 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Data latency or bandwidth (latency of large data messages) is one of the key elements responsible for applications performance and scalability as we all know. The lower the latency, the better the performance we can gain. Latency can be measured on a non-loaded (aka empty) cluster system or on a loaded system. This article addresses latency measurements of the first case, since it is important for understanding the latency an application will incur with a single job running. The second case of multiple applications sharing the same cluster simultaneously will be addressed in a future article.
The challenge of reducing data transfer latency has been going through multiple technology development phases – from reducing network latency to reducing complex data operations latencies. InfiniBand, the leading interconnect for high performance and data intensive applications, demonstrates extremely low latency today, with switch latencies close to 100ns, and an end-to-end latency of less than 1usec (end-point to end-point). The effort of reducing the latency of complex data operations involves adding new hardware and software technologies.
These hardware enhancements are referred to as In-Network Computing, reflecting additional dedicated or configurable computation engines embedded in the network devices. Two examples include the Mellanox Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™ and Mellanox MPI hardware Tag Matching technologies. Mellanox SHARP is based on dedicated compute engines located on the InfiniBand switch data path dedicated for performing data reduction and aggregation operations; and the hardware-based MPI matching engines are part of the InfiniBand adapters. These two technologies enable dramatic reduction in the latency of MPI, SHMEM/PGAS and other programming models operations, and to maintain low latencies regardless of clusters sizes.
Figure 1 below shows a comparison of MPI latency (OSU MPI benchmark) and MPI Random Ring latency between EDR InfiniBand, Aries and Slingshot, demonstrating the InfiniBand latency advantage over previous and next generations of competitive proprietary networks.
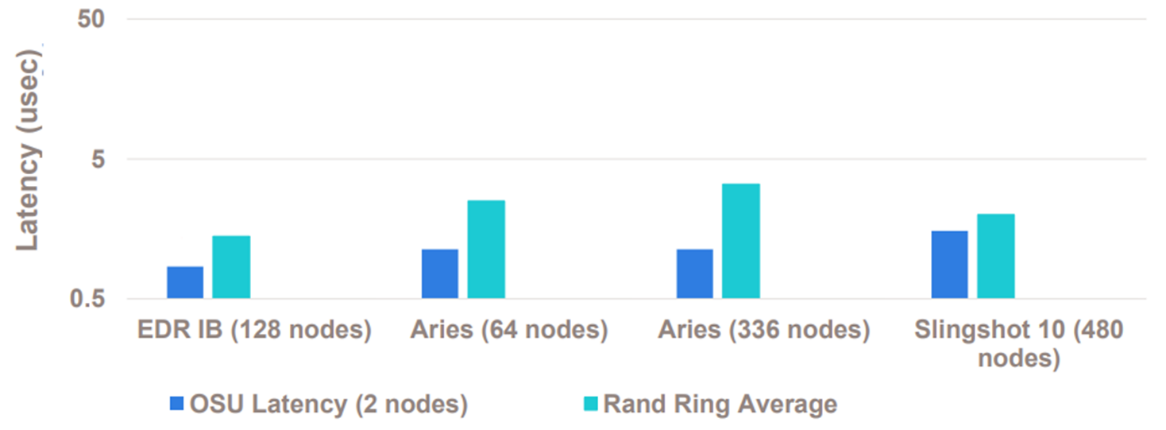
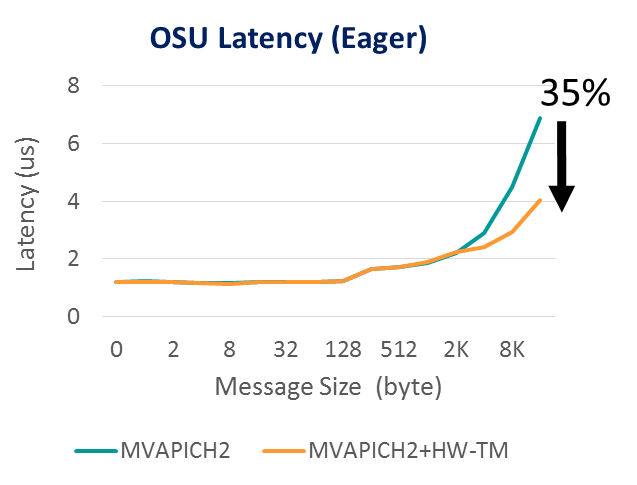
Figure 2 shows MPI latency based on the OSU MPI benchmark, demonstrating the latency advantage gained through Mellanox MPI Tag Matching technology (HW-TM in the figure) – a 35% reduction in MPI latency.
Beyond the latency reduction that is obtained by performing MPI Tag Matching operations at the network level, it is also possible to increase communication-to-computation overlap. Communication-computation-overlap refers to the ability for computation to progress asynchronously as the CPU is being used for application computational tasks.. The higher the overlap the better the system utilization. Figure 3 demonstrates close to 100% overlap between communication and computations of the MPI_lscatterv operations, leveraging Mellanox Tag Matching technology (HW-TM in the figure). The test was conducted on the Frontera supercomputer at Texas Advanced Computing Center.

There are multiple publications regarding ’Mellanox’s SHARP In-Network Computing technology and its performance advantages for high performance and deep learning applications. Mellanox SHARP supports both low-latency data reductions and large data reductions, also referred to as streaming data aggregation. Figure 4 provides a clear demonstration of Mellanox SHARP In-Network Computing technology advantage. Compared to software-based implementations, Mellanox SHARP technology not only yields lower latency, but also maintains a nearly flat latency profile across cluster sizes.
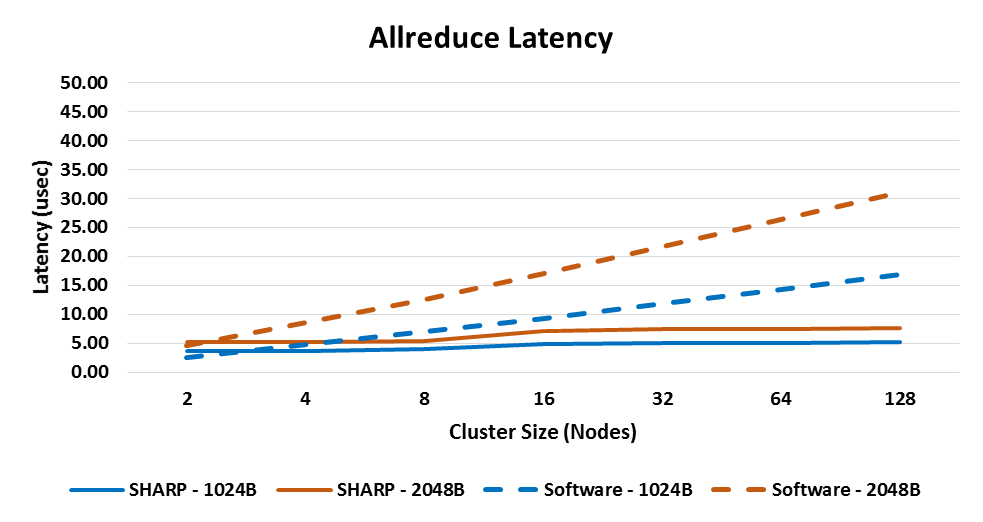
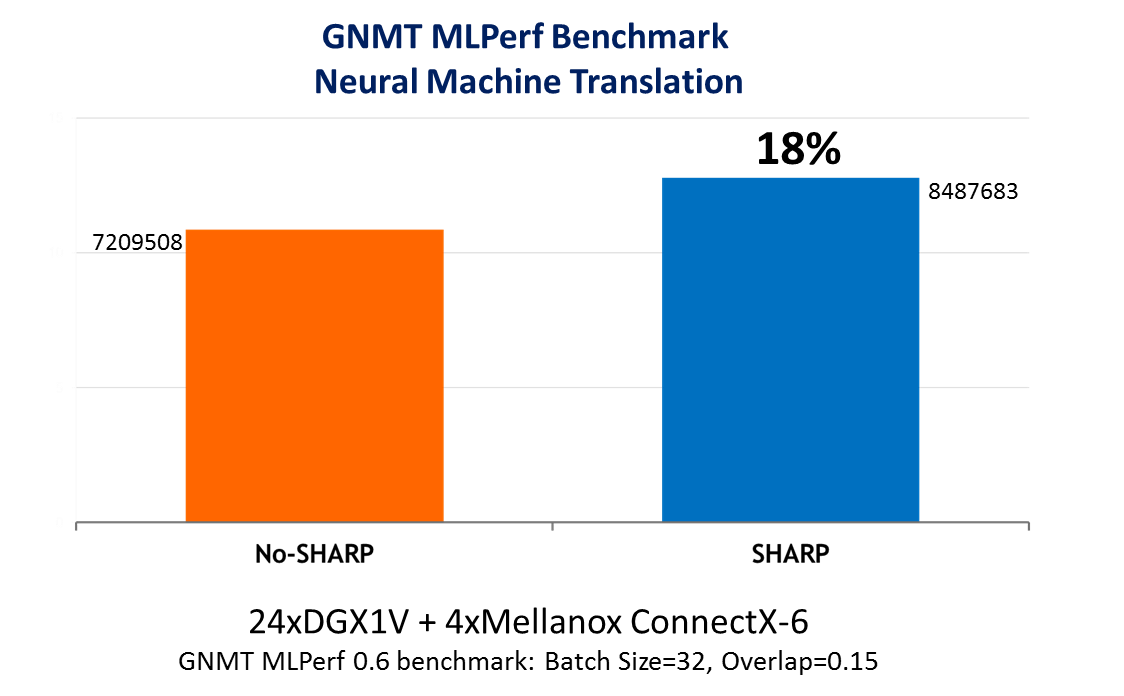
Figure 5 demonstrates another of Mellanox SHARP advantages. A GNMT MLPerf benchmark for neural machine translation was run using NVIDIA Collective Communications Library (NCCL) version 2.4 with and without Mellanox SHARP, over 24 NVIDIA DGX systems and Mellanox InfiniBand interconnect. As can be seen in the figure, leveraging Mellanox SHARP results in a nearly 20% performance gain.
One of the main factors influencing performance of compute and data intensive parallel applications is the latency of network transfer operations. InfiniBand addresses the latency challenge in a two-fold approach: on the one hand it provides extremely low network latency, and on the other hand introduces smart In-Network Computing engines to improve the latency of complex data operations, such as those used by high performance or deep learning communication frameworks. These advantages set InfiniBand apart as the leading interconnect solution for today’s and future supercomputing platforms.


























































