 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
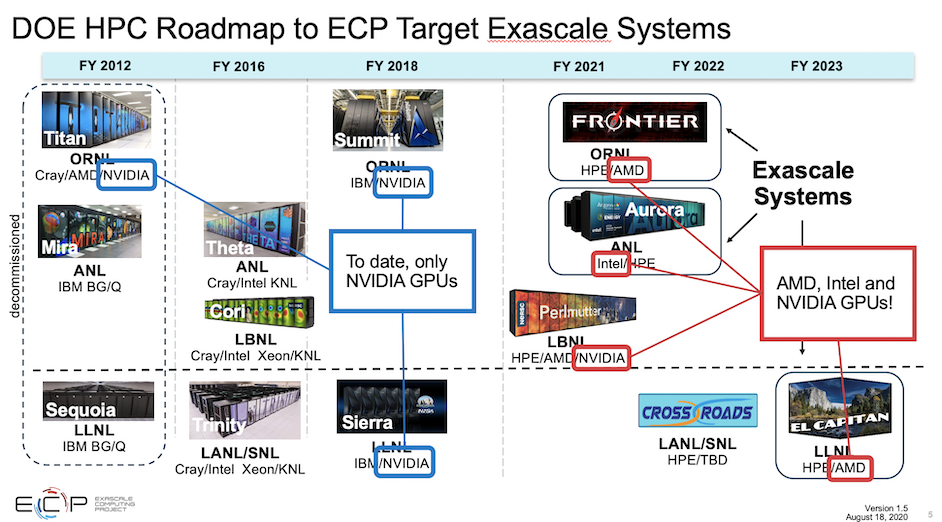
For the better part of a decade the U.S. Exascale Computing Initiative (ECI) has been churning along vigorously. The first exascale supercomputer – Frontier – is expected this year, with Aurora and El Capitan to follow. How much of the exascale-derived technology will diffuse through the broader HPC landscape and how soon? Andrew Siegel, director of application development for the Exascale Computing Project (ECP), the software arm of ECI, took a stab at that question as well as summarizing overall ECP progress in his keynote at last week’s annual Rice Oil and Gas HPC Conference.

“I’ll update you how things have gone generally in the (ECP) project, what’s been harder than expected, what’s gone surprisingly well, what remains to be done, some implications for the future. [But] before we begin, let me start by posing some fundamental questions that might be on your minds during the talk. It’s very important for me to remember that not everybody is operating at the bleeding edge of high performance computing, and that most of what happens is at the sort of mid-range,” said Siegel.
“One question is, to what degree will this initial U.S. exascale technology impact what people see at mid-range high performance computing? And is this inevitable? Or might we not see such an impact? What are viable alternatives for people making procurements in the next several years? I’ve talked to lots of different groups who wonder, is it time to buy, for example, a GPU-based system now? Should I wait? What are the implications of waiting? How do I make this decision? What about alternatives to the technologies that have been chosen by the U.S. for its first push to exascale? For example, the ARM64 system in Fugaku? How long will these architectures be relevant? So what is next after what we see in this first wave of exascale?”
Good questions.
Siegel’s answers, perhaps predictably, were more guarded. It’s early days for much of the technology, and picking broadly useable winners isn’t easy, but Siegel’s fast-moving reprise of the ECP experience and lessons learned are nevertheless valuable. Near the top of the list, for example, was the role of domain experts in adapting applications for the forthcoming exascale systems, all of which are GPU-accelerated.

“In almost all cases the AD (application development) teams are led by domain scientists. The domain scientist obviously understands the modeling problem, how it relates to validation and verification, and the numerics. They don’t understand anything close to all of the complexity of the hardware, and the sort of hardware algorithm interfaces necessary to pull this off. So the teams themselves are hybrid have people with expertise in applied math and computer science and in sort of software engineering on them. [The] most successful have either put all of this together and a very diverse team,” Siegel said.
To give you a sense of the challenge:
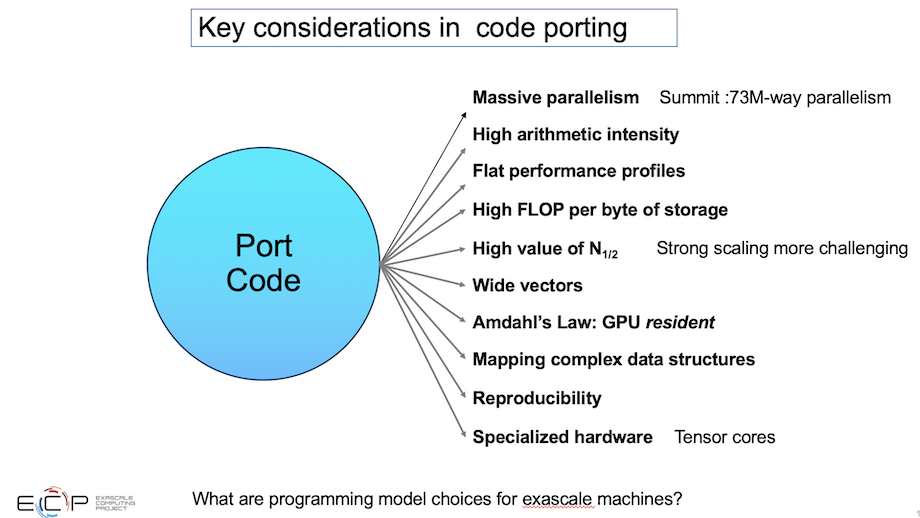
“There are lessons that I’ve learned in overseeing these projects for five or six years now. The first is that one has to be able to extract massive parallelism from the algorithm. That goes without saying, but sometimes we lose a sense of how massive massive is. [If] we just think about Summit (pre-exascale system) to literally map everything to all available parallelism will be 73 million degrees of parallelism and that does not account for the need to over-subscribe to a GPU-type architecture so that it can schedule efficiently. So you can imagine how going into future systems, billion-way parallelism is the starting point for being able to get efficient use out of those systems,” said Siegel.
ECP, of course, has been the main vehicle charged with ensuring there is a software ecosystem able to take advantage of the coming exascale systems. This includes three interrelated areas of focus: hardware and integration; software technology; and application development. Much of the early work was done on pre-exascale Summit and Sierra systems which share the same architecture and rely on Nvidia GPUs. That relative simplicity will change as the exascale portfolio will include systems that also use AMD and Intel GPUs.

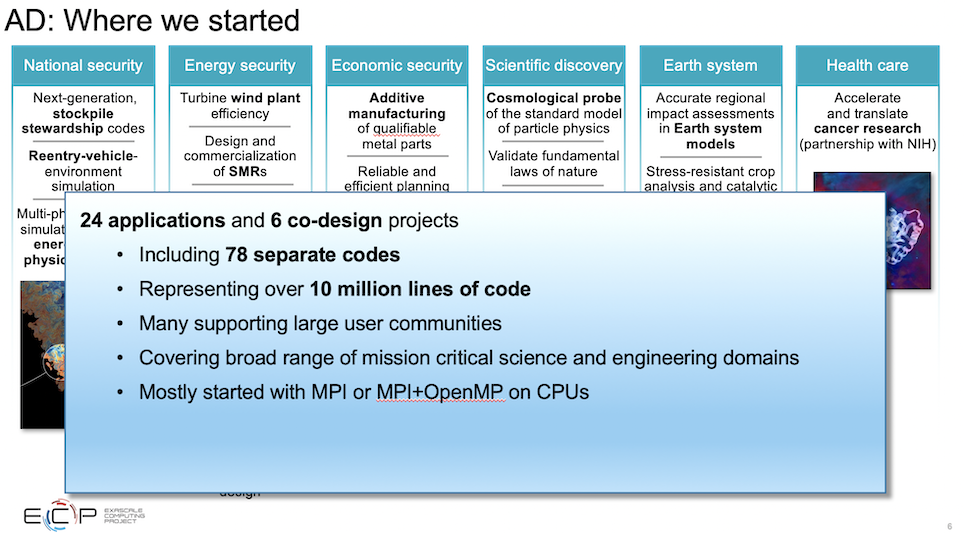
Siegel’s AD group has been focused on preparing applications for the systems. ECP settled on six application areas (national security, energy security, economic security, earth systems, and health care) and 24 applications with a significant focus on simulation and data-driven (AI) approaches.
“We were looking for a certain number of guinea pigs who were willing to sort of work on the cutting edge and take a risk. And help both understand how to use these systems do science on these systems as well as contribute to the maturation of the systems at the same time. So there was a difficult RFP process you can imagine. But in the end 24 applications were chosen to be part of this push, and we see them as kind of leading the way into the exascale era,” said Siegel.
“Over 10 billion lines of code were represented. One thing that is very critical is that many of these codes supported, at least in our field, what we consider to be large user communities. So it might be up to 10,000 people or so for thinking about computational chemistry, but [that] can easily be in the hundreds [of thousands]. For other applications, molecular dynamics could be a lot, astrophysics could still be 100 research teams, computational fluid dynamics could be more,” he said.
Clearly that’s a daunting task which is now nearing completion. Siegel discussed both specific applications as well as more general software issues.
“All of the 24 applications I mentioned have gone through the following transition. So they’ve gone from the sort of CPU or multi-threaded CPU, to the CPU plus single GPU, to CPU working with multiple GPUs and that brings in new challenges to diverse multi-GPU architectures. That includes early hardware that we have access to from Intel and AMD and the new Nvidia hardware features that are targeting AI workflows. All projects have ported to the Summit and Sierra architecture and they have performance increases, which is quantified by fairly complex figures of merit (FOM) that are unique to each of these applications between a factor of 20 and a factor of 300. Our successes on the Summit platform have been a major story of the project. And that’s a different talk,” said Siegel.

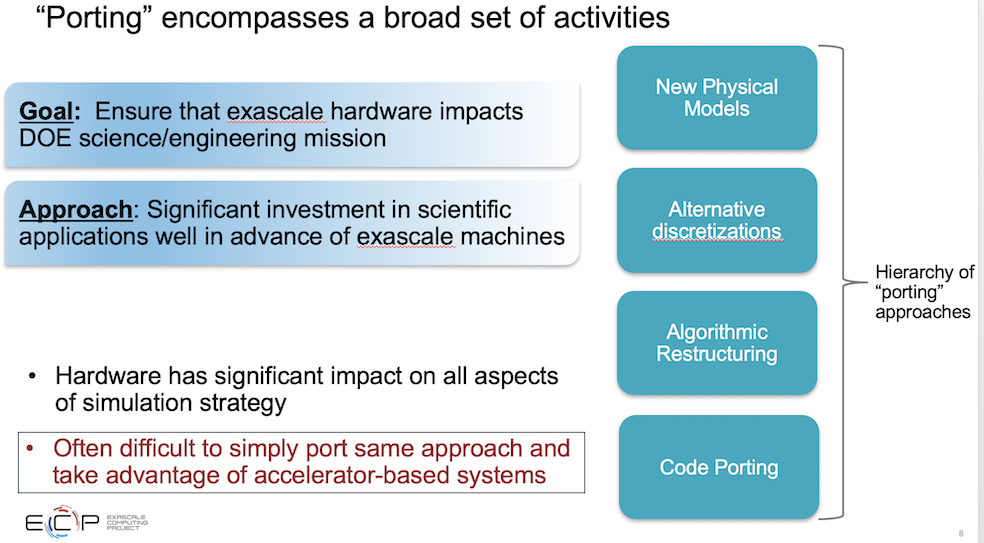
“One thing that we learned that was a surprise to me and that I can’t emphasize enough is that there’s really a hierarchy of porting approaches that touches all aspects of simulation. We think of code porting as the reordering loops or changing data structures or memory coalescing, whatever the case might be. But we also have things that are more fundamental algorithmic restructuring; that could include things like communication avoiding algorithms, reduced synchronization, or use of specialized hardware. And we think of alternate discretizations, like approaching a problem using higher order methods because they are more amenable to the hardware,” said Siegel.
“Now we think of entirely new physical models [because] we have all this new computing power. So an interesting consequence of this big shift in computing hardware is [it has] had a significant impact on all aspects of simulation strategy. It’s been, in most cases, difficult to simply port the same approach, and take full advantage of the accelerator based systems.”

Not surprisingly, porting apps to the new hardware was challenging and sometimes posed critical choices for dealing with the strengths and drawbacks associated with weak scaling and strong scaling.
“There were a lot of clever strategies for mitigating the negative impacts of strong scaling with accelerated based systems. There were a lot of issues with the maturity of the software ecosystem that HPC depends on on the Early Access machines. So things like dense matrix operations, things that need to perform well. When you think about running on one of these machines, you have to think about the maturity of everything around the hardware, not the hardware itself. The performance of OpenMP offload, and strategies for GPU residence, and the role of unified virtual memory and achieving that.
“A really interesting question that’s begun to emerge as we’ve gotten more GPUs on the node and the nodes have become more and more complex is increased costs, relatively, of internode communication. So MPI implementations now, which weren’t really an issue at 10,000 nodes, now have to keep up with the incredible performance on a single node. People are starting to say that’s what our real bottleneck is. That was not the case until this point in the project,” said Siegel.
Despite moving quickly, Siegel dug into many of the challenges encountered. In this sense, his talk is best watched/listed to directly and there are plans to post it. Of note, incidentally, are plans to slightly modify the conference name. Next year will be the 15th year and it will become Rice Energy High Performance Computing Conference.
Circling back to his opening comments, Siegel closed with broad thoughts on how quickly technology developed for the exascale program will filter throughout the broader HPC world. On balance, he said, it’s fine to wait and smart to prepare.
“If I go back to the original questions (slide repeated below) I started with, I do not have answers to these questions. So much depends on your own circumstance. But if I say to what degree is this technology going to impact midrange computing? I’d say a significant impact is highly likely and there’s an impact already. Are the viable alternatives? Absolutely. [There] doesn’t have to be huge rush. x86 or Arm-based systems, with or without the special vector extensions, are certainly viable alternatives.
“I would say learn about and reason about how one’s code would map to these types of systems before you dive in headfirst. I’m speaking to people who are sort of on the sidelines. One of the important questions is, even if you can port more easily, what’s the cost of porting performance relative to a multi-GPU system? I think understanding and evaluating codes is important, even though it’s perfectly reasonable to take a wait-and-see attitude if you’re doing a procurement. The software cost porting can be very low if you have localized operations, high intensity, most of your performance is a very small part of your code. But it could be quite high when you’re doing things that are not computationally-intensive when you have performance spread out all around your code [and] when you have very complex data structures,” he said.
“One has to also remember that the things that I list below are all evolving and they’re still relatively immature and they’ll be much better soon. So we’ll begin to coalesce around programming models; we will see a thinning of the number of options and a hardening of the best ones.”
Link to 2021 Rice Oil and Gas High Performance Conference: https://rice2021oghpc.rice.edu/programs/
Slides are from Siegel’s keynote

























































