 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
From supercomputers to cell phones, every system and software device in our digital panoply has a growing number of settings that, if not optimized, constrain performance, wasting precious cycles and watts.
In the fast-growing field of AI, optimized systems yield faster training times and require less infrastructure. But the tuning process can be tedious and requires specialized skills. Startup Concertio, creator of performance optimization toolkit Optimizer Studio, is asking the question, “can we relieve data scientists from the need to understand their specific underlying infrastructure and from the need to optimize the performance of their models?”
In short: can the tuning process be automated?
Using Concertio’s optimization tool, Intel was able to accelerate TensorFlow implementations of three popular deep learning models, including
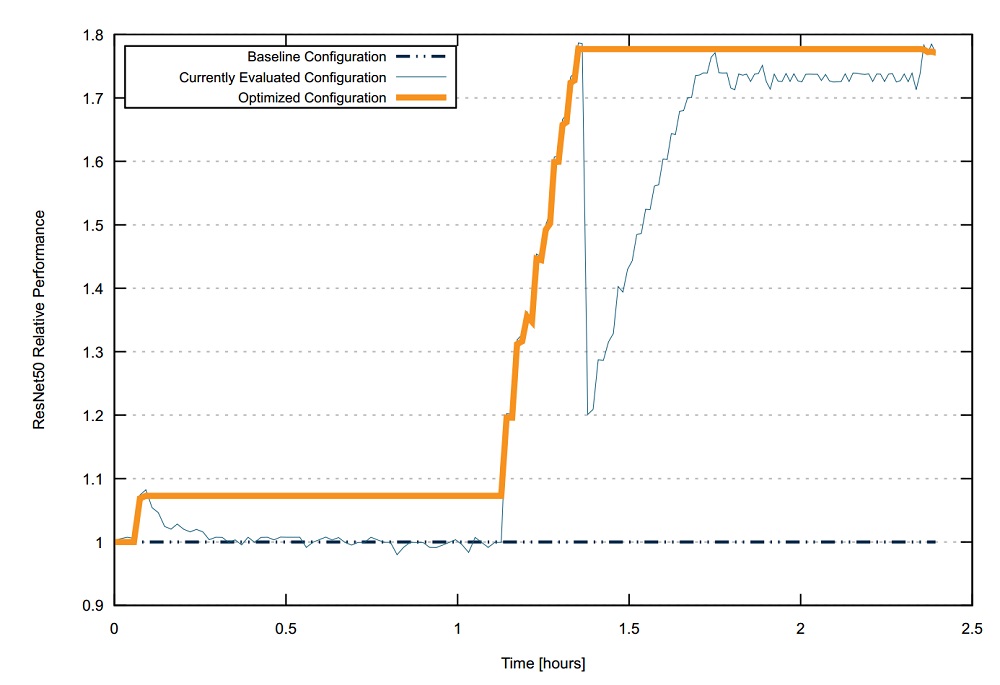
ResNet50, which saw a speedup of 1.77x over baseline. The result, described by Intel and Concertio, was achieved automatically without any manual effort, producing comparable speedup to manual tuning by Intel’s engineers. “What took tens of hours of manual labor was now done automatically in just two hours,” reported Concertio Co-founder and CEO Tomer Morad in a blog post, published today.
“Concertio’s Optimizer Studio was able to leverage the tunables of TensorFlow and Intel Xeon Scalable Processors to further accelerate deep learning workloads,” shared Dr. Arjun Bansal, vice president of AI Software and Research at Intel. “Optimizer Studio is able to relieve engineers from the task of finding optimal system settings, as it achieves at least comparable performance to manual tuning – but without the manual effort.”
Concertio’s Optimizer Studio tool (profiled by EnterpriseTech earlier this year) navigates the broad parameter space of system settings and application settings on today’s devices and works to maximize the performance by finding the best settings possible. Settings can be anywhere in the system — in the processor, the firmware, the operating system and also in the applications and application frameworks, like TensorFlow. Optimizer Studio runs the workload iteratively until it finds a configuration that performs well. The two parameters that Intel had Optimizer Studio zero in on for tuning its Tensorflow workload for ResNet50 are called intra_op and inter_op, which control model level parallelism and data parallelism.
Morad explains that optimizing these parameters can greatly accelerate throughput for the training, but there’s a tradeoff where higher values increase parallelism but also amplify the contention on shared resources such as the main memory and on-chip caches. There comes a point where the benefit of increased parallelism gets canceled out by the slowdown caused by increased contention. With inter_op values ranging from 1 to 28 and intra_op taking an even number from 10 to 56, there are 672 possible configurations to explore, so finding the optimized combination requires extensive experimentation that can take tens of hours.
The team of Intel AI engineers, led by Dr. Jayaram Bobba, performed the optimization using Concertio Optimizer Studio version 1.12 on an Intel Xeon Platinum 8180 processor (@ 2.50GHz) with 384GB RAM. It took two hours and 8 minutes to identify the optimal values for inter_op and intra_op (found to be 2 and 28, respectively).
This graph shows ResNet50 relative performance during optimization:
The first model that Intel evaluated, ResNet50, is a variant of Deep Residual Networks, the deep convolutional neural network created by
Microsoft. The Intel team extended its assessment to include GNMT (Google’s Neural Machine Translation System) and DeepSpeech, an open-source speech-to-text engine, implemented in TensorFlow. In this round of testing, Intel was looking to see whether optimized OS and CPU settings would provide further performance gains following manual optimization of their TensorFlow tunables. Using Optimizer Studio with the same Xeon test platform led to the discovery of settings that improved the performance by 8.3 percent and 8 percent for GNMT and DeepSpeech respectively.
Morad told HPCwire that Concertio and the Intel AI team crossed paths a while back when Concertio was meeting with another group at Intel in Hillsboro, Ore. The Intel AI team is constantly looking for ways to improve TensorFlow performance on Intel Architectures, so it was natural for them to explore a tool that promised to automate the tedious task of searching for optimal configurations. The Intel engineers downloaded the Optimizer Studio software and conducted the experiments. Along the way, they provided feedback to Concertio that went into improving the product.
It is Concertio’s expectation that users running TensorFlow who have not done regular system tuning will likely see a sizable speedup from Optimizer Studio. “Since the effort involved in manual tuning on a regular basis is significant, we see that in the vast majority of cases it just never happens,” said Morad. “This is one of the main advantages of using automation for this purpose — the tool allows integrating performance optimization into the CI/CD pipeline so that every software version that comes out is always performing at its best.”
“Our aim was to make Optimizer Studio as intuitive as possible to use, and it is satisfying to see that the majority of users are able to see results in the first day of use without requiring assistance,” said Morad. “That said, we love being engaged with our users and assisting them, and we do so through various channels, including via Slack.”
Developers can purchase annual licenses of Optimizer Studio directly from Concertio or through value-added distributors. High-performance computing users can also get these tools from Red Barn Technology Group, an HPC systems integrator headquartered in Binghamton, NY.
Read the blog for the full study as well to see configuration details and disclaimers.


























































