 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
If you’ve ever flown on an airplane, driven a car, used a computer, touched a mobile device, crossed a bridge or put on wearable technology, chances are you’ve used a product that ANSYS software has played a critical role in creating. ANSYS® Fluent® is a general-purpose computational fluid dynamics (CFD) and multiphysics tool with an incredible range of capabilities for physical modeling needed to model turbulence, heat transfer, flow and reactions for industrial applications.
Fluent already solves the toughest design challenges with well-validated results across the widest range of CFD and multiphysics applications. But, today, engineers need to accomplish more in less time. They depend on high-performance computing (HPC) for faster, high-fidelity results offering greater performance insight. With more complex models and simulations pushing the boundaries of hardware, delivering faster solutions that demonstrate a clear competitive advantage is an absolute must for today’s savvy businesses. Mellanox and ANSYS have an ongoing partnership to deliver exceptional performance for customers.
InfiniBand and In-Network Computing
By delivering the fastest data speed, lowest latency, smart accelerations and highest efficiency, InfiniBand is the best choice to connect the world’s top HPC and artificial intelligence supercomputers. It is also the clear networking solution for maximizing scalable performance with Fluent. Mellanox and ANSYS have a long-standing collaboration to offer best-of-breed solutions that enable exceptional scalable performance for the most demanding CFD workloads.
Computational fluid dynamics is extremely performance-driven. It demands the highest bandwidth, ultra-low latency and native CPU offloads, including RDMA, to get the highest server efficiency and application productivity at scale. Mellanox InfiniBand delivers the highest bandwidth and lowest latency of any standard interconnect, enabling CPU efficiencies of greater than 95%.
InfiniBand In-Network Computing technology includes Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™, an R&D100 award-winning technology which executes data reduction algorithms on network devices instead of on host-based processors. It also includes other offload capabilities such as hardware-based tag-matching, rendezvous protocol and more. These technologies are in use at several of the recently deployed large-scale supercomputers around the world, including many of the top TOP500 platforms.
Mellanox HPC-X™ ScalableHPC™ MPI Suite
Mellanox HPC-X is an accelerated MPI implementation based on the open source OpenMPI. This fully featured and tested MPI is optimized for InfiniBand or RDMA over Converged Ethernet (RoCE) and supports other standards-based interconnects. Furthermore, Mellanox HPC-X takes advantage of the advanced offload acceleration engines available in the InfiniBand hardware, including the latest In-Network Computing capabilities, to maximize application performance. HPC-X supports the Unified Communication X (UCX) framework, which is an open source framework developed by the UCF consortium. This collaboration between industry, laboratories and academia is driving the next-generation communication framework for high-performance computing applications. UCX serves as the MPI point-to-point accelerated engine within HPC-X. Additionally, Hierarchical Collectives (HCOLL) comprises a collective acceleration engine library that implements Mellanox SHARP technology and other enhanced algorithms to accelerate application performance.
CFD simulations are communication-latency sensitive. HPC-X significantly increases the scalability and performance of message communications in the network, unlocking system performance and freeing the CPU to work on the application, not communication overhead.
HPC-X is free to download and use, so you can rapidly deploy and deliver maximum application performance without the complexity and costs of licensed third-party tools and libraries.

ANSYS and Mellanox: Delivering the Exceptional CFD Solution
The ANSYS benchmark suite provides Fluent hardware performance data measured using sets of benchmark problems selected to represent typical usage. The Fluent benchmark cases range in size from a few hundreds of thousands of cells to more than 100 million cells. The suite contains both pressure-based (segregated and coupled) and density-based implicit solver cases using a variety of cell types and a range of physics. These cases are used by hardware vendors to benchmark their hardware systems.
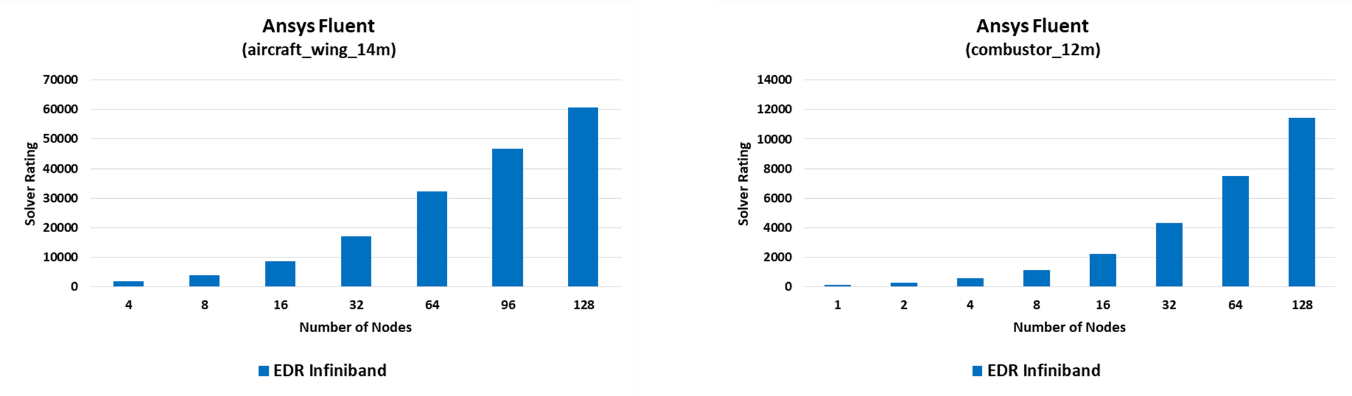

With the broad coverage and scope of the ANSYS Fluent benchmarking suite, the combination of Fluent, Mellanox InfiniBand hardware and HPC-X MPI delivers superior scalable performance and a clear competitive advantage across a wide range of large, complex problem sizes. This will ultimately enable Fluent users to simulate larger, high-fidelity models without having to expand their cluster nodes. In addition, their current models can now keep on scaling into higher node counts, mitigating the levelling off of performance which had been seen on OpenMPI-based clusters.
Additional Resources:
Mellanox https://www.mellanox.com
Mellanox HPC-X https://www.mellanox.com/page/hpcx_overview
Unified Communication X https://openucx.org
ANSYS Fluent https://www.ansys.com/products/fluids/ansys-fluent
ANSYS Fluent Benchmarks https://www.ansys.com/solutions/solutions-by-role/it-professionals/platform-support/benchmarksoverview/ansys-fluent-benchmarks

























































