 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The 2020 AI Hardware Summit kicked off yesterday with long-time computer luminary David Patterson digging into all things TPU and extolling on how they outrun GPUs for AI needs. After presenting data in which the TPUv3 bested Nvidia’s V100, he was asked about Google’s forthcoming TPUv4 versus Nvidia A100. Expect the same kind of advantage for TPUv4, he suggested.
With that the AI Hardware Summit was off and running.
It’s a virtual conference this year with two days this week and two more next week (link to conference). Other highlights on opening day included seasoned AI watcher Karl Freund’s (senior analyst, Moor Insights and Strategy) spotlight on 2019 and 2020 accelerator trends; startups SambaNova and Groq providing glimpses into their systems; and a pair of fascinating panels – one on AI use for chip design and another on AI compiler development. There was actually a good deal more going on and it’s best to check out the agenda.
Patterson, of course, is a familiar name in computing. He’s a UC Berkeley professor, a Google distinguished engineer, and the RISC-V Foundation Vice-Chair. His work at Google on TPU development is well-known.

As he recalled, “Google was one of the first people to get excited about both deep neural networks, and then domain specific architectures. In 2013, they calculated that if 100 million users started doing deep neural networks, three minutes a day on CPUs, they would have to double the size of the data center. Not only would that be very expensive, that would take forever to build twice as many data centers in the cloud. So they set an emergency project whose goal was to make a factor of 10 improvement over existing CPUs and GPUs.”
To some extent the rest is history as Google developed its tensor processor unit focusing on the AI needs of Google’s workload.
“Why was it successful? First of all, it an amazing number of arithmetic units. It has 256 by 256, arithmetic units, 64,000 multiply accumulators. Secondly, that they were doing work on eight-bit integer data rather than 32-bit floating data so it can be more energy efficient and take less memory capacity and be faster. And because it was domain specific, it dropped a lot of the general-purpose features that dominate CPUs and GPUs like caches and branch predictors. This saves area and energy in lets the transistors get reused. The legacy of TPU v1 is not only its technical excellence, but the impact it made,” said Patterson.
Lots of interesting choices were made along the way, for example how many cores should the new device have. “Where we went to [for] advice is Seymour Cray…and when we asked him, he said, “If you’re plowing a field, what would you rather use to strong oxen or 1024 chickens? So we went with two strong oxen so the TPUv2 has two cores per chip so it wouldn’t have a slower clock cycle.”

In addition to presenting more detail around the TPUv1-though-TPUv3 architecture, Patterson’s talk reinforced the idea designing domain specific chips (and tools) for AI comprise an increasingly formidable approach, likening the TPU’s success to a galvanizing proof point that’s now launching “1000 chips”.


“Let me conclude the slowing of Moore’s law means AI needs to tailor machines to be able to continue to make improvements in training and efforts. [A]ll the decisions you want to make are easier when it’s just for one domain rather than for general purpose. Despite using older technology and smaller chips, Google’s TPU v2 and v3 demonstrated a 50x performance improvement per watt versus general purpose supercomputers. I think the 2020s is a Cambrian era with all kinds of innovation, and exotic species, but which ones are going to flourish?”
Two such companies hoping to flourish are SambaNova and Groq.
SambaNova cofounder and CTO Kunle Olukotun walked briefly through its reconfigurable data flow architecture. Here’s brief excerpt from Olukotun’s remarks:
“We define a reconfigurable data flow architecture that’s optimized for data flow problems. So it takes these hierarchical pal (parallel) patterns and maps them to an architecture so they can be executed very efficiently. This is a reconfigurable architecture composed of reconfigurable compute, reconfigurable memory, and communication primitives that makes it very efficient to execute these sorts of data flow problems.
“The first incarnation of this reconfigurable Dataflow architecture is the Cardinal SN10 reconfigurable data flow unit (RDU). This is implemented in TSMC seven nanometer technology and 40 billion transistors. Over 50 kilometers of wire provide all the interconnect between the different components on the chip. It provides hundreds of teraflops of compute capability, and hundreds of megabytes of memory on chip. Just as importantly, it has different direct interfaces to terabytes of memory off chip. We’ve combined these RDU chips into systems that provide scalable performance for both training and inference. We call them data scale systems,” said Olukotun.


“When mapping data flow applications to the data scale system, a critical thing is to delicately balance computation and communication. If you look at conventional architectures, they allow you to program the computation, but they don’t allow you to program the communication and this is critical for getting efficient data flow. However, with reconfigurable dataflow, we are able to program the communication and the data flow, so that we can get a 10x improvement in performance on some applications. And we can enable applications that are not possible with current accelerator technology available in the form of GPUs.”
“We don’t expect the programmer to do this manually, we have a set of software called SambaFlow, which provides the capability to map these models very efficiently to our architecture. The idea is that the programmer can start either in one of the frameworks, PyTorch or TensorFlow, or they can provide their own graph of custom operations. If you start in one of the frameworks, then you’ll use a standard set of ML operations, and here we want to optimize the graph so that we can take advantage of both model parallelism and data parallelism. Then given a graph of operators, either custom operators or standard ML operators, we want to optimize the data flow in the graph. And this is done by number of different optimizations, such as tiling to improve the memory performance, exploiting parallelism within the operators, and then some very specific optimizations that that are specific to our architecture, such as streaming and nested pipelining.”
 Groq cofounder and CEO Jonathan Ross gave a somewhat less technical presentation, noting recent key funding milestones, the company’s expanding portfolio, and use cases. It’s Tensor Streaming processor is another AI chip that seeks to reduce some of the overhead (instructions) required to use general purpose microprocessors by physically moving and reorganizing functional elements (e.g. with needed memory and support located nearby).
Groq cofounder and CEO Jonathan Ross gave a somewhat less technical presentation, noting recent key funding milestones, the company’s expanding portfolio, and use cases. It’s Tensor Streaming processor is another AI chip that seeks to reduce some of the overhead (instructions) required to use general purpose microprocessors by physically moving and reorganizing functional elements (e.g. with needed memory and support located nearby).
Groq’s says its TSP is capable of 18,900 IPS (inferences per second) on ResNet-50 v2 at batch size one and says it the fastest commercially available AI/ML accelerator, with a responsiveness measured in hundredths of a millisecond.
Here’s a brief portion of the description of the architecture excerpted from a paper presented at IEEE’s 2020 International Symposium on Computer Architecture (link to paper):
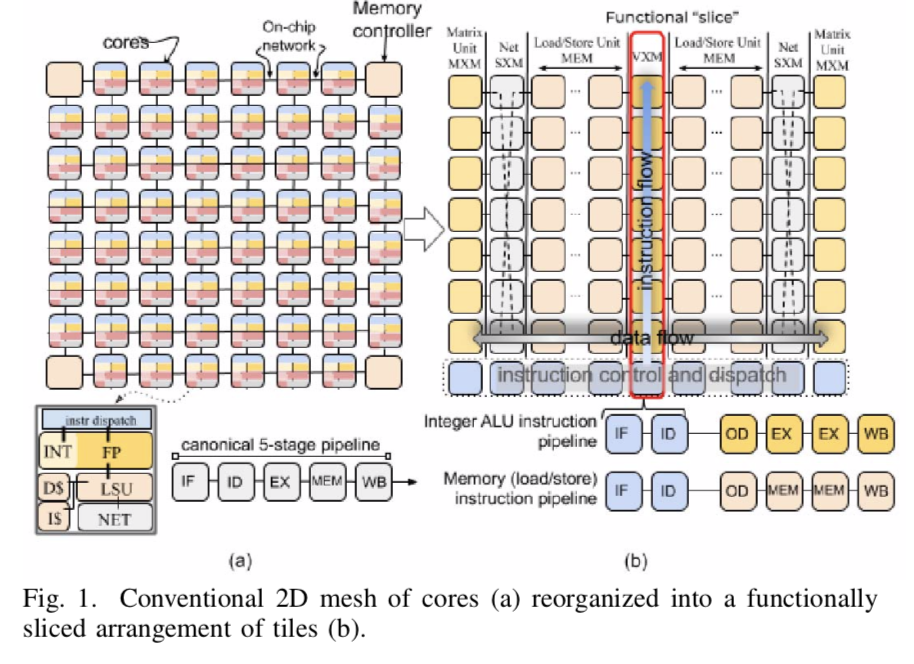
“To understand the novelty of our approach, consider the chip organization shown in Figure 1(a). In a conventional chip multiprocessor (CMP) each “tile” is an independent core which is interconnected using the on-chip network to exchange data between cores. Instruction execution is carried out over several stages: 1) instruction fetch (IF), 2) instruction decode (ID), 3) execution on ALUs (EX), 4) memory access (MEM), and 5) writeback (WB) to update the results in the GPRs. In contrast from conventional multicore, where each tile is a heterogeneous collection of functional units but globally homogeneous, the TSP inverts that and we have local functional homogeneity but chip-wide (global) heterogeneity.
“The TSP reorganizes the homogeneous two-dimensional mesh of cores in Figure 1(a) into the functionally sliced microarchitecture shown in Figure 1(b). In this approach, each tile implements a specific function and is stacked vertically into a “slice” in the Y-dimension of the 2D on-chip mesh. We disaggregate the basic elements of a core in Figure 1(a) per their respective functions: instruction control and dispatch (ICU), memory (MEM), integer (INT) arithmetic, float point (FPU) arithmetic, and network (NET) interface, as shown by the slice labels at the top of Figure 1(b).
“In this organization, each functional slice is independently controlled by a sequence of instructions specific to its on-chip role. For instance, the MEM slices support Read but not Add or Multiply, which are only in arithmetic functional slices (the VXM and MXM slices).”

Ross said the company was now shipping its latest Groq card, Groq node and Groq ware SDK solutions to customers worldwide. “We’re shipping to our customers both as individual PCIe cards and systems with eight cards each, and there’s even more on the roadmap to come,” said Ross.
As noted earlier there were many more activities in the first day. Here’s a link to coverage of the panel on AI use in chip design appearing in HPCwire‘s sister pub, EnterpriseAI.
Link to AI Hardware Summit: https://www.aihardwaresummit.com/events/ai-hardware-summit-2020
























































