 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
At Intel’s investor meeting today in Santa Clara, Calif., the company filled in details of its roadmap and product launch plans and sought to allay concerns about delays of its 10nm chips. In laying out its 10nm and 7nm timelines, Intel revealed that its first 7nm product would be a GPU targeted for datacenter and HPC applications. The product is intended to debut as the primary engine for the Department of Energy’s Aurora supercomputer in 2021. Intel also revealed that its OneAPI software would be available to developers in Q4 of 2019.
Murthy Renduchintala, Intel’s chief engineering officer and president of the technology, systems architecture & client group, said the 7nm transistor geometry lines up with the company’s next-generation packaging technologies, Foveros and EMIB.
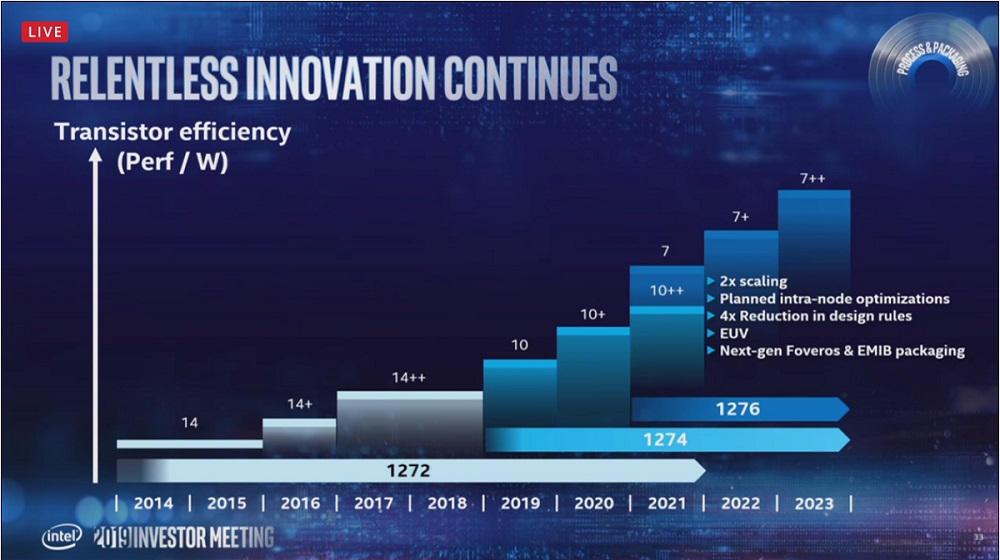
Intel expects its 7nm process technology to deliver 2x scaling, approximately 20 percent increase in performance per watt with a 4 times reduction in design rule complexity.
The 7nm process will also introduce Intel’s first commercial use of EUV, a major area of risk reduction for the node, noted Renduchintala. “This technology will help drive scaling for multiple nodes, and we are planning on many waves of intra-node improvement,” he said.
Renduchintala also reported that the company’s 10nm technology went into high volume production at the beginning of this year, while colleague Navin Shenoy confirmed that the 10nm datacenter part, Ice Lake Xeon, is on track for production in first half of 2020.
 “We are now shipping samples to customers and many of those have already powered that silicon on,” said Shenoy, executive vice president and general manager of the datacenter group.
“We are now shipping samples to customers and many of those have already powered that silicon on,” said Shenoy, executive vice president and general manager of the datacenter group.
While concentrating on advancing per core performance leadership, Intel says it will also be picking up the pace of its cadence of its Xeon roadmap, moving from what was historically a 5-7 quarter cadence to a 4-5 quarter cadence, and deliberately planning for intra-node optimizations.
“From Cascade Lake to Ice Lake to Sapphire Rapids–our next generation 2021 Xeon built on 10nm++ technology–to the next gen after that, we are going to be on a 4-5 quarter cadence and bring pace to bear on the compute demands that our customers have,” said Shenoy.
Renduchintala acknowledged that 10nm left “a major gap” in Intel’s process roadmap, which the company responded to by extracting more from its 14nm technology, resulting in two rounds of optimizations in 14+ and 14++. “We also adapted our roadmap to deliver timely product refreshes, such as Kaby Lake, Coffee Lake and Whiskey Lake for our client portfolio, and Cascade Lake and Cooper Lake for our datacenter product line,” said Renduchintala.

“The net result of these optimizations is that between the first product generation on 14nm, Broadwell, and the latest 14++ product such as Whiskey Lake, we achieved a greater than 20 percent improvement in transistor efficiency, and we’re able to deliver a 30 percent improvement in total performance,” he said.
Renduchintala highlighted lessons learned on the 10nm path: “the value in maintaining a mix of nodes that provide flexibility to optimize for product performance, time to market and margin,” and the importance of “making it easy and fast for our development teams to migrate their designs through internode transitions.”
Intel plans that the introduction of 7nm will overlap with the last node of 10: 10++. CEO Bob Swan advised investors that the tight timeline of 10nm ramp and fast follow of 7nm would impact gross margins.
The Xe compute architecture and OneAPI
 Details of Intel’s Xe architecture have been trickling out since Intel confirmed its design win for the Aurora supercomputer, which it will build with partner Cray for Argonne National Laboratory in line with U.S. exascale goals. Intel revealed last week that the GPU would have ray tracing capabilities and it also established three institutions to advance research for large scale graphics and visualization. The three Intel Graphics and Visualization Institutes of XeLLENCE (Intel GVI) are located at the University of Utah, the Texas Advanced Computing Center (TACC) at University of Texas, Austin, and at the University of Stuttgart (VISUS).
Details of Intel’s Xe architecture have been trickling out since Intel confirmed its design win for the Aurora supercomputer, which it will build with partner Cray for Argonne National Laboratory in line with U.S. exascale goals. Intel revealed last week that the GPU would have ray tracing capabilities and it also established three institutions to advance research for large scale graphics and visualization. The three Intel Graphics and Visualization Institutes of XeLLENCE (Intel GVI) are located at the University of Utah, the Texas Advanced Computing Center (TACC) at University of Texas, Austin, and at the University of Stuttgart (VISUS).
Another element from the Aurora announcement is OneAPI, which Intel today disclosed will be made available to developers in the fourth quarter of this year. OneAPI is Intel’s effort to unify programming across the company’s compute product portfolio–its CPUs, GPUs, specialized AI silicon, and FPGAs–which the company collectively refers to as its XPUs.
“We have a broad portfolio of XPUs,” said Renduchintala. “Of course the CPU remains the central nervous system of our architectures going forward, but they will be complemented by what we believe are really high performance GPUs, neural network processing units, where we have specific AI workloads that benefit from custom acceleration, and field programmable gate array technology where we need the flexibility to handle spatial workloads.”
“[The goal of the OneAPI project] is to harmonize access to those XPU technologies through a single set of APIs that makes the user feel a seamless transition from one XPU architecture to the other,” said Renduchintala.
























































