 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this bimonthly feature, HPCwire highlights newly published research in the high-performance computing community and related domains. From parallel programming to exascale developments to quantum computing, the details are here.
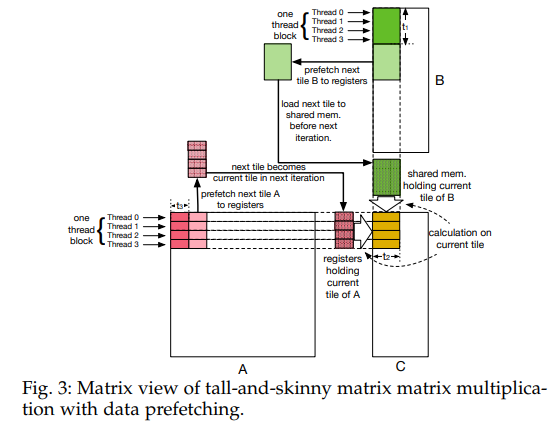 Optimizing irregular-shaped matrix-matrix multiplication on GPUs
Optimizing irregular-shaped matrix-matrix multiplication on GPUs
Linear algebra is a common application in big data and computational science on HPC. These operations are well-optimized when handling regularly shaped matrix inputs with GPUs, but comparatively little literature has discussed irregularly shaped matrix inputs with GPUs. In this paper (written by a team from the University of Alabama, Oak Ridge National Laboratory, the University of California, Riverside, and the University of Sydney), the authors propose two matrix-matrix multiplication algorithms for irregularly shaped inputs on GPUs. They demonstrate a speedup of up to 3.5x along with greater efficiencies in resource usage.
Authors: Cody Rivera, Jieyang Chen, Nan Xiong, Shuaiwen Leon Song and Dingwen Tao.
Accelerating pre-exascale application development
As HPC trends toward heterogeneous architectures, application development is becoming more and more difficult. This paper, written by a team from a wide range of organizations (but mostly Oak Ridge National Laboratory), discusses experiences from the Oak Ridge Leadership Computing Facility (OLCF) in preparing application development efforts for Summit, which is currently the world’s fastest publicly-ranked supercomputer. The authors present lessons learned from early adoption of a range of scientific applications on Summit in order to inform future application development for heterogeneous HPC systems.
Authors: Lixiang Luo, Tjerk P. Straatsma, Luis E. Aguilar Suarez, Ria Broer, Dmytro Bykov, Ed F. D’Azevedo, Shirin S. Faraji, Kalyana C. Gottiparthi, Coen De Graaf, Austin Harris, et al.
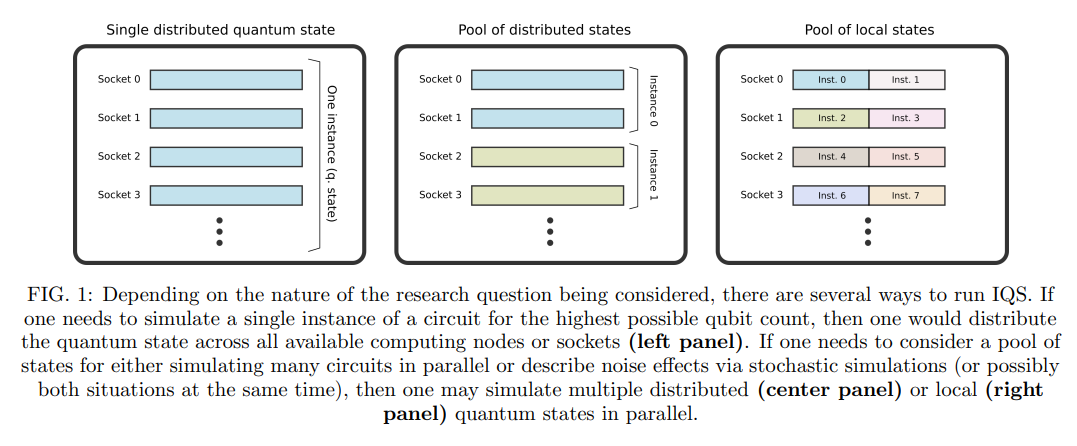 Developing a cloud-ready, high-performance simulator of quantum circuits
Developing a cloud-ready, high-performance simulator of quantum circuits
Simulating quantum computers continues to be crucial to the ongoing development of quantum information science. These authors, a team from Intel, introduce the latest release of the Intel Quantum Simulator (IQS), which is able to leverage HPC and cloud computing infrastructures. The authors discuss how the IQS is able to operate in parallel across a cloud platform and highlight their emulation of many quantum devices running in parallel.
Authors: Gian Giacomo Guerreschi, Justin Hogaboam, Fabio Baruffa and Nicolas Sawaya.
Studying HPC workloads on a Huawei processor
With the rise of ARM-based processors in the HPC world, this study (conducted by a team from Shanghai Jiao Tong University and Princeton University) examines the HPC suitability of the Huawei Kunpeng 916 processor. While the processor was not designed for HPC, the authors evaluate it using a series of benchmarks, scientific kernels, mini-apps and a real-world application (GTC-P). They find that the Kunpeng 916 compares favorably to the Intel Xeon E5-2680v3/4, arguing that it provides “compelling performance” for memory-bound HPC applications.
Authors: Yi-Chao Wang, Jin-Kun Chen, Bin-Rui Li, Si-Cheng Zuo, William Tang, Bei Wang, Qiu-Cheng Liao, Rui Xie and James Lin.
Automating performance modeling of HPC applications using machine learning
Automation of performance modeling can assist in crucial HPC system operation functions, such as task management and job scheduling – however, the number of variables affecting application performance make performance modeling and prediction a challenging task. These authors, a team from the University of Science and Technology of China and Texas Tech University, describe their work to automatically predict the execution time of parallel programs using a machine learning approach and an instance-transfer learning method. They find that their method performs well, with an average prediction error less than 20 percent.
Authors: Jingwei Sun, Guangzhong Sun, Shiyan Zhan, Jiepeng Zhang and Yong Chen.
 Implementing a neural network interatomic model for emerging exascale architectures
Implementing a neural network interatomic model for emerging exascale architectures
Current trends in molecular dynamics simulations revolve around neural network and machine learning models, alongside novel hardware such as GPUs. However, these models perform poorly relative to current models due to their relative suitability for larger (i.e. exascale) systems. These authors – a trio from Purdue University and Lawrence Livermore National Laboratory – reimplemented a neural network interatomic model in a molecular dynamics proxy application built for performance portability. The authors discuss this implementation and other opportunities for improving the performance portability of neural network interatomic models, such as choosing the correct level of parallelism and data layout.
Authors: Saaketh Desai, Samuel Temple Reeve and James F. Belak.
Running parallel genetic algorithms with GPU computing
Genetic algorithms use a form of mathematical “natural selection” to solve optimization problems in a wide range of fields. This paper, written by John Runwei Cheng and Mitsuo Gen, explores the use of GPUs to accelerate parallel genetic algorithms, highlighting the performance effects of data layout and thread organization. The authors discuss future research and propose a hybrid parallel model for hyper-scale problems.
Authors: John Runwei Cheng and Mitsuo Gen
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.
























































