 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Software-Defined Networking (SDN) is a concept that has emerged in recent years to decouple network control and forwarding functions. SDN promises to enable a manageable and cost-effective network that fits the needs of high-bandwidth applications. Most published SDN-related information talks about Ethernet networks and describes the effort to adjust Ethernet to the needs of today’s applications.
The one network type that does not require special effort to adjust it to the computational needs of high-performance computing, deep learning or any other data intensive application is InfiniBand. InfiniBand was specified (in 1999) as the ultimate software-defined network, long before the term SDN was coined.
InfiniBand networks can be fully controlled and managed by a software element called a subnet-manager. Unlike Ethernet, InfiniBand does not have different kinds of network switches, such as “top of rack” or “aggregation level” switches, because it uses the same building block to create any size of infrastructure—from a small cluster to an Exascale platform, and to form a sort of network topology. InfiniBand does not carry the complex network algorithm baggage that Ethernet does, which becomes more onerous from generation to generation, and creates performance and cost burdens on the Ethernet infrastructure. Moreover, InfiniBand switch latency is 3 times better than the best Ethernet switch on the market today (and probably in the future too), and InfiniBand networks can be 30 percent or more better cost effective than the bandwidth equivalent Ethernet network.
20 years ago, there were two leading proprietary networks in the world of HPC: Myrinet from Myricom and QsNet from Quadrics. Looking back, one of the mistakes both vendors made was to switch from a full proprietary network to using Ethernet as the underlying network and to run their proprietary transport over Ethernet, tying their roadmap to Ethernet. The reason for this move was clear: reducing the R&D efforts needed to develop a network. But the cost was high: Performance limitations, adding complexity and scaling issues due to Ethernet. As a result, Myrinet and QsNet fell behind InfiniBand—a network that was designed for data-intensive applications. As a side note, Quadrics became defunct in 2009. Their IP was later used by Gnodal to create Ethernet switches running the Quadrics protocol inside the switch. But Gnodal did not succeed and was defunct in 2013. Also, the same IP is now being used by one of the HPC system vendors for their new proprietary interconnect, which again is trying to run a proprietary network transport over Ethernet, in spite of the failure of previous attempts.
Beyond high latency, which escalates with the size of the network infrastructure, Ethernet also suffers from congestion control (such as ECN and QCN) and routing schemes that do not fit dynamic HPC and AI workloads. A vendor trying to use Ethernet as the basis for proprietary network transports will need to invest in developing proprietary protocols to handle these issues, which is complicated and leads to overall lower performance.
The InfiniBand specification is handled by IBTA (InfiniBand Trade Association); as an industry standards-based interconnect technology, InfiniBand is proven to provide forward and backward compatibility across generations of technology. As the ultimate software-defined network, InfiniBand provides low latency, smart routing and congestion-avoidance mechanisms together with the ability to support vendor-defined In-Network Computing acceleration engines. In-Network Computing transforms the data center interconnect into a “distributed co-processor” able to handle and accelerate the performance of various data algorithms, such as reductions and more.
In-Networking Computing is the heart of today’s and tomorrow’s data-centric data centers. Firstly, it provides the ability to offload all network functions from the CPU to the network. And secondly, it allows offloading various data algorithms. Examples are Mellanox Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™ technology, interconnect-based MPI Tag Matching and Rendezvous protocol network engines, and more.
In looking at InfiniBand routing schemes, InfiniBand provides a very efficient and robust fine-grained adaptive routing. For known application patterns, InfiniBand enables supercomputer managers to use perfectly matched static routing schemes, and to easily optimize them for their needs. For supercomputing infrastructures supporting a wide variety of HPC and AI workloads, InfiniBand offers adaptive routing. InfiniBand also ensures reliable data delivery and does not drop packets.
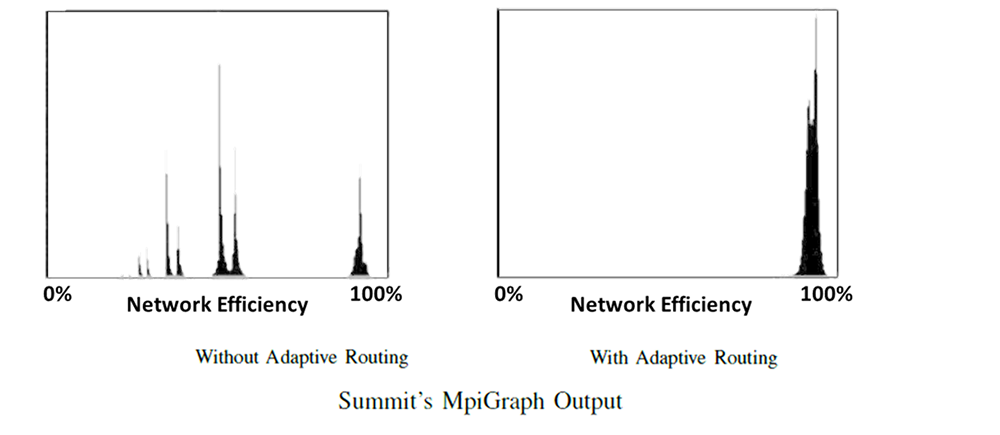
Oakridge National Laboratory’s (ORNL) Summit supercomputer and Lawrence Livermore National Laboratory’s (LLNL) Sierra supercomputer reflect the DoE Exascale architecture path and are ranked number 1 and number 2 on the November 2018 TOP500 supercomputers list. These systems leverage InfiniBand for its high throughput, low latency, routing protocols, and In-Network Computing engines to deliver an efficient and scalable computing infrastructure. In a paper titled “The Design, Deployment, and Evaluation of the CORAL Pre-Exascale Systems,” people from Oak Ridge and Lawrence Livermore labs explore the performance advantages of the InfiniBand network, including the performance of InfiniBand adaptive routing technology.
Figure 1 and Figure 2 showcase the testing results on the Summit supercomputer. These results are based on the Bisection bandwidth benchmark MpiGraph, which explores the performance of MPI process pairs in full permutations. Figure 1 presents the histogram results, in which adaptive routing showcases that all MPI pairs achieve nearly maximum bandwidth, while static routing suffers from congestion that limits data bandwidth. Figure 2 highlights the same results differently, where lighter colors represent less variation and data traffic congestion between pairs of nodes. Adaptive routing in InfiniBand sustains 96% network utilization at a large scale (this is the fastest supercomputer in the world today). This level of network utilization is higher than other existing networks, and future proprietary networks on paper.

Another aspect of InfiniBand is its ability to support any network topology one can design. For example, InfiniBand is being used to form Fat-Tree (CLOS) topologies, Hypercube and Enhanced Hypercube, Torus, Mesh, Dragonfly+ and more. The InfiniBand Dragonfly+ topology enables lower latency versus other Dragonfly topologies used in proprietary networks. The current HDR 200 gigabit InfiniBand solution can connect more than 160 thousand endpoints with the Dragonfly+ topology at 3 switch connection hops. And the upcoming NDR 400 gigabit InfiniBand technology can connect more than 1 million endpoints in the same manner.
By leveraging the economy of scale, and the scale of performance, InfiniBand is the leading interconnect solution for the Exascale era.























































