 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this bimonthly feature, HPCwire highlights newly published research in the high-performance computing community and related domains. From parallel programming to exascale to quantum computing, the details are here.
Using pervasive machine learning for effective HPC
The intersection of HPC and machine learning promises to yield major performance improvements. In this paper – written by a team from Indiana University Bloomington, University of Virginia, Arizona State, Rutgers and Brookhaven National Lab – the authors discuss the “Learning Everywhere” paradigm for HPC. They introduce the concept of “effective performance” – achieved by combining learning methodologies with simulation-based approaches – and outline examples and opportunities across a series of domains.
Authors: Geoffrey Fox, James A. Glazier, JCS Kadupitiya, Vikram Jadhao, Minje Kim, Judy Qiu, James P. Sluka, Endre Somogyi, Madhav Marathe, Abhijin Adiga, Jiangzhuo Chen, Oliver Beckstein and Shantenu Jha.
Orchestrating intercontinental advance reservations with software-defined exchanges
When separated by great distances, research facilities are connected by science networks, allowing experimenters to establish dedicated circuits for transferring large amounts of data using advanced reservation systems. In this paper, written by a team from Argonne National Laboratory and the George Institute of Technology, the authors discuss intercontinental advance reservations, which are often difficult to coordinate – especially as the number of participants increases. They discuss the design and implementation of an architecture for end-to-end service orchestration in these situations, improving the reservation success rate.
Authors: Joaquin Chung, Rajkumar Kettimuthu, Nam Pho, Russ Clark and Henry Owen.
Simulating clusters, binaries and planets with multi-scale HPC
 Over the last decade, the computational demands of astrophysics simulations have dramatically increased, necessitating redesigns of most relevant software with the introduction of parallelism and hybrid hardware. In this paper, A. van Elteren and S. Portegies Zwart outline their multi-scale approach to creating more maintainable, flexible and scalable astrophysics simulation software.
Over the last decade, the computational demands of astrophysics simulations have dramatically increased, necessitating redesigns of most relevant software with the introduction of parallelism and hybrid hardware. In this paper, A. van Elteren and S. Portegies Zwart outline their multi-scale approach to creating more maintainable, flexible and scalable astrophysics simulation software.
Authors: A. van Elteren and S. Portegies Zwart
Load balancing in distributed exascale computing based on process requirements
When the workload of a dynamic exascale computing system changes, the load balancer needs to collect system state information, increasing the runtime. In this paper, published in the Azerbaijan Journal of High Performance Computing, the authors explore how understanding the dynamic events that influence workload can help system operators to better manage load balancing behavior.
Authors: Shirin Shahrabi, Faezeh Mollasalehi, Araz R. Aliev and Ehsan Mousavi Khaneghah.
Detecting anomalies in HPC systems online
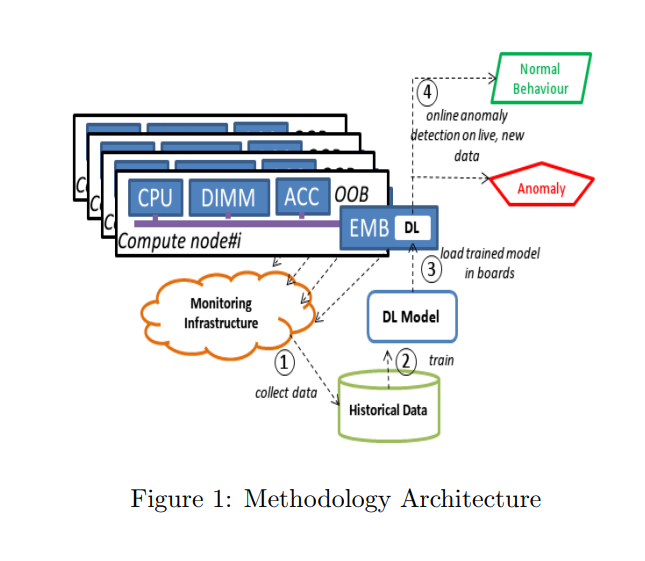 As HPC systems scale up, anomalies are becoming more and more common. Currently, fault and anomaly detection is performed manually – but in this paper, written by a team from Italy and Switzerland, the authors discuss an alternative. The proposed method of anomaly detection uses a neural network trained to learn the normal behavior of a system and deployed on the edge of each computing node. The authors discuss initial results.
As HPC systems scale up, anomalies are becoming more and more common. Currently, fault and anomaly detection is performed manually – but in this paper, written by a team from Italy and Switzerland, the authors discuss an alternative. The proposed method of anomaly detection uses a neural network trained to learn the normal behavior of a system and deployed on the edge of each computing node. The authors discuss initial results.
Authors: Andrea Borghesi, Antonio Libri, Luca Benini and Andrea Bartolini.
Geographic information sciences have been dramatically advanced by the rapid advance of high-resolution data collection, and cyberinfrastructure – including HPC – has advanced to meet the increased demands of these datasets. In this dissertation, written by a student from Arizona State University, the author develops an interoperable and replicable geoprocessing service combining an HPC environment with rich datasets and Python-based spatial analysis. The author suggests that this service might reduce the performance issue in large feature data transmission.
Author: Hu Shao
In this article, a team of Russian researchers describe their efforts to test the Angara interconnect using the Desmos supercomputer as a testbed. Through their testing, they verify that the Angara interconnect is able to unite massively parallel programming systems, speeding up MPI-based applications. They outline a series of benchmarks and the job scheduling statistics during the testing period.
Authors: Vladimir Stegailov, Ekaterina Dlinnova, Timur Ismagilov, Mikhail Khalilov, Nikolay Kondratyuk, Dmitry Makagon, Alexander Semenov, Alexei Simonov, Grigory Smirnov and Alexey Timofeev.
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.

























































