with this new technology that we simply couldn’t before, so it’s incumbent on us to continually evolve our platform to make it the best that it can be for AI as well as everything else that Xeon does today.
“Xeon wasn’t well optimized [for AI] from a software perspective two years ago,” Rao added. “But just from the launch of Skylake in July of 2017, we’ve increased performance of inference by 5.4x*, and training by 1.4x*. We’ve added things like vector and matrix multiplication and SIMD instructions at the Skylake launch to continue gen-on-gen improvement. On Cascade Lake, we are adding DL Boost, this family of new capabilities, and we showed you [a projected] 11x improvement.”
The Intel event was broadly focused on datacenter strategy and AI, but it did not provide drill down into HPC-specific technology plans. While the Phi line has come to an end, Intel is counting on the successor to Phi for its exascale plans and it is on the hook to deliver an exascale, or at least an exaflops peak, system to Argonne Lab in 2021 (though a contract has not yet been inked). A leaked Intel roadmap that surfaced a couple weeks ago (via AnandTech) reveals that beyond Xeon Phi lies Cascade Lake-AP (AP=Advanced Processor), positioned to debut in the first half of 2019, followed by a “Next-Gen AP” slated for mid-2020.
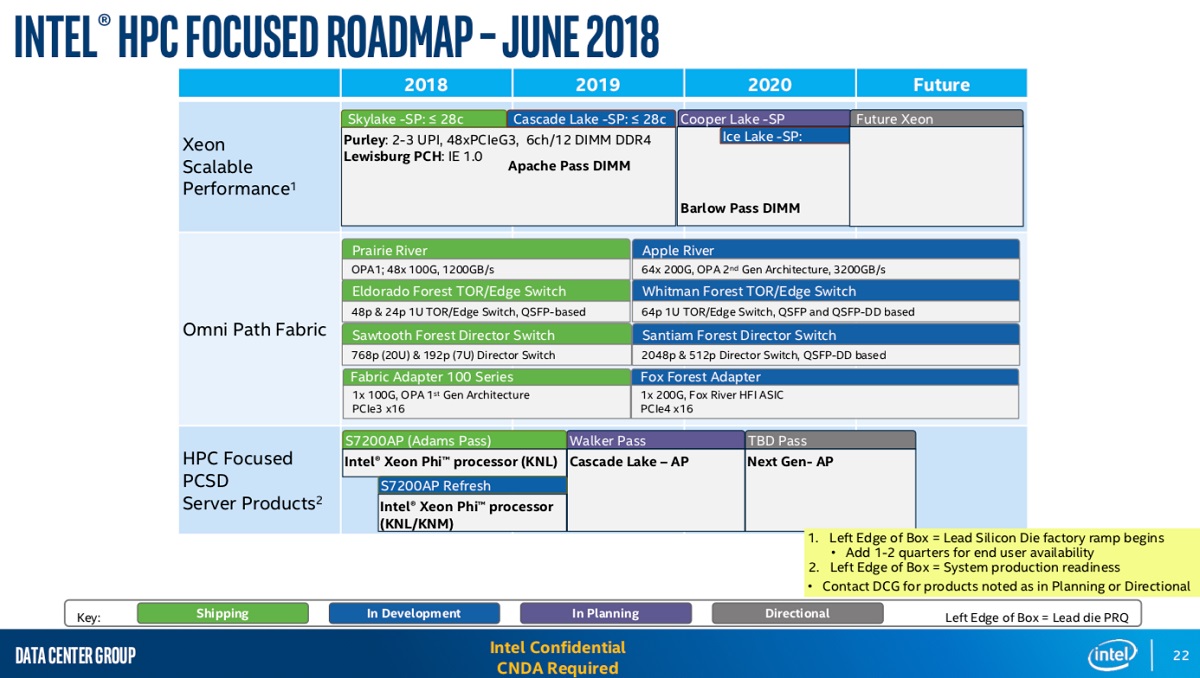
The leaked slide also shows the 200 Gbps successor to Omni-Path, OPA 200, appearing in late 2019. Planned products include a 64-port top-of-rack switch, a 2,048-port director switch and a PCIe4x16 Host Fabric Interface (HFI) adapter. Intel, of course, does not comment on company information not disclosed through official channels.
*Configuration details provided by Intel























































