 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Given the COVID-19 pandemic, Nvidia’s announcement of plans to build a new AI supercomputer – Cambridge-1 – dedicated to biomedical research and healthcare was perhaps the most significant HPC news coming from fall GTC which began today. The new system, to be located in the U.K., will deliver more than 400 petaflops of AI performance, according to Nvidia, which is investing nearly $52 million in the project.

“Tackling the world’s most pressing challenges in healthcare requires massively powerful computing resources to harness the capabilities of AI,” said Jensen Huang, founder and CEO of Nvidia, in his GPU Technology Conference keynote. “The Cambridge-1 supercomputer will serve as a hub of innovation for the U.K., and further the groundbreaking work being done by the nation’s researchers in critical healthcare and drug discovery.”
The new system is named for University of Cambridge where Francis Crick and James Watson and their colleagues famously worked on solving the structure of DNA. Leveraging Nvidia’s SuperPOD architecture, it will have 80 DGX A100s, 20 terabytes/sec InfiniBand, 2 petabytes of NVMe memory, and require 500KW of power.
Nvidia states that Cambridge-1 will deliver “8 petaflops of Linpack performance” that would rank it as the top system in the U.K. at number 29 on the Top500 and number three on the Green500. While Nvidia’s technical collateral sets the A100’s peak double-precision (non-tensor) performance at 9.7 teraflops, its Linpack Rpeak is 56 percent higher: 15.1 double-precision teraflops. Since the DGX SuperPODs are standard, modular systems, Nvidia was able to pre-determine the Rmax (ie the Linpack score) for Cambridge-1 by extrapolating from Selene’s score* (the #7 Top500 system announced in June 2020).
The new system will serve academic and industry constituencies including, for example, GlaxoSmithKline (GSK), AstraZenica, King’s College, the U.K. National Health Service, among others.
Four focus areas were cited:
- Joint industry research – Solving large-scale healthcare and data-science problems which otherwise could not be tackled due to their size, resulting in improved patient outcomes, increased success rates and decreased overall healthcare costs.
- University-granted compute time – Access to Nvidia GPU time will be donated as a resource to specific studies to contribute to the hunt for cures.
- Support AI startups – Nvidia will provide opportunities to learn — and it will collaborate with startups to nurture the next generation and provide early access to AI tools.
- Educate future AI practitioners – The system will serve as a destination for world-class researchers and provide hands-on experiences to the next generation.
It should be noted the Cambridge-1 system is entirely separate from the Arm/Nvidia supercomputer announced last month. Cambridge-1 is expected to be installed by the end of the year and provide access to collaborators in the first half of 2021; given the speed with which Nvidia stood up its Top500 A100-based entry earlier this year, the aggressive timetable seems doable.

Indeed, Nvidia today announced the availability of Nvidia DGX SuperPOD solutions for enterprise, the world’s first turnkey AI infrastructure. “Available in cluster sizes from 20 to 140 individual Nvidia DGX A100 systems, DGX SuperPODs are now shipping and expected to be installed in Korea, the U.K., Sweden and India before the end of the year. Sold in 20-unit modules interconnected with Nvidia Mellanox HDR InfiniBand networking, DGX SuperPOD systems start at 100 petaflops of AI performance and can scale up to 700 petaflops to run the most complex AI workloads.”
The site for Cambridge-1 system has not yet been selected. Nvidia also emphasized plans for the Arm-based supercomputer announced last month are still evolving.
While announcement of the Cambridge-1 system was the biggest HPC splash at this fall’s GTC, there were several other significant technology introductions and upgrades spanning the datacenter, edge computing, all things AI, and more healthcare technology. This is an interesting moment for Nvidia and its vision of an AI-dominated computing landscape in which Nvidia offers a soup-to-nuts product portfolio (accelerators, high speed interconnect, CPUs (if the Arm acquisition goes through), systems, and development tools).
Lingering for a moment on healthcare, Nvidia also announced a partnership with GSK which is mounting one of the first AI-based drug discovery labs, the GSK AI Hub. “It’s really a model for the industry,” said, Nvidia’s Kimberly Powell, VP and GM, healthcare, in a press pre-briefing. “GSK is building the hub in London where they’re going to integrate state-of-the-art computing platforms based on DGX A100. They will be co-locating there [and] building up the number of data scientists, right now at 50, to 100 as soon as possible. Nvidia is going to also have our data scientists in their lab with them.”
The idea is to use AI methods and advanced computing platforms to unlock genetic and clinical data with increased precision and scale.
Nvidia has long been active in healthcare, particularly with its Clara tool suite for imaging and genomics analysis and collaboration. Today, it beefed up that offering by launching Clara Discovery – a collection of frameworks, applications and models enabling GPU-accelerated computational drug discovery.
“Specifically, Clara Discovery supports genomics workflows with Clara Parabricks, CryoEM pipelines with Relion, virtual screening with Autodock, Protein structure prediction with MELD, several 3rd party applications for molecular simulation, Clara Imaging pretrained models and training framework and Clara NLP with pre-trained models BioMegatron and BioBert and the NeMo training framework,” reports Nvidia. Researchers can presumably build discovery workflows with the tools, which are all in the NGC catalog.

Optimized for the DGX A100, Nvidia lists the following benchmarks (chart below) for several common tools.
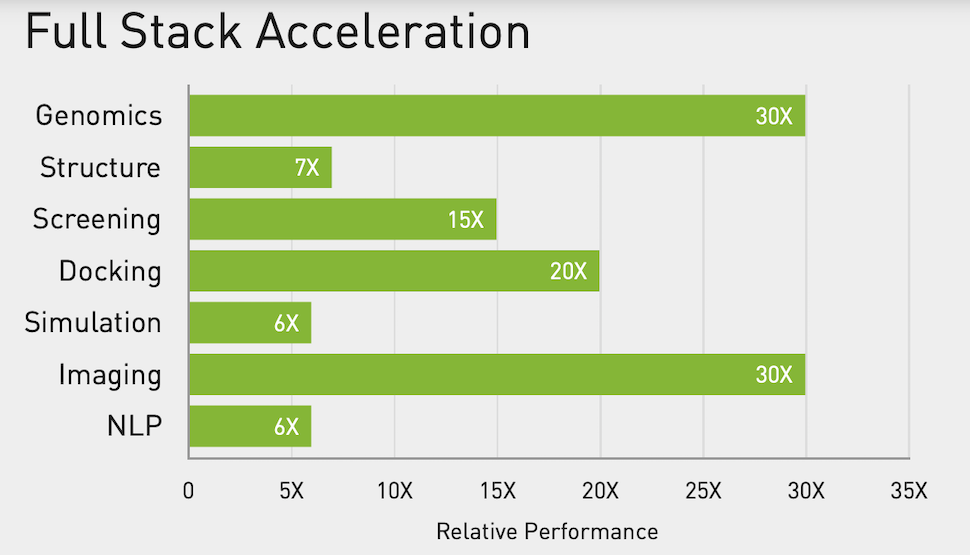
Nvidia also reported that Clara’s federated learning capability has helped Massachusetts General Brigham Hospital and others** develop an AI model that determines whether a person showing up in the emergency room with COVID-19 symptoms will need supplemental oxygen hours or even days after an initial exam. “The original model, named CORISK, was developed by scientist Dr. Quanzheng Li at Mass General Brigham. It combines medical imaging and health records to help clinicians more effectively manage hospitalizations at a time when many countries may start seeing a second wave of COVID-19 patients,” said Nvidia in a blog.
Dr. Hal Barron, chief scientific officer and president, R&D, GSK is quoted in the official announcement, “AI and machine learning are like a new microscope that will help scientists to see things that they couldn’t see otherwise. Nvidia’s investment in computing, combined with the power of deep learning, will enable solutions to some of the life sciences industry’s greatest challenges and help us continue to deliver transformational medicines and vaccines to patients.”
The big datacenter news from GTC was elaboration on Nvidia’s data processing unit (DPU) strategy and roadmap which include the new BlueField-2 DPU and BlueField-2X (with A100 on board). In many ways, the data processing unit captures ideas about intelligent networking put forth by Mellanox for a few years. Here the key is to offload various traffic and security tasks from the CPU and free its cycles for application use while also speeding and enhancing networking.


You can think of it as smart network interface card (SmartNIC) noted Manuvir Das, Nvidia head of enterprise computing, in a press pre-briefing. BlueField-2 combines 8 64-bit A72 Arm cores, 2 VLIW acceleration engines, and Mellanox ConnectX-6 Dx NIC.
Here’s what Huang said in his keynote. “DPUs are an essential element of modern and secure accelerated datacenters in which CPUs, GPUs and DPUs are able to combine into a single computing unit that’s fully programmable, AI-enabled and can deliver levels of security and compute power not previously possible.”
According to Nvidia, “a single BlueField-2 DPU can deliver the same datacenter services that could consume up to 125 CPU cores. This frees up valuable CPU cores to run a wide range of other enterprise applications.”
Product snapshot:
- The Nvidia BlueField-2 DPU, which features all of the capabilities of the Nvidia Mellanox ConnectX-6 Dx SmartNIC combined with powerful Arm cores. Fully programmable, it delivers data transfer rates of 200 gigabits per second and accelerates key datacenter security, networking and storage tasks, including isolation, root trust, key management, RDMA/RoCE, GPUDirect, elastic block storage, data compression and more.
- The Nvidia BlueField-2X DPU, which includes all the key features of a BlueField-2 DPU enhanced with an Nvidia Ampere GPU’s AI capabilities that can be applied to datacenter security, networking and storage tasks. Drawing from Nvidia’s third-generation Tensor Cores, it is able to use AI for real-time security analytics, including identifying abnormal traffic, which could indicate theft of confidential data, encrypted traffic analytics at line rate, host introspection to identify malicious activity, and dynamic security orchestration and automated response.

Das noted that VMware made a big announcement about VMware and Nvidia working together on project Monterey, by which VMware will be taking the ESXi hypervisor, and moving much of that functionality down into the BlueField-2 DPU.
“All of our OEM partners are lined up to produce servers with the BlueField-2,” said Das. “We are also now announcing the BlueField-2X, which is going to follow only a few months after the BlueField-2. As you can see, we are extending that card to include a GPU from our latest Ampere family of GPUs. So it is the GPU and the DPU working together to really extend the solution because now the tensor cores in the GPU will be used to be a variety of activities to make the network’s smarter.”
*Selene’s Top500 Linpack run delivered 27.58 petaflops of double-precision performance. At 275 nodes, that’s 100.29 teraflops per node. Nvidia estimated Cambridge-1’s Linpack score by multiplying the system’s 80 nodes by 100.29 teraflops-per-node, arriving at 8.02 petaflops Rmax.
**In addition to Mass Gen Brigham and its affiliated hospitals, other participants included: Children’s National Hospital in Washington, D.C.; NIHR Cambridge Biomedical Research Centre; The Self-Defense Forces Central Hospital in Tokyo; National Taiwan University MeDA Lab and MAHC and Taiwan National Health Insurance Administration; Kyungpook National University Hospital in South Korea; Faculty of Medicine, Chulalongkorn University in Thailand; Diagnosticos da America SA in Brazil; University of California, San Francisco; VA San Diego; University of Toronto; National Institutes of Health in Bethesda, Maryland; University of Wisconsin-Madison School of Medicine and Public Health; Memorial Sloan Kettering Cancer Center in New York; and Mount Sinai Health System in New York.
— Tiffany Trader contributed to this report.
























































