 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The first months of 2020 were dominated by weather and climate supercomputing news, with major announcements coming from the UK, the European Centre for Medium-Range Weather Forecasts and the U.S. National Oceanic and Atmospheric Administration. Richard Loft, director of technology development at the Computational Information Systems Laboratory of the NSF-supported National Center for Atmospheric Research (NCAR), took the (virtual) stage at Nvidia’s GTC 2020 to highlight NCAR’s progress in moving weather and climate supercomputing into the exascale era.
![]() Specifically, Loft discussed NCAR’s Model for Prediction Across Scales (MPAS), its latest-generation weather model. MPAS, developed in partnership with Los Alamos National Laboratory, is the basis for the Global High-Resolution Forecasting System (GRAF) introduced last year by IBM and its subsidiary The Weather Company and running in production since October. Loft, who noted that the team was funding-limited and relied heavily on student support, called GRAF the “crowning achievement” of MPAS so far.
Specifically, Loft discussed NCAR’s Model for Prediction Across Scales (MPAS), its latest-generation weather model. MPAS, developed in partnership with Los Alamos National Laboratory, is the basis for the Global High-Resolution Forecasting System (GRAF) introduced last year by IBM and its subsidiary The Weather Company and running in production since October. Loft, who noted that the team was funding-limited and relied heavily on student support, called GRAF the “crowning achievement” of MPAS so far.
“This partnership between NCAR, IBM and the Weather Company,” Loft said, “has put into production a model with three-kilometer resolution over lots of areas in the world – and especially the developing world – where they haven’t had those kinds of resolutions before.” These new capabilities, he said, would enable significantly enhanced weather forecast products for those underserved areas.
And, crucially: “[GRAF] is the first GPU-based global forecast model, to my knowledge, in production anywhere in the world at this point.”
The goals for MPAS
In his talk, Loft outlined the objectives NCAR is aiming for with MPAS as the computing world approaches the exascale era – and how load balancing between GPUs and CPUs factors into those objectives, with GPUs becoming an increasingly important part of many major supercomputers. “So when we started this over three years ago,” Loft said, “we started looking at it from the perspective of trying to achieve a number of core capabilities for this model.”
First was performance portability. “We wanted to get the best performance on GPUs we could, but we wanted to maintain performance on CPUs,” Loft said. “We didn’t want to sacrifice that, because that’s our bread and butter.”
Second was resilience. “We needed to have a strategy for load-balancing all the code on the hybrid node,” he explained, “in such a way that it wasn’t too hard-wired for any one combination of CPU and GPU.”
Finally, the researchers wanted to port the minimum amount of code. For this, Loft said, they “triaged” the process. They ported most of the physics and dynamics code to the GPUs (using OpenACC), but left the radiation code (which accounts for the transfer of solar radiation through the atmosphere) as a CPU-only code. They made this choice, Loft explained, because the radiative code was over 30,000 lines. Radiation, Loft said, was “expensive”: “If you called it every timestep, the model would grind to a stop.” Fortunately, radiation also evolved on a much slower timescale, so operating it asynchronously from the rest of the model was sensible on a sheer physical level.
The researchers also left the included land surface model – which accounts for water and energy transfers between land and the atmosphere – as a CPU-only model, since it was over 20,000 lines of “branchy code” and didn’t take much time to run (unfortunately, though, Loft said, it had to be run synchronously).
Tinkering to perfection on two powerful supercomputers

To optimize its newly ported model, NCAR turned to a pair of supercomputers. First was NCAR’s own Cheyenne system, which houses 4,032 nodes (each with Intel Xeon Broadwell processors), an aggregate 313 TB of memory, connected by Mellanox EDR InfiniBand. Second was Summit at Oak Ridge National Laboratory, housing 4,608 nodes (each with two IBM Power9 CPUs and six Nvidia Volta GPUs), over 10 PB of memory, tied together with EDR InfiniBand.
At 4.8 and 148.6 Linpack petaflops, Cheyenne and Summit respectively placed 44th and 1st on the most recent Top500 list of the world’s most powerful publicly ranked supercomputers. The two systems were carefully selected: Cheyenne was selected for its CPU-only homogeneous design, while Summit offered a glimpse into the future of heterogeneous, GPU-heavy system design. Summit also bore similarity to GRAF’s IBM Power9-based supercomputer, which features 84 nodes with four Nvidia V100 GPUs each.
The supercomputers were employed to help NCAR find the “Goldilocks zone” for resource allocation. When allocating CPU cores and/or GPUs to either the radiation or the dynamics or the radiation, a mismatch in the timing could lead to serious losses of time and money. Allocate too little to radiation on the CPUs, for instance, and the GPUs powering integration (the remainder of the model) would have to pause their work while waiting for the CPUs to catch up.

For the tests, the researchers leveraged 76 CPU nodes on Cheyenne and 76 hybrid nodes on Summit to run MPAS at a ten-kilometer resolution, throwing 81,920 points of analysis to each node on each system. They tested balances in CPU and GPU allocation, changes in symmetric multithreading and changes in the interval at which radiation was re-integrated into the model.
On Cheyenne, the researchers found that the system was integration-limited, performing relatively poorly on general model tasks – so, they assigned most of the cores on each CPU to the general model and very few to radiation (a 2:1 ratio). On Summit, meanwhile, they found that with the GPUs contributing massive amounts to the processing power, the system was radiation-limited. Eventually, the researchers found the best performance at a balance of 18 CPU cores (and the GPUs) dedicated to the integrated model, with 24 dedicated to radiation.
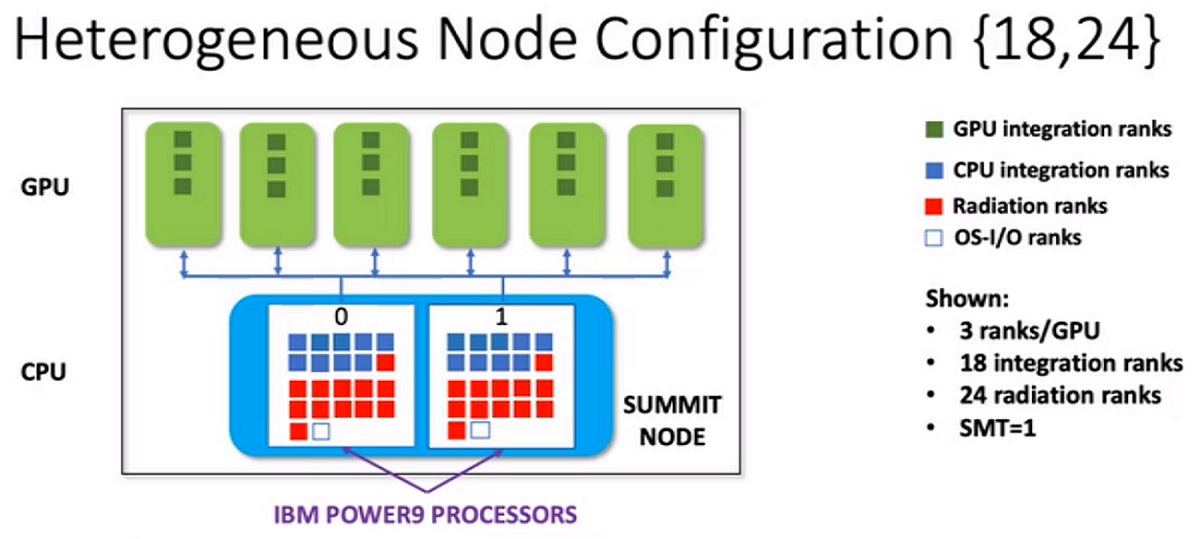
In addition to finding these settings for optimization, the researchers saw three times the throughput for MPAS when using GPU nodes compared to the CPU nodes. In terms of the frequency of re-integrating the radiation, Loft said that on Summit, they found that “there is insufficient CPU power to keep up with six GPUs unless the radiation [was] called pretty infrequently.”
The path forward
Next, the NCAR team will work on further optimizing message passing, as well as porting the land surface model to GPUs to free up even more cores for radiation processing. (Loft says that they’re considering porting the radiation code to GPUs, but only as a “last resort.)
While Loft acknowledges that there’s work to be done on scalability and throughput, he says the model is well on its way to being optimized. “It’s a work in progress, but we’ve got the full model working,” Loft said. “It’s a good first cut.”

























































