 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street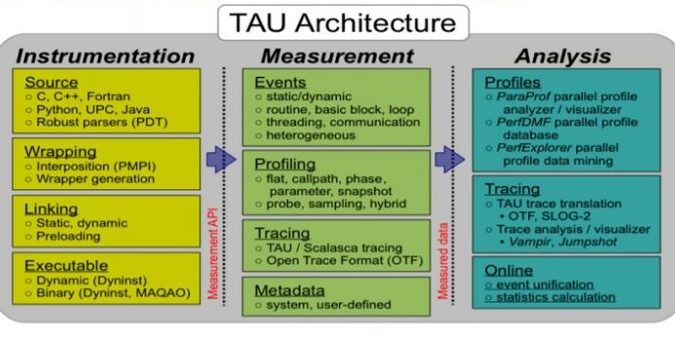
Programmers cannot blindly guess which sections of their code might bottleneck performance. This problem is worsened when codes run across the variety of hardware platforms supported by the Exascale Computing Project (ECP). A section of code that runs well on one system might be a bottleneck on another system. Differing hardware execution models further compound the performance challenges that face application developers; these models can include the somewhat restricted SIMD (Single Instruction Multiple Data) and SIMT (Single Instruction Multiple Thread) computing for GPU models and the more complex and general MIMD (Multiple Instruction Multiple Data) for CPUs. New software programming models, such as Kokkos, also introduce multiple layers of abstraction and lambda functions that can hide or obscure the low-level execution details due to their complexity and anonymous nature. Differing memory systems inside a node and differences in the communications fabric that connect high-performance computing (HPC) nodes in a distributed supercomputer environment add even greater challenges in identifying performance bottlenecks during application performance analysis.
One Profiler for All HPC Systems
These issues are all addressed by the Tuning and Analysis Utilities (TAU) Performance System, which gives HPC programmers the ability to measure performance and see bottlenecks via one profiling tool that works well across a broad spectrum of widely differing HPC systems, architectures, languages, and software/hardware execution models. Thus, programmers do not need to guess about performance issues, nor do they need to learn a new hardware-specific profiler for each system.
Even better, TAU is lightweight. Users can use TAU to profile binary applications if the binary is compiled with the symbol table. The only exception is if a code invokes a lambda function that must be compiled for the destination hardware. In this case, extra instrumentation is required.
Sameer Shende, the director of the Performance Research Lab of the University of Oregon’s Neuroinformatics Center, observes that, “the TAU profiler supports all CPUs and GPUs, as well as multinode profiling with message passing interface (MPI) and high-level performance portable libraries, such as Kokkos. It’s one of the few tools that supports all vendor GPUs. The TAU profiler easily installs via Spack and is distributed in the Extreme-Scale Scientific Software Stack (E4S). Just install TAU with the target back-end CUDA, ROCm, L0 for OneAPI, etcetera.”
LLVM-Based Profiling Support
Considered a “Swiss army knife” of profiling, TAU relies on the open-source LLVM compiler infrastructure trace and instrumentation capabilities to collect profile information. Significant amounts of profile information can be collected from LLVM. This provides TAU with visibility into a huge range of architectures and compilers. Johannes Doerfert, a researcher at Argonne National Laboratory, notes that, “people don’t realize that all HPC vendor compilers are LLVM-based.” This broad level of support across so many diverse languages and hardware platforms explains the comment by Allen Malony, professor at the University of Oregon, who said, “TAU is a scalable, portable measurement system that supports every parallel runtime system and heterogeneous computing environment.”
Runtime and Multi-Level Profiling Support
TAU also provides support for the instrumentation of Kokkos codes and a broad range of runtimes at the node level, including OpenMP, pthread, OpenACC, CUDA, OpenCL, and HIP. It supports detailed MPI-level data by using the PMPI and MPI Tools interface.[1]
A brief summary of TAU’s capabilities is illustrated in Figure 1.

Support for Lambda Functions
New software frameworks, such as Kokkos, have introduced performance portability and convenience features, such as lambda functions, to the HPC community. By using such languages and libraries, it is possible to write one version of a code that will run and produce correct results on many platforms. New abstractions, such as Intel’s OneAPI, are also in development to provide cross-platform applications that will run correctly on a variety of hardware platforms via a single code base.
The TAU team recognized that although cross-platform codes might run correctly, they might not perform equally well or adequately on all platforms. For this reason, they focused on a multilevel instrumentation strategy that encompasses the application code and language runtime to provide informative profiling information.[2]
Lambda functions excellently illustrate the need for informative profiling information. Many profilers use event-based profiling to evaluate complex nested template functions, such as the one shown in Figure 2.

Functions of this complexity are the result of the Kokkos infrastructure mapping the logical space to the physical memory layout at compile time via template programming.
To obtain insightful and actionable performance results, a performance tool must receive metadata from the runtime, providing data mapping runtime behavior back to the application code that produced it. TAU uses these callbacks to start and stop timers, allowing human-readable timer names to be used in place of the names of C++ template instantiations. Thus, users would see the profiler label as shown in Figure 3 rather than as the nested template instantiation shown in Figure 2.

Focus Optimization Efforts Based on Data
The TAU team gathers the raw profile information from many levels[3] to create several meaningful displays, reports, and trace analyzers that help users find performance issues in their parallel distributed codes. Shende notes, “With TAU, you can see the code regions of interest so you can study your application performance and identify where you should focus your optimization efforts.”
Example views generated by the ParaProf analysis tool are shown in Figure 4. In particular, ParaProf can display profile information about MPI communication calls in addition to node- and thread-level displays. A standard in HPC, the MPI library handles the communications that dictate the scaling and performance of many HPC applications.

Figure 4. TAU analysis with example ParaProf views.
Extensive and Easy to Install
It is easy to find documents, success stories, video guides and tutorials that cover the extensive capabilities of the TAU Performance System.[4],[5],[6] It is also easy to install; Shende points out that, “TAU easily installs via Spack and is distributed in E4S. Just install TAU with the target backend CUDA, ROCm, L0 for OneAPI.”
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations. Rob can be reached at [email protected]
[1] https://www.cs.uoregon.edu/research/tau/TAU_Kokkos_SC19.pdf
[2] https://www.researchgate.net/publication/337720583_Multi-Level_Performance_Instrumentation_for_Kokkos_Applications_Using_TAU
[3] Ibid
[4] https://www.cs.uoregon.edu/research/tau/home.php
[5] https://www.cs.uoregon.edu/research/tau/docs.php
[6] https://www.cs.uoregon.edu/research/tau/pubs.php
Republished with permission of Exascale Computing Project.

























































