 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Frontera, the world’s largest academic supercomputer housed at the Texas Advanced Computing Center (TACC), is big both in terms of number of computational nodes and the capabilities of the large memory “fat” compute nodes. A couple of recent use cases demonstrate how academic researchers are using the quad-socket, 112-core, 2.1 TB persistent memory to support Frontera’s large memory nodes to advance a wide variety of research topics including visualization and filesystems.
Visualization
The advent of Software Defined Visualization (SDVis) is a seismic event in the visualization community because it permits interactive, high-resolution, photorealistic visualization of large data without having to move the data off the compute nodes. In transit and in situ visualization are two techniques that allow SDVis libraries such as Embree and OSPRay to render data on the same nodes that generate the data. In situ visualization renders data for visualization on the same computational nodes that perform the simulation. In transit visualization lets users tailor the render vs simulation workload by using a subset of the computation nodes for rendering.
“The HPC community is entering a new era in photorealistic, interactive visualization using SDVis,” said Dr. Paul Navrátil, director of visualization at TACC. “For many users, the Optane-enhanced nodes on Frontera provide their first opportunity to experience the performance and visualization benefits of SDVis to analyze data requiring a very large shared memory resource.”
The quad socket Intel Xeon Platinum 8280M large memory Frontera nodes give scientists the ability to interactively render and see important events (due to CPU-based rendering) and – again interactively – jump back in the data to examine what caused the important event to happen. This interactive “instant replay” capability is enabled by the high core count, high-bandwidth (six memory channels per socket or 24 memory channels total) of the TACC large memory 2.1 TB nodes.
Jim Jeffers (senior principal engineer and senior director of advanced rendering and visualization at Intel) has been a central mover and shaker in HPC visualization with his work on SDVis and the Intel Embree and Intel OSPRay libraries. He explains, “Optane Persistent Memory provides scientists with the memory capacity, bandwidth, and persistence features to enable a new level of control and capability to interactively visualize large data sets in real time and with up to film-quality fidelity. Scientists are able to recognize or more easily identify key occurrences and interactively step forward and backward in time to see and understand the scientific importance. Because of the cost of moving large data from memory to storage or over the internet can be hours, days, and beyond; this is a capability that will be critical to fully take advantage of Exascale and beyond computing.”
Use Case: Visualizing OpenFOAM Fluid Flows
David DeMarle (Intel computer graphics software engineer) points out that the 2.1 TB memory capacity in the Frontera large memory nodes gives users the ability to keep extensive histories of their OpenFOAM simulations in memory. Using software, scientists can trigger on an event, receive an alert that the event has happened, and then review the causes of the event. Collisions, defined as an event where multiple particles are contained in a voxel or 3D block in space, are one example of an important fluid flow event. Alternatives include triggers that occur when the pressure exceeds or drops below a threshold in a voxel.
Memory capacity is important to preserving the simulation histories that help scientists understand physical phenomena as modern systems can simulate larger, more complex systems with higher fidelity. Keeping data in the persistent memory devices delivers a performance boost. DeMarle observes, “The runtime savings is highly correlated to amount of memory, which implies that the savings will scale to large runs both in terms of size and resolution.” Scalable approaches are important as we move into the exascale computing era.
DeMarle and his collaborators used in situ methods to create their OpenFOAM visualizations and histories so the data does not have to move off the computational nodes. They called the Catalyst library to perform the in situ rendering. Alternatively, users can also perform in situ visualization using the OpenFOAM Catalyst adapter. ParaView was used as the visualization tool.
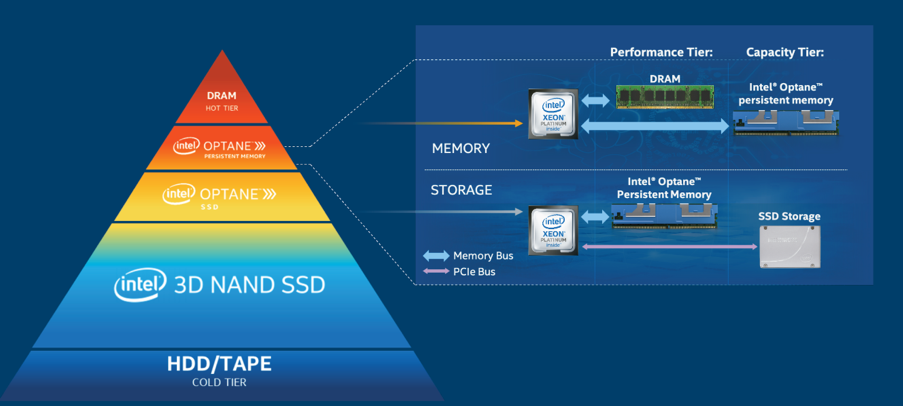
To control resource utilization, Catalyst calls the open-source Intel memkind library. This provides two advantages: (1) the persistent memory capacity could be allocated for use by the simulation (using Memory Mode) and (2) data could be directly written to the persistent memory devices using App Direct mode.
In Memory Mode, the DRAM acts as a cache for the most frequently-accessed data, while Intel Optane persistent memory provides the large memory capacity. No program modifications are required for an application to use Memory Mode.
With App Direct mode, the software directly reads and writes the persistent memory media via the DAX (data analysis expressions library) instructions that are available on select Intel Xeon Scalable processors. [i] These instructions let the CPU directly access the persistent memory media via transactional operations that keep user data safe, thus bypassing the traditional operating systems bottlenecks such as the page cache and block layer. [ii]
DeMarle notes that multi-threaded applications are required to realize the performance benefits due to the high memory bandwidth of the Intel Optane memory. “Single threaded performance gains are negligible while the performance differences are clear when running multithreaded.”
Overall, DeMarle believes the TACC large memory nodes are a good transition for people to get used to having a terabyte of memory on a workstation. In particular, in-situ visualization is a good use of the increased memory capacity due to the Intel Optane persistent memory tier.
180-degree High Resolution Climate Simulations
Scientists are also visualizing photorealistic, high-resolution climate data on the TACC Frontera large memory nodes. The German Climate Computing Centre (Deutsches Klimarechenzentrum, DKRZ) in collaboration with Intel is investigating the capability of the persistent memory capacity of the TACC nodes. In this investigation, the Intel Optane persistent memory devices are operating in Memory Mode, so no code modifications or adapters were required.
Carson Brownlee (graphics software engineer, researcher and part of the OneAPI Render Kit team at Intel) is part of the team that integrated a path tracer in the popular ParaView visualization tool. The path tracer allows photorealistic visualizations of the DKRZ high resolution data.
Brownlee notes, “The TACC visualization work was an extension of the simulations and visualizations conducted at DKRZ (the Eurovision/supercomputing submissions were done at DKRZ). We were able to view many timesteps of this data during our demos due to the large memory space.” The amazing fidelity of the DKRZ simulations can be seen in the Eurovision video at https://www.youtube.com/watch?v=gQl_RQLw2Mw. This research project was a finalist in the scientific visualization track at Supercomputing 2020.
Of course, everything in the visualization relies on the simulated climate data. The DKRZ climate simulations are remarkable in that they can model local climate systems to 150m of detail. Further, DKRZ is experimenting with 1 kilometer global data modeled for the years 1850 to 2300. Statistics such as mean temperature, precipitation can be used to validate the simulation against data recorded during this time period and to date. The effects of CO2 can also be evaluated by comparison between simulated and historical data.
Providing a high-level summary, Niklas Röber (DKRZ visualization staff) said, “Visualization is analysis of the data in visual form. You can make annotations, debug, and even steer the model using this technology.” He continues, “Without OSPRay and pathtracing this video would not have been possible. It is really exciting to see the visualization on a 180-degree display.”
The simulated data can be rendered on a 180-degree display. Röber notes, “We hope to make this available for viewing in places such as planetariums.” The following image conveys the impact of photorealistic climate model visualization in print format. The difference compared to ray casting is stunning. You can also view the SC20 presentation and video at https://nextcloud.dkrz.de/s/cBTBso8w5T8bpSq.

Size is a significant challenge with such high-resolution data. According to Brownlee, the demo data consumes 1.3 TB. The 2.1 TB persistent memory capacity on the Frontera large memory nodes allows loading of 150 time steps. These numbers can help the reader get a sense of why terabyte storage capacity is so important in preserving interactive response time.
Use Case: Order of Magnitude Faster Filesystem Research
In another use case, Simon Peter (Professor of Computer Science at U.T. Austin) is leading the effort on the Assise, an open source, client-local distributed filesystem. [i] Assise is a French name that describes a geographic stratum of rock.
Recent innovations in nonvolatile storage media – like Optane persistent memory devices that operate off the system memory bus – have made filesystem research a hot research topic. The performance characteristics are notable. For example, the persistent memory devices have already been shown to deliver latency measured in nanoseconds and bandwidth measured in tens of gigabytes per second per node.[ii]
Peter’s research effort at TACC looks to incorporate the benefits of NVM technologies in a distributed environment by creating a topology-aware filesystem. “It’s all about locality,” he observes.
Assise breaks that model and instead uses a NUMA like model where the thread that creates the data owns it as well as the lock that allows coherent operations on the data in a parallel/distributed environment. The software does not use the Linux VFS layer. Rather it intercepts filesystem calls from the application. Direct access to storage from user space bypasses all the overhead of the OS system call, page cache, VFS (Virtual File System) layer, block cache, PCIe driver and PCIe bus.
These are some of the key reasons why the Assise github page states, “Assise accelerates POSIX file IO by orders of magnitude by leveraging client-local NVM without kernel involvement, block amplification, or unnecessary coherence overheads.” Please see the OSDI paper for more detail.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. Rob can be reached at [email protected].
[i] https://www.intel.com/content/dam/support/us/en/documents/memory-and-storage/data-center-persistent-mem/Intel-Optane-DC-Persistent-Memory-Quick-Start-Guide.pdf
[ii] https://software.intel.com/content/www/us/en/develop/articles/introduction-to-programming-with-persistent-memory-from-intel.html
[iii] https://wreda.github.io/papers/assise-osdi20.pdf
[iv] https://lenovopress.com/lp1083.pdf


























































