 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
MLPerf.org released its third round of training benchmark (v0.7) results today and Nvidia again dominated, claiming 16 new records. Meanwhile, Google provided early benchmarks for its next generation TPU 4.0 accelerator and Intel previewed performance on third-gen processors (Cooper Lake). Notably, the MLPerf benchmarking organization continues to demonstrate growth; it now has 70 members, a jump from 40 last July when training benchmarks were last released.
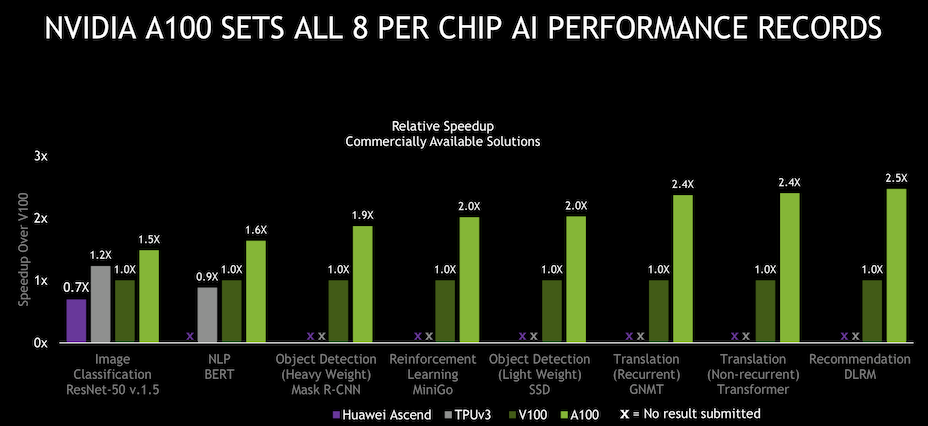
Fresh from the launch of its new A100 GPU in May and a top ten finish by Selene (DGX A100 SuperPOD) in June on the most recent Top500 List, Nvidia was able run the MLPerf training benchmarks on its new offerings in time for the July MLPerf release. Impressively, Nvidia set records for scaled out system performance and single node performance (see slides below).
“We were the only company to submit across all benchmarks with available systems,” said Paresh Kharya, senior director of product management, data center computing, Nvidia, in a press pre-briefing.
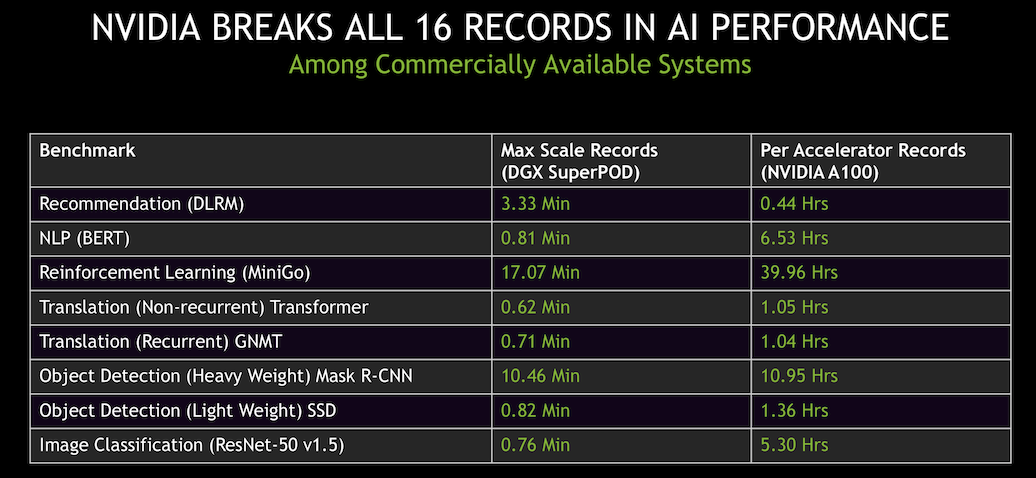
Kharya attributed much of the performance gain to improved software and work on the stack. “One of the big improvements we did was on the framework called MXnet. We added a capability called CUDA graphs. CUDA graphs was introduced a couple of years ago with CUDA 10. It’s basically a way to define operations that are repeated multiple times. Once so they can be executed and optimized directly on the GPUs. CPUs don’t have to issue instructions repeatedly,” he said.
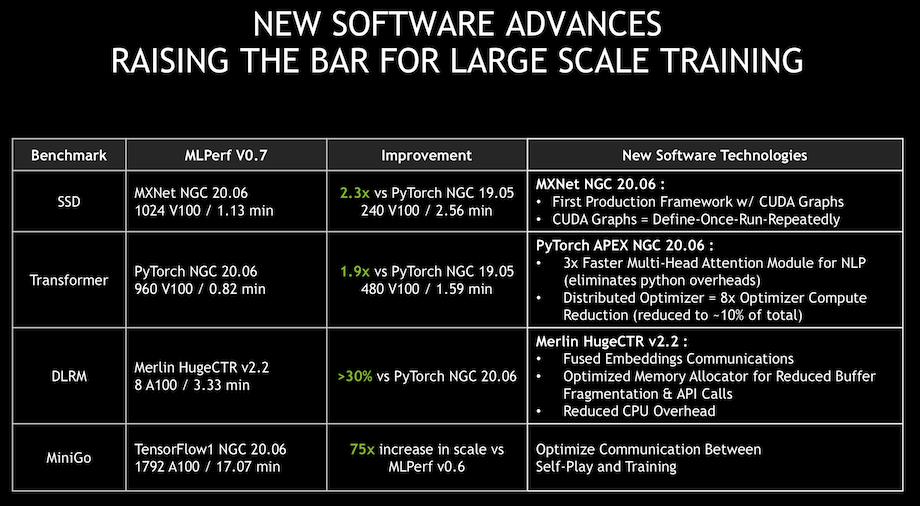
Parsing through MLPerf’s reported results can be challenging. It’s important to note that MLPerf has two divisions with various categories when interpreting results. Here’s MLPerf’s description:
“The Closed division is intended to compare hardware platforms or software frameworks “apples-to-apples” and requires using the same model and optimizer as the reference implementation. The Open division is intended to foster faster models and optimizers and allows any ML approach that can reach the target quality. MLPerf divides benchmark results into four Categories based on availability.
- Available In Cloud systems are available for rent in the cloud.
- Available On Premise systems contain only components that are available for purchase.
- Preview systems must be submittable as Available In Cloud or Available on Premise in the next submission round.
- Research systems either contain experimental hardware or software or available components at experimentally large scale.”
MLPerf reported the latest test round, “shows substantial industry progress and growing diversity, including multiple new processors, accelerators, and software frameworks. Compared to the prior submission round, the fastest results on the five unchanged benchmarks improved by an average of 2.7x, showing substantial improvement in hardware, software, and system scale. This latest training round encompasses 138 results on a wide variety of systems from nine submitting organizations.”
The MLPerf Training benchmark suite measures the time it takes to train one of eight machine learning models to a standard quality target in tasks including image classification, recommendation, translation, and playing Go. The latest version of MLPerf includes two new benchmarks and one substantially revised benchmark as follows:
- BERT: Bi-directional Encoder Representation from Transformers (BERT) trained with Wikipedia is a leading edge language model that is used extensively in natural language processing tasks. Given a text input, language models predict related words and are employed as a building block for translation, search, text understanding, answering questions, and generating text.
- DLRM: Deep Learning Recommendation Model (DLRM) trained with Criteo AI Lab’s Terabyte Click-Through-Rate (CTR) dataset is representative of a wide variety of commercial applications that touch the lives of nearly every individual on the planet. Common examples include recommendation for online shopping, search results, and social media content ranking.
- Mini-Go: Reinforcement learning similar to Mini-Go from v0.5 and v0.6, but uses a full-size 19×19 Go board, which is more reflective of research.
“The DLRM-Terabyte recommendation benchmark is representative of industry use cases and captures important characteristics of model architectures and user-item interactions in recommendation data sets,” stated Carole-Jean Wu, MLPerf Recommendation Benchmark Advisory Board Chair from Facebook AI.

Karl Freund, senior analyst, HPC and deep learning, Moor Insights & Strategy, was impressed with Nvidia’s performance gain. “4x [A100 improvement versus Nvidia V100] in 18 months is remarkable. And a big chunk of that comes from software improvements. What surprised me is the lack of serious competition, especially from Google and Intel. As for the startups, if they had a better result they would publish it. So they didn’t which means they don’t,” said Freund.
There were entries from Google, Shenzhen Institutes, Tencent, Alibaba, Dell EMC, Fujitsu, Inspur, Intel, and Nvidia across the various categories.
Freund seemed less impressed with Google’s TPU 4.0 showing – “it is only marginally better on 3 of the eight benchmarks. And it won’t be available for some time yet” – but Google struck a distinctly upbeat tone.
“Google’s fourth-generation TPU ASIC offers more than double the matrix multiplication TFLOPs of TPU v3, a significant boost in memory bandwidth, and advances in interconnect technology. Google’s TPU v4 MLPerf submissions take advantage of these new hardware features with complementary compiler and modeling advances. The results demonstrate an average improvement of 2.7 times over TPU v3 performance at a similar scale in the last MLPerf Training competition. Stay tuned, more information on TPU v4 is coming soon,” according to a Google blog posted today along with the figure below.

Intel’s entries were the only ones in the “Preview” category which requires that the products be available for testing in the the “Available” category by the next round. Single node, 2-node, 4-node, and 8-node Intel systems ran the benchmarks. Shenzhen Institutes had entries in several categories, all using the Huawei Ascend 910 AI-specialized processor launched roughly a year ago. Again, it’s best to review individual system/chip results directly from the MLPerf report.
Link to MLPerf announcement: https://mlperf.org/press
Link to MLPerf results: https://mlperf.org/training-results-0-7/
Link to Google blog: https://blog.tensorflow.org/2020/07/tensorflow-2-mlperf-submissions.html
Link to Nvidia blog: https://blogs.nvidia.com/blog/2020/07/29/mlperf-training-benchmark-records/
























































