 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
MLPerf.org, the young AI-benchmarking consortium, today issued the first round of results for its inference test suite. Among organizations with submissions were Nvidia, Intel, Alibaba, Supermicro, Google, Huawei, Dell and others. Not bad considering the inference suite (v.5) itself was just introduced in June. Perhaps predictably, GPU powerhouse Nvidia quickly claimed early victory issuing a press release coincident with the MLPerf announcement – “NVIDIA today posted the fastest results on new benchmarks measuring the performance of AI inference workloads” – though without much detail.
Actually, navigating the results takes some effort because of the diversity of systems (cloud to servers to mobile devices) and accelerators (GPUs, FPGA, DPS, TPUs, ASICs) covered. Along with the results, MLPerf issued detailed paper explaining the benchmark just as it did for its training test suite. Noteworthy, organizations perform their own testing using the MLPerf suite and results are validated as part of that process. Among accelerators used by systems tested were Nvidia T4s, Arm variants, Habana’s Goya inference processor, Alibaba’s HanGuang, the Hailo8 chip, and others.
Making apples to apples comparisons requires some effort. Different form factors, system sizes, CPU and accelerator counts, frameworks used, all matter. Of the over 500 benchmark results released today, 182 are in the so-called Closed Division (defined below[i]) intended for direct comparison of systems. The results span 44 different systems. The benchmarks show a five-order-of-magnitude difference in performance and a three-order-of-magnitude range in estimated power consumption and range from embedded devices and smartphones to large-scale data center systems. The remaining 429 open results are in the Open Division and show a more diverse range of models, including low precision implementations and alternative models.
 As you can see digging out meaningful results will take some work. One of the more accessible comparisons is looking at accelerator performance differences, said David Kanter, co-chair of the MLPerf inference working group, in a pre-briefing with HPCwire, “With respect to the number of accelerators [in a system], one of the things is that [they are] explicitly parallel. So, in some sense, the performance per chip should be the same whether you have 8, 20, 4, or one accelerators. In many respects, I think the way I conceptualize these results is to look at it on a performance per chip basis.”
As you can see digging out meaningful results will take some work. One of the more accessible comparisons is looking at accelerator performance differences, said David Kanter, co-chair of the MLPerf inference working group, in a pre-briefing with HPCwire, “With respect to the number of accelerators [in a system], one of the things is that [they are] explicitly parallel. So, in some sense, the performance per chip should be the same whether you have 8, 20, 4, or one accelerators. In many respects, I think the way I conceptualize these results is to look at it on a performance per chip basis.”
Wearing his MLPerf neutral hat, Kanter was reluctant to say much about particular entries but did say, “I was impressed with the number of early prototypes and experimental systems. We specifically designed the open division for this purpose, so it was great to see people who were experimenting with ultra-low latency, reduced precision, and other novel techniques that will push the industry forward.”
It’s best to spend time with the spreadsheet to answer particular questions.
MLPerf first jumped into the AI benchmarking arena with a training test suite in May of 2018 and has issued two rounds of public results since, the most recent in July. Today’s release of inferencing test results, posted on MLPerf.org, was a long-planned step on MLPerf’s roadmap and on schedule.
The v.5 inference test suite, acknowledged Kanter, is modest covering three tasks and uses five well-established models (see chart below):

“We chose tasks that reflect major commercial and research scenarios for a large class of submitters and that capture a broad set of computing motifs. To focus on the realistic rules and testing infrastructure, we selected a minimum-viable-benchmark approach to accelerate the development process. Where possible, we adopted models that were part of the MLPerf Training v0.6 suite, thereby amortizing the benchmark-development effort,” reports MLPerf.
Four different test scenarios are employed and each has somewhat different metric. Here’s an excerpt, lightly edited, from the MLPerf paper describing the them with a chart below.
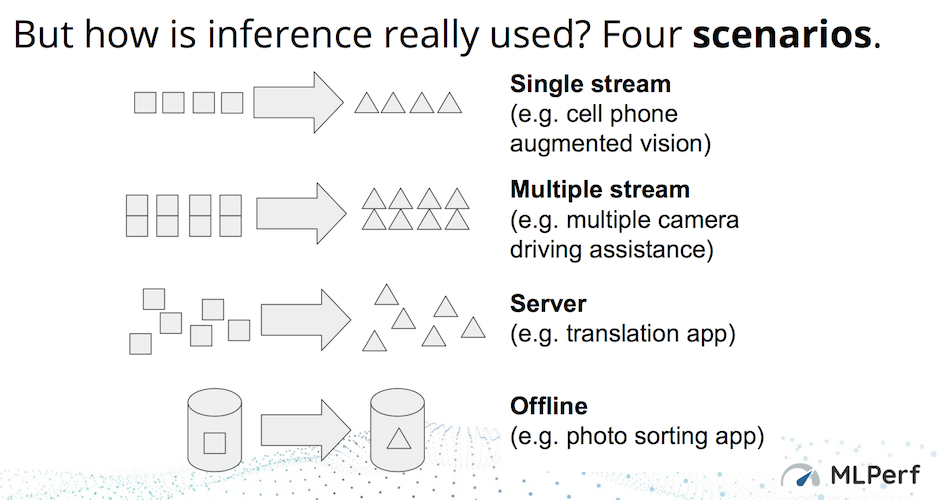 Single-stream. It represents one inference-query stream with a query sample size of one, reflecting the many client applications where responsiveness is critical. An example is offline voice transcription on Google’s Pixel 4 smartphone. To measure performance, the LoadGen injects. The performance metric is the integer number of streams that the system supports while meeting the QoS requirement.
Single-stream. It represents one inference-query stream with a query sample size of one, reflecting the many client applications where responsiveness is critical. An example is offline voice transcription on Google’s Pixel 4 smartphone. To measure performance, the LoadGen injects. The performance metric is the integer number of streams that the system supports while meeting the QoS requirement.- Multistream. It represents applications with a stream of queries, but each query comprises multiple inferences, reflecting a variety of industrial-automation and remote-sensing applications. For example, many autonomous vehicles have six to eight cameras streaming simultaneously and analyze the set of frames for hazards. The performance metric is the integer number of streams that the system supports while meeting the QoS requirement.
- Server. It represents online server applications where query arrival is random and latency is important. Almost every consumer-facing website is a good example of this scenario, including services such as online translation from Baidu, Google, and Microsoft. The server scenario’s performance metric is the Poisson parameter that indicates the queries per second achievable while meeting the QoS requirement. The performance metric is the integer number of streams that the system supports while meeting the QoS requirement.
- Offline. It represents batch-processing applications where all the input data is immediately available and latency is unconstrained. An example is identifying the people and locations in a photo album. The metric for the offline scenario is throughput measured in samples per second.
MLPerf submitters are also required to choose one of three categories for their entries: Available– basically systems one could use or buy (cloud and on-premise) in which the systems must use a “publicly available software stack consisting of the software components that substantially determine ML performance but are absent from the source code.”; Preview– systems must “contain components that will meet the criteria for the available category within 180 days or by the next submission cycle, whichever is later,”; and Research & Development– prototype or proof of concept system with one or more R&D component. “These components submitted in one cycle may not be submitted as available until the third cycle or until 181 days have passed, whichever is later.”
The idea is to let potential users know the state of systems being tested and also offer technology providers the opportunity to showcase developing ideas. The first round of results in the closed division had 29 available submissions, five preview systems, and three in the R&D category.
 Talking about the inference testing challenge, Kanter noted, “The problem is that inference encompasses everything from 300 watt monster GPUs and accelerators down to 200 milliwatt smartphones and other low power chips. I was thrilled with the response [to this first benchmark]. We got a good variety of processors, DSPs, FPGAs, CPUs, and GPUs, so pretty much everything under the sun. The only things we’re missing are analog or neuromorphic chips [and currently] there’s no such thing as a neuromorphic processor that’s actually in production.”
Talking about the inference testing challenge, Kanter noted, “The problem is that inference encompasses everything from 300 watt monster GPUs and accelerators down to 200 milliwatt smartphones and other low power chips. I was thrilled with the response [to this first benchmark]. We got a good variety of processors, DSPs, FPGAs, CPUs, and GPUs, so pretty much everything under the sun. The only things we’re missing are analog or neuromorphic chips [and currently] there’s no such thing as a neuromorphic processor that’s actually in production.”
It’s not quite right to say, “let the AI benchmarking wars begin.” There are of course many AI benchmark efforts underway each with distinct strengths. That said, MLPerf is backed by a broad membership (~50) from industry and academia seems to have steadily gained traction as the AI community seeks a mechanism for comparing performance between various systems and components.
Training, of course, is generally the more compute intensive task in AI, but inferencing is the workhorse function and not only represents a larger market in terms of devices deployed but also a tremendous variety of deployment environments with widely ranging power requirements. MLPerf estimates over 100 companies are producing or are on the verge of producing optimized inference chips while only about 20 companies target training.
Kanter expects the release cadence to speed up. “Broadly speaking, the schedule that I’m anticipating is we believe we can do benchmark results once a quarter. And it’s going to alternate between training and inference. Long term, we’d love to move to a model that’s more like Spec where it’s just, you know, every week or so. Obviously because we got in around 600 results, we needed to review them all. If we can break up that work and make it so that you aren’t tied to our schedule, that would be great. There’s things that are missing, there’s things we know we need to fix, once we start getting more mature, I think it would be an interesting exercise to think about what would happen if we just allowed you to drop in your results whenever and see if that’s something that would really scale and work for us as an organization.”
It’s still early days for MLPerf much as it is for the AI renaissance generally taking hold. Stay tuned
 Submitters are also required enter in one of two ‘divisions’ (descriptions from the inference paper):
Submitters are also required enter in one of two ‘divisions’ (descriptions from the inference paper):
Closed division. “The closed division enables comparisons of different systems. Submitters employ the same models, data sets, and quality targets to ensure comparability across wildly different architectures. This division requires pre-processing, post-processing, and a model that is equivalent to the reference implementation. It also permits calibration for quantization (using the calibration data set we provide) and prohibits retraining.”
Open division. “The open division fosters innovation in ML systems, algorithms, optimization, and hardware/software co-design. Submitters must still perform the same ML task, but they may change the model architecture and use different quality targets. This division allows arbitrary pre- and post-processing and arbitrary models, including techniques such as retraining. In general, submissions are not directly comparable with each other or with closed submissions. Each open submission must include documentation about how it deviates from the closed division. Caveat emptor!”


























































