 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Competition to leverage new memory and storage hardware with new or improved software to create better storage/memory schemes has steadily gathered steam during the past couple of years. Intel’s Optane persistent memory solution, which uses 3D XPoint hardware and DAOS software stack, is among the handful of newcomers vying for sway, and it’s been a top performer on the IO500 list which benchmarks storage system performance.
Just before the holidays, Intel released new benchmarks for its Optane persistent memory (PM) solution. A blog by Andrey Kudryavtsev, Intel SSD solution architect, and a somewhat more detailed video by Kelsey Prantis, senior software engineering manager, both argued that the Optane/DAOS combination overcomes fundamental problems presented by POSIX and traditional parallel file systems such as Lustre.
The benchmarks (more detail below) are on Intel’s second-gen Optane PM 200 with newer chips. On one common test (IOR) the PM 200 delivered a 58 percent gain versus the earlier PM 100 series. Intel released the new benchmarks roughly coincident with its Memory & Storage Moment 2020 event in mid-December where it also introduced some new products and confirmed development of the third generation of Optane PM, code-named Crow Pass. Few details on Crow Pass were provided, although Prantis mentioned it would have two more DIMMs per socket, which should further boost performance. (See HPCwire coverage of the new products introduced.)
A sore point around Optane has been its proprietary nature and Intel’s insistence that DAOS must be used with Optane PM.
Kudryavtsev wrote in his blog: “’Why is PMem required for DAOS and can’t be substituted?’ is a question I hear quite often. There are multiple reasons. Kelsey Prantis brought several of them for your consideration in her v-blog. PMem is used for the shared store of Metadata information and Small I/O tier. Metadata access is of very low granularity and is just moving away from block storage to a cache line that simplifies its operations and needs to keep an active DRAM buffer. Small I/O on the other end gets stored into PMem on writes, which is defined by the DAOS policy engine. This allows us to optimize bulk data writes to NVMe SSDs for better SSD performance (higher block size delivers better bandwidth) and SSD endurance which is also dependent on the write pattern.”
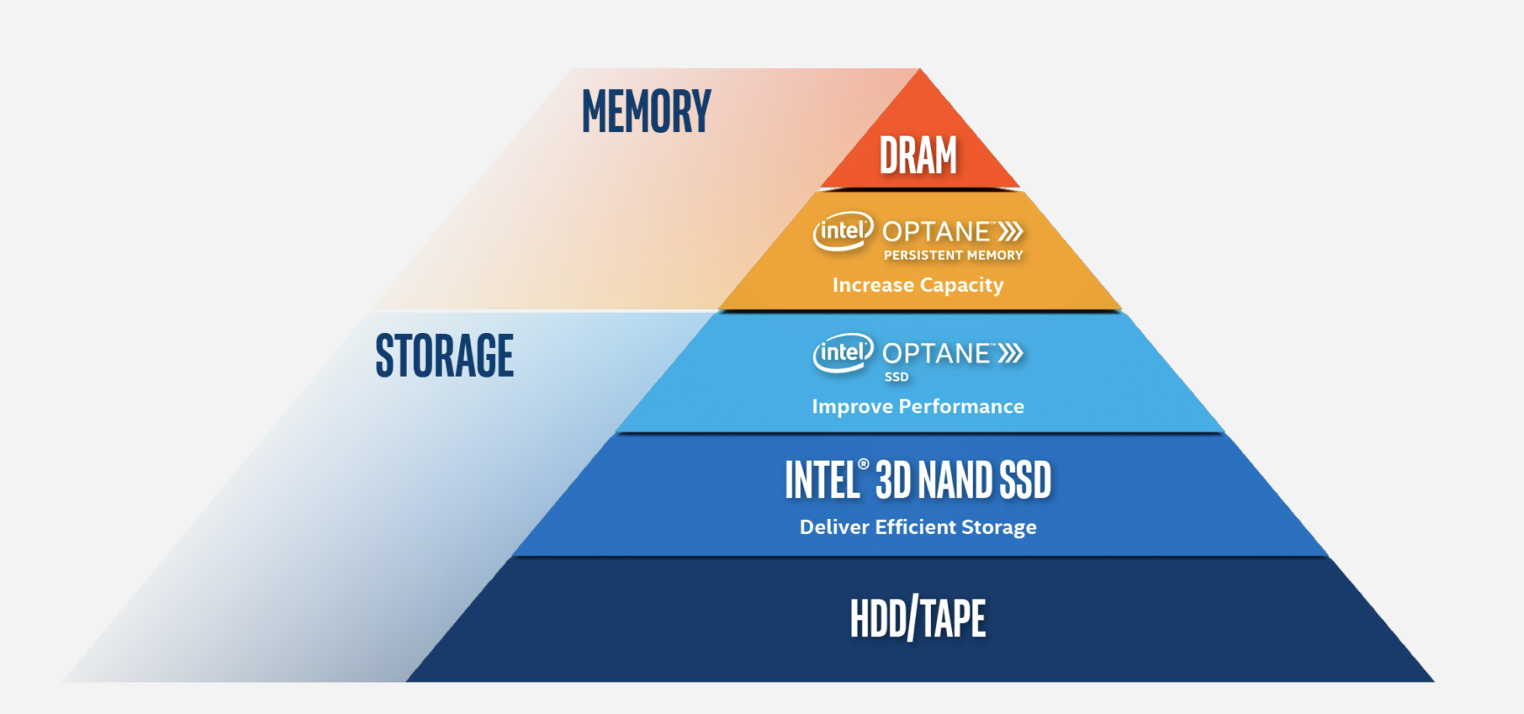 It seems like the idea is simply that DAOS is designed specifically for the Optane hardware. OK. Without a doubt, Optane has been an impressive performer. It is positioned as sitting below the DRAM main memory and above SSDs. As the name suggests, it memory is persistent, unlike DRAM (link for more on Optane technology).
It seems like the idea is simply that DAOS is designed specifically for the Optane hardware. OK. Without a doubt, Optane has been an impressive performer. It is positioned as sitting below the DRAM main memory and above SSDs. As the name suggests, it memory is persistent, unlike DRAM (link for more on Optane technology).
In many ways DAOS is the magic sauce and Prantis’s video (~9 minutes) is a good representation of the Optane-plus-DAOS argument. Media latency and file system latency are the key speedbumps in storage with small-file handling (think metadata) and POSIX’s safety features (lockdowns) playing major roles.
Storing data takes a few steps, Prantis noted in her video: “It has to go through a process. You start with your rich structured data, that data gets serialized to a series of blocks. Then those blocks get written to the underlying media. But when it comes to writing any sort of small IO, whether that is filesystem metadata, or that the IO itself is small, that can create a significant performance problem.
“[If] you look at block five in the traditional POSIX data storage column here (see slide below), you can see that there’s actually multiple pieces of data being stored in the same block of media. And what happens when you have multiple compute nodes as you have shared storage that are trying to access the piece of data on that same block, the software has to lock access to that block and serialize those two activities and accesses from the clients. You do that several million times across your cluster, it actually is creating a very real performance bottleneck that is limiting IO applications today,” she said.

Memory that is both persistent and byte addressable, such as in Optane, permits eliminating block-based IO.
“We take the low latency and byte addressable data access that we [now] have and built a new software stack on top of that won’t have to be constrained by block-based IO and is also able to be written to completely in user space; none of the IO or DAOS goes through the kernel. DAOS itself presents a selection of interface options to the end user such as the traditional POSIX interface of key value interfaces and even other middleware and application frameworks are able to communicate directly with DAOS as a back end,” said Prantis.
“Then DAOS will take all of those small IOs and any metadata IOs, and it stores that in the Intel Optane persistent memory, where the different clients then can byte-addressively access those pieces of data. Those actions can now happen in parallel instead of in serial, and all of your larger block-friendly IOs will still go to NVMe SSDs. And DAOS goes ahead and makes that completely transparent to the end user. This sort of architecture is really only possible because of the new hardware capabilities.”
DAOS is young and not yet widely adopted, but it has shown promise. Intel entries to the IO500 have consistently scored high, including a record-setting win in the ISC20 running of the benchmark. Intel was second on the SC20 IO500 list, ahead of WekaIO which finished third. The top performer at SC20 IO500 was an entry from Pengcheng Laboratory using MadFS distributed network file system.

Prantis also reviewed the PM 200 v PM 100 benchmarks for metadata handling and IO. The data was from pre-production testing and based largely on the hardware upgrades (chips) and without software tuning.
“For those who aren’t familiar, MD test is a common industry benchmark for measuring the metadata performance for parallel distributed file systems. As mentioned earlier, metadata and those small file IOs are where block-based interfaces really introduced the most problems. So it’s really here where we see that the persistent memory helps us shine. You can see here, right, there’s quite a bit of performance improvement. I will say there are two more DIMMs per socket with the next generation of Intel persistent memory. So we do expect to see some improvement from the additional DIMMS dims. But we also believe there is improvement due to a number of other improvements in the media as well, including things such as flash as well as some improvements to the PM software stack,” she said.
“IOR is another industry benchmark, this time focused on measuring the bandwidth for complete IOs, not just the metadata. Here we are seeing an outstanding 58% improvement in the bandwidth. Again, this is with no changes to the software, just plug and play on the new set of hardware. And at this point, we’re really reaching network saturation and expect that we should be able to see actually even more read bandwidth once we’re able to move to a 200-gig network versus the 100-gig network we used for this.”


Link to blog: https://software.intel.com/content/www/us/en/develop/articles/building-storage-right-with-daos-and-intel-optane-pmem-200.html
Link to video: https://www.youtube.com/watch?v=Luyjxb8egDc&ab_channel=DAOS


























































