 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Intel’s GPUs will come. There may be discussions about the role Intel’s GPUs will play in the Aurora supercomputer, the second exascale system of the U.S. Exascale Computing Project, but Intel certainly has committed to developing discrete GPUs for high-performance computing. And while any predictions about the performance characteristics and technical realizations are rather speculative, the plans for the software ecosystem are rather mature.
Intel has teamed up with Codeplay, HPE, and other institutions from industry and academia to form a “cross-industry, open, standards-based unified programming model that delivers a common developer experience across accelerator architectures”: oneAPI. This SYCL-based programming model is expected to become the primary vehicle for applications to leverage the computing power of Intel GPUs. With the importance of Intel architectures for the U.S. Exascale Computing Project in mind, we report in a preprint the developer effort necessary to prepare a high-performance math library for Intel GPU architectures and the maturity of the oneAPI ecosystem. The ecosystem contains not only the DPC++ compiler ready to compile code for multicore processors and GPUs, but Intel also developed a number of libraries for mathematical functionality, video processing, analytics and machine learning, deep neural networks, and others (see Figure 1). The goal is to provide high-productivity toolboxes to the application specialists to ease development and performance tuning.

Our report describes that the DPC++ Compatibility Tool (DPCT) provided by Intel is a useful tool to convert CUDA code to DPC++, but primarily designed for moderate-sized libraries with few dependencies that aim at a complete transition to the oneAPI ecosystem. For applications that rely on distinct hardware-specific backends for platform portability, like the Ginkgo library we develop as an ECP product that is part of the E4S software stack, the use of the DPC++ Portability Tool needs both preprocessing and postprocessing of the files to generate a working backend without disabling the support for other architectures.
“[H]aving a working backend is only the entry-level: for high-performance applications, significant optimization efforts are necessary to push the performance to the hardware-specific limits.”
Using customized workarounds, the DPCT can significantly reduce the porting effort. We were able to develop a working DPC++ backend for Ginkgo within two weeks. However, having a working backend is only the entry-level: for high-performance applications, significant optimization efforts are necessary to push the performance to the hardware-specific limits. And it is this phase that reveals that the oneAPI ecosystem is still under development. Some basic functionality like cooperative groups are still missing, and also Intel’s open-source oneMKL math library up to now only incrementally expands to cover the kernel zoo of the exemplary CPU-focused Intel Math kernel Library (MKL). We need some hand-crafted solutions to enable the full functionality. And then? Will the converted CUDA kernels deliver good performance on Intel GPUs? For obvious reasons, it is meaningless to compare the performance the original CUDA kernel achieves on the Nvidia V100 GPU deployed in the Summit supercomputer with a prototype of the Intel GPU planned for the Aurora system. Instead, we do not look at absolute performance, but at performance relative to the architecture-specific limitations. In figure 2, we visualize the performance Ginkgo’s Sparse Matrix Vector (SpMV) kernels achieve relative to the hardware specifications on the Nvidia V100 GPU (left) and Intel’s Gen12LP GPU (right).
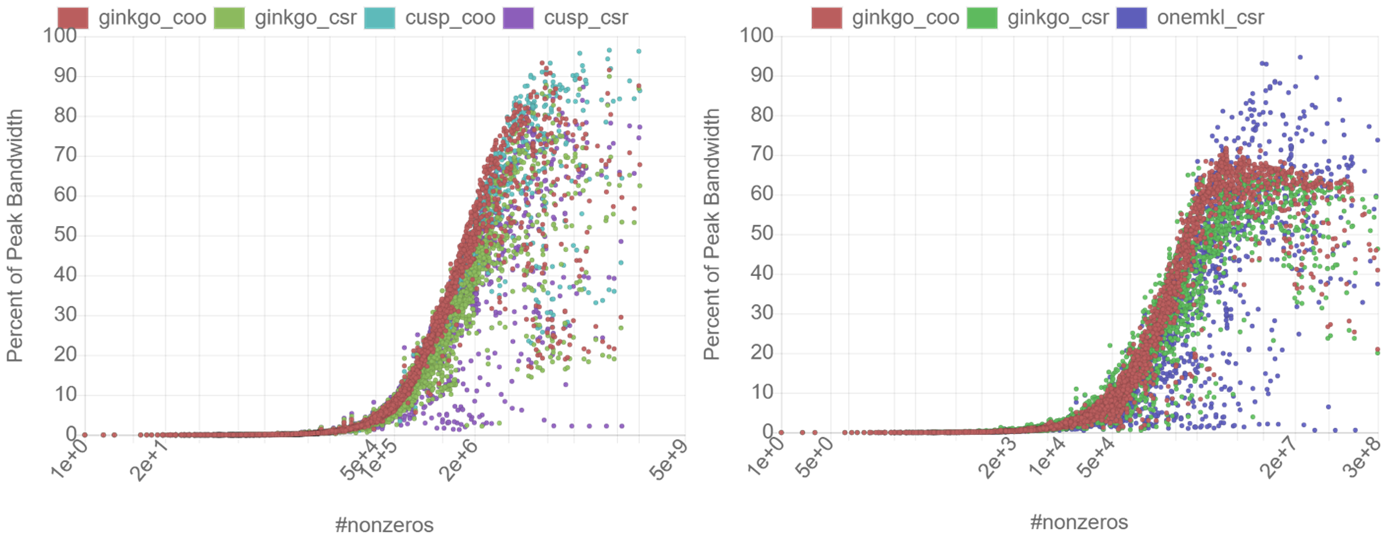
In these graphs, we do include the performance of the SpMV kernels available in the vendor libraries to compare not only against the architecture characteristics, but also against a vendor-optimized kernel. The graphs reveal that the performance ratio of the kernels is not unaffected by the code conversion via DPCT and the architecture change. However, even without applying architecture-specific kernel optimizations for the Intel GPUs, the kernels generated by DPCT remain competitive to the vendor functionality and achieve a good fraction of the theoretical peak.
Despite the immaturity of the ecosystem in its early days, it is the community involvement of Intel that makes one believe this effort has a future. Intel does a lot right when carrying out an open communication strategy in the oneAPI effort, reaching out to scientists already early on, welcoming recommendations from the community and fixing bugs at the earliest convenience, allowing for community code contributions in the oneAPI libraries and making them open-source, and providing with the Intel DevCloud a platform where early adopters can already get a feeling of how running code on Intel GPUs feels like.
[1] Yu-Hsiang M. Tsai, Terry Cojean, and Hartwig Anzt: Porting a sparse linear algebra math library to Intel GPUs, https://arxiv.org/abs/2103.10116
Author Bio – Hartwig Anzt
Hartwig Anzt is a Helmholtz-Young-Investigator Group leader at the Steinbuch Centre for Computing at the Karlsruhe Institute of Technology (KIT) and Research Scientist in Jack Dongarra’s Innovative Computing Lab at the University of Tennessee. He obtained his Ph.D. in Mathematics at the Karlsruhe Institute of Technology in 2012. Hartwig Anzt is part of the U.S. Exascale Computing Project (ECP) where he is leading the cross-laboratory Multiprecision Focus Effort. He also leads the numerical solver effort in the upcoming EuroHPC project MICROCARD. Hartwig Anzt has a long track record of high-quality software development. He is author of the MAGMA-sparse open-source software package managing lead and developer of the Ginkgo numerical linear algebra library.


























































