 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Overview
The use of graphics processing units (GPUs) to accelerate portions of general-purpose scientific and engineering applications is widespread today. However, the adoption for running GPU-based high performance computing (HPC) and artificial intelligence jobs is limited due to the high acquisition cost, high power consumption and low utilization of GPUs. Typically, applications can only access GPUs located within the local node where they are being executed which limits their usage. In addition, the sharing of GPUs is not considered by job schedulers such as SLURM that may be used for HPC or AI compute runs.
In today’s datacenter environment, the ability to leverage system resources, especially that of GPUs needs to be more flexible. An ideal solution is sharing the notably expensive, power hungry GPUs among several nodes in a cluster as part of a virtualization solution. Virtualizing and sharing GPUs efficiently addresses several concerns including maximizing utilization across remote GPU resources for either or HPC and AI workloads.
The GPU virtualization middleware solution from rCUDA (remote CUDA) solves these issues by turning GPUs into virtual compute resources when running on networks with underlying high-performance networking technologies such as Mellanox InfiniBand®. According to Dr. Federico Silla, Associate Professor at the Department of Computer Engineering and rCUDA team leader, from Universitat Politècnica de València (Technical University of Valencia) in Spain, “Sharing GPUs among nodes in the cluster by remotely virtualizing them is a powerful mechanism that can provide important energy savings while at the same time the overall cluster throughput (in terms of jobs completed per time unit) is noticeably increased. Furthermore, it is possible to provide differentiated quality service levels to customers paying different fees. rCUDA is a modern tool that adds value to the GPUs in your cluster.”
Introducing rCUDA
The rCUDA framework was developed by Universitat Politècnica de València (Spain). rCUDA is a middleware product that enables remote virtualization of GPUs. With rCUDA, physical GPUs are installed only in some of the nodes of the cluster, and they are transparently shared among all the nodes. Nodes equipped with GPUs provide GPU services to all of the nodes within the cluster.
Benefits of running rCUDA in the data center
- Energy savings
- rCUDA improves GPU utilization and makes GPU usage more efficient and flexible, allowing up to 100% of available GPU capacity
- More GPUs are available for a single application
- Using rCUDA does not mean a drop or reduced performance (on average, the overhead of using rCUDA is negligible when InfiniBand or RDMA over Converged Ethernet (RoCE) are leveraged)
- Same fabric, no special network is needed
- rCUDA is transparent to applications (source code of NVIDIA CUDA® applications does not need to be modified)
- rCUDA is not tied to a specific processor architecture
- GPU virtualization enables cluster configurations with a reduced number of GPUs reducing the costs associated with the use of GPUs
How does rCUDA work?
While NVIDIA’s CUDA® platform is limited to interact with GPUs that are physically installed in the node where the application is being executed, remote GPU virtualization frameworks follow a client-server distributed approach. With rCUDA, applications are not limited to local GPUs, and can leverage any GPU in the cluster— this is known as remote GPU virtualization. The client part of the rCUDA middleware is installed in the cluster node that is executing the application which is requesting GPU services. The server side runs on the system owning the actual GPU. When the client receives a CUDA request from an accelerated application, it processes it and forwards it to the remote server. The server node receives the request and forwards it to the GPU, which completes the execution of the request and provides the associated results back to the server which is executing the application process as shown in Figure 1.

Applications do not need to be modified to use rCUDA. However, applications must be linked to the rCUDA libraries instead of the CUDA libraries. rCUDA then decouples GPUs from the nodes where they are installed and creates a GPU clustering environment with multiple GPUs which provide services to multiple local or remote compute systems. Clustered GPUs can be transparently shared by any of the nodes in the facility.
rCUDA runs on many systems and applications
Mellanox InfiniBand and RoCE enabled solutions have native RDMA engines which are supported across system architectures and can easily implement rCUDA functionality. Because rCUDA is also not tied to a specific processor architecture —it can run on a variety of systems including x86, ARM, and IBM POWER processors as shown in Figure 2.
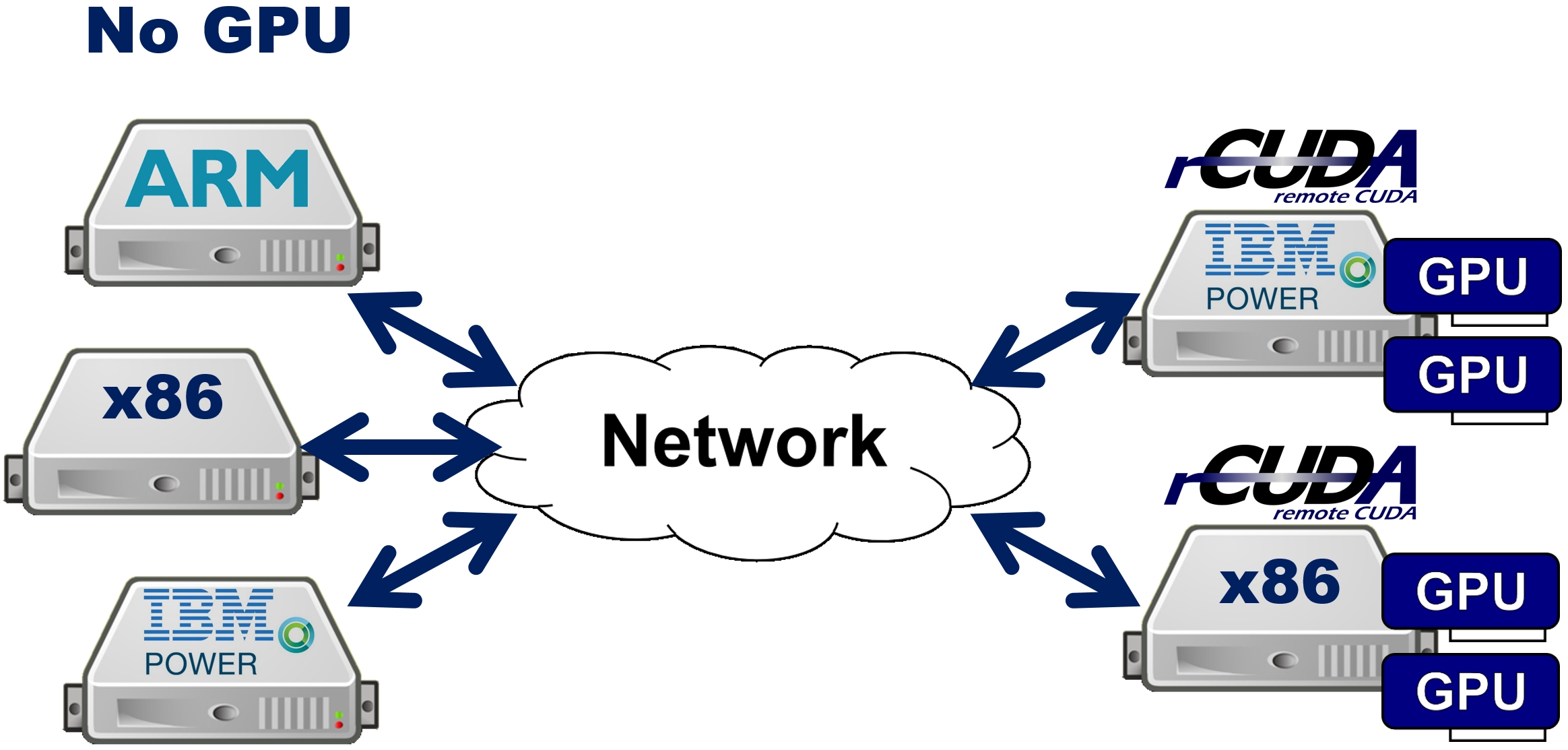
“In addition, rCUDA has successfully run on popular GPU and HPC applications such as BARRACUDA, CUDAmeme, GPUBlast, GPU-LIBSVM, Gromacs, LAMMPS, MAGMA and NAMD. Deep learning frameworks are also supported. rCUDA has been successfully run with TensorFlow version 1.7, Caffe, Torch, Theano, PyTorch and MXNET. Finally, renderers such as Blender and Octane are also supported,” states Silla.
How Mellanox integrates with rCUDA
Mellanox Technologies is a leading supplier of end-to-end Ethernet and Mellanox InfiniBand® intelligent interconnect solutions and services for servers, storage, and hyper-converged infrastructure. Mellanox intelligent interconnect solutions increase data center efficiency by providing the highest throughput and lowest latency, delivering data faster to applications and unlocking system performance. Because Mellanox InfiniBand is based on open standards, its non-proprietary solutions easily integrate with all middleware technologies, including rCUDA’s innovative GPU virtualization technology.
Previously, virtualized GPUs were impaired by the low bandwidth of the underlying network. However, there is a negligible performance impact when running rCUDA on a high-performance network fabric such as Mellanox InfiniBand— execution time is usually increased by less than 4% when a high performance network fabric is used. “By taking full advantage of the native RMDA engines, the high bandwidth and ultra-low latency of Mellanox InfiniBand, rCUDA provides near-native performance to applications using any remote GPU,” states Scot Schultz, Sr. Director, HPC / Artificial Intelligence and Technical Computing – Mellanox Technologies.
Summary
Until recently, GPU usage for HPC and AI processing has been limited because native CUDA software could only use GPUs that were physically installed in the node where the application is executed. rCUDA’s virtualized middleware installed on systems using Mellanox’s high bandwidth networking architecture allows GPUs to be shared among all the nodes from the entire cluster rather than limiting the user application to a single node’s local GPUs. rCUDA also provides significant energy and cost savings with negligible impact to application performance.
According to Silla, “Different remote GPU virtualization solutions provide varying performance values when used across clusters. Therefore, you have to try remote GPU virtualization by yourself in your cluster to draw your own conclusions. Do not accept demos carried out in clusters other than your own. Unlike other solutions, you can try rCUDA in your cluster to prove its value in your system.”
![]()
![]()
References
rCUDA slides: http://www.rcuda.net/pub/rCUDA_isc18.pdf
rCUDA technical paper: https://dl.acm.org/citation.cfm?id=2830015
























































