 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this bimonthly feature, HPCwire highlights newly published research in the high-performance computing community and related domains. From parallel programming to exascale to quantum computing, the details are here.
 Autotuning exascale applications with multitask and transfer learning
Autotuning exascale applications with multitask and transfer learning
Autotuning (where operators automatically find optimal performance parameters for an application) is critical as computing scales up. In this paper, the researchers discuss the use of machine learning – specifically, multitask and transfer learning – to enhance this process. They compare their results to state-of-the-art autotuning methods, finding a 1.5x improvement compared to some popular approaches. The researchers highlight how their approach might be preferable for applications generally and for exascale applications in particular.
Authors: Wissam M. Sid-Lakhdar, Mohsen Mahmoudi Aznaveh, Xiaoye S. Li and James W. Demmel
Comparing FPGAs and GPUs for radio-astronomical imaging
FPGAs have been gaining traction due to their benefits for energy efficiency in simple operations with high-speed data. These researchers – a duo from the Netherlands Institute for Radio Astronomy – demonstrate implementation and optimization of a radio-astronomical imaging application on an Arria 10 FPGA. Comparing their results to GPU and CPU implementations, they find that optimizing for a high clock speed on the FPGA is difficult, but argue that recent developments in FPGAs have made them viable accelerators for complex HPC applications.
Authors: Bram Veenboer and John W. Romein
 Conducting system evaluation of the Intel Optane byte-addressable NVM
Conducting system evaluation of the Intel Optane byte-addressable NVM
Byte-addressable non-volatile memory (NVM) has quickly become a major player in the memory world thanks to high density, strong performance and persistence; however, has asymmetric read-write performance and comparatively high write energy. In this paper, written by a team from Lawrence Livermore National Laboratory (LLNL), the authors describe their in-depth evaluation of the first commercially available byte-addressable NVM (the Intel Optane DC persistent memory). Among other conclusions, the researchers find that augmenting NVM with DRAM is essential and produces “reasonable performance with higher capacity.”
Authors: Ivy B. Peng, Maya B. Gokhale and Eric W. Green
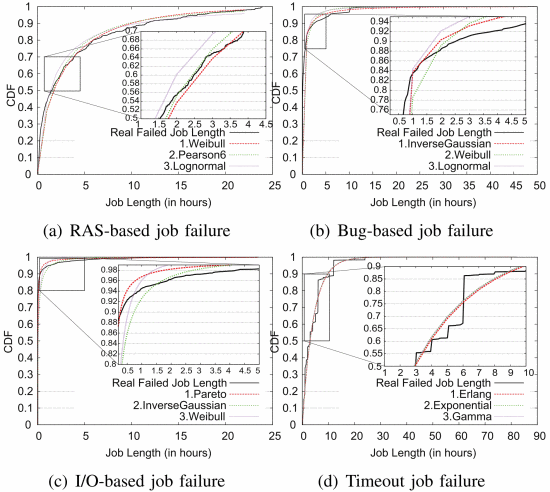 Understanding HPC job failures over the life of the IBM BlueGene/Q system
Understanding HPC job failures over the life of the IBM BlueGene/Q system
As supercomputing approaches the exascale era, failures become more frequent and more impactful. This paper – written by a team from Argonne National Laboratory and the University of Illinois at Urbana-Champaign – examines the system events of the IBM BlueGene/Q Mira supercomputer over the course of 2,001 days and more than 32 billion core-hours. They find correlations between job failures and multiple metrics and attributes, and characterize the distribution of failures.
Authors: Sheng Di, Hanqi Guo, Eric Pershey, Marc Snir and Franck Cappello
Accelerating scientific deep learning models on heterogeneous computing with Intel FPGAs
“Traditional CPU-based sequential computing can no longer meet the requirements of mission-critical [AI and deep learning] applications,” these authors write. In this paper, they explore the use of FPGAs to accelerate the inferencing stage of the heterogeneous computing workflow. They present case studies and results in state-of-the-art models for scientific data analysis, accelerating them between three and six times compared to a single-core Skylake CPU.
Authors: C. Jiang, D. Ojika, T. Kurth, P. Prabhat, S. Vallecorsa, B. Patel and H. Lam
 Securing HPC using federated authentication
Securing HPC using federated authentication
Federated authentication – essentially, integrating with individual user accounts across organizations – “can drastically reduce the overhead of basic account maintenance while simultaneously improving overall system security,” argue the authors of this paper (a team from the MIT Lincoln Laboratory). They describe their experiences and lessons learned by enabling federated authentication for the user base of a production HPC system for the U.S. Government PKI and InCommon Federation.
Authors: Andrew Prout, William Arcand, David Bestor, Bill Bergeron, Chansup Byun, Vijay Gadepally, Michael Houle, Matthew Hubbell, Michael Jones, Anna Klein, Peter Michaleas, Lauren Milechin, Julie Mullen, Antonio Rosa, Siddharth Samsi, Charles Yee, Albert Reuther and Jeremy Kepner
Addressing data management challenges in exascale scientific simulations
With the advent of multi-petascale supercomputers, the gap between computing power and I/O has grown wider for science applications running complex simulations, creating an I/O bottleneck. In this paper, a team from Oak Ridge National Laboratory (ORNL) and the University of California Irvine, presents initial I/O results of running Gyrokinetic Toroidal Code (GTC) on the Summit supercomputer at ORNL, then discusses optimizations utilized to improve I/O performance and identify future challenges.
Authors: Lipeng Wan, Kshitij V. Mehta, Scott A. Klasky, Matthew D. Wolf, H.Y. Wang, W.H. Wang, J.C. Li and Zhihong Lin
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.
























































