 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this bimonthly feature, HPCwire highlights newly published research in the high-performance computing community and related domains. From parallel programming to exascale to quantum computing, the details are here.
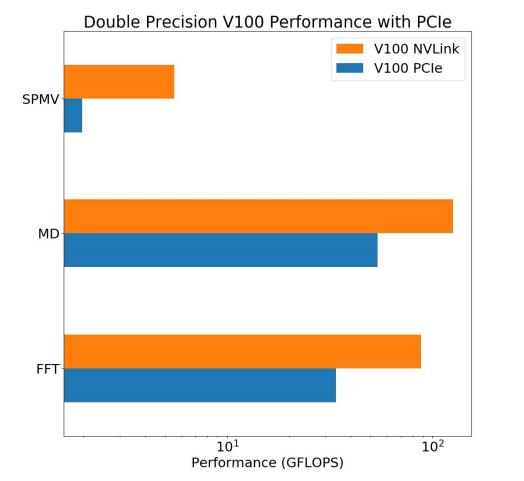
Overcoming limitations of GPGPU computing in scientific applications
While GPU performance has improved steadily, the PCIe interconnect that connects the system host memory and the GPUs has not kept pace. In this article, written by a team from the Center for Scientific Communication and Visualization Research at University of Massachusetts Dartmouth, the authors explore two alternatives to limited PCIe bandwidth – Nvidia NVLink interconnects and zero-copy algorithms for shared memory heterogeneous system architecture (HSA) devices. Using benchmarks, they measure the performance of each device in various scientific applications.
Authors: Connor Kenyon, Glenn Volkema and Gaurav Khanna.

Resource contention-aware load balancing for large-scale parallel file systems
Sustaining parallel I/O performance is important to running scientific applications on HPC systems – I/O imbalance can reduce overall performance. In this paper, a team from Virginia Tech, University of Heidelberg and Oak Ridge National Laboratory discuss a potential solution – “iez,” an “end-to-end control plane where clients transparently and adaptively write to a set of selected I/O servers to achieve balanced data placement.” They evaluate their proposed system on an experimental cluster, finding large performance improvements.
Authors: Bharti Wadhwa, Arnab K. Paul, Sarah Neuwirth, Feiyi Wang, Sarp Oral, Ali R. Butt, Jon Bernard and Kirk W. Cameron.

Scaling training on HPC infrastructure for brain mapping
Mapping neurons in the human brain requires automatic reconstruction of entire cells from electron microscopy data. To do this, some researchers employ the flood-filling networks (FFN) architecture. In this paper, researchers from Argonne National Laboratory and the University of Chicago reduce the training time for these networks by implementing synchronous and data-parallel distributed training.
Authors: Wushi Dong, Hanyu Li, Murat Keceli, Corey Adams, Bobby Kasthuri, Peter Littlewood, Rafael Vescovi, Tom Uram and Nicola Ferrier.
Using modular FPGA acceleration of data analytics in heterogeneous computing
Emerging intensive cloud applications like machine learning and big data analytics increasingly require high-performance computing systems, and many cloud operators have responded to these needs by deploying FPGAs – increasing programming complexity. In this paper, written by a team from Greece and Spain, the authors present a modular approach for accelerating data analytics using FPGAs, allowing for automatic development of integrated hardware designs.
Authors: Elias Koromilas, Christoforos Kachris, Dimitrios Soudris, Francisco J. Ballesteros, Patricio Martinez and Ricardo Jimenez-Peris.
 Assessing the performance impacts of Intel Skylake-SP processors’ energy efficiency features
Assessing the performance impacts of Intel Skylake-SP processors’ energy efficiency features
The majority of HPC systems use Intel x86 processors. In this paper, a team from Technische Universität Dresden analyze the effects of the hardware-controlled energy efficiency features of the Intel Skylake-SP processor. They present a series of findings, including that certain latencies increased significantly compared to the Haswell generation and that data can significantly impact power consumption, causing an error in energy models.
Authors: Robert Schöne, Thomas Ilsche, Mario Bielert, Andreas Gocht and Daniel Hackenberg.
Using HPC for liquefaction hazard assessment for urban regions
Liquefaction – loose soil beneath groundwater losing strength during earthquakes – is a major source of earthquake damage. In this paper, the authors – a team from Japan – present a numerical simulation-based method for assessing urban liquefaction hazards, using HPC for efficient assessment and automatic modeling. Comparing it to conventional methods, the authors find that the conventional method predicted significantly more liquefied sites.
Authors: Jian Chen, Hideyuki O-tani, Tomohide Takeyama, Satoru Oishi and Muneo Hori.
 Deploying AI frameworks on secure HPC systems with containers
Deploying AI frameworks on secure HPC systems with containers
With AI increasingly requiring HPC to efficiently scale complex algorithms, researchers and developers are attempting to bridge the gap between data scientists – who usually develop their applications with languages or frameworks like TensorFlow – and HPC environments. In this paper, the authors discuss the difficulties associated with deploying AI frameworks in secure HPC environments and illustrate how they successfully deploy those frameworks on SuperMUC-NG using Charliecloud.
Authors: David Brayford, Sofia Vallecorsa, Atanas Atanasov, Fabio Baruffa and Walter Riviera.
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.


























































