 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
MLPerf.org, the young ML benchmarking organization, today issued its third round of inferencing results (MLPerf Inference v1.0) intended to compare how well various systems and accelerators perform inferencing on a suite of standard exercises. As in the past, systems using Nvidia GPUs dominated the results – not surprising since so few other accelerators were used. Overall, MLPerf reported 1994 results from 17 submitting organizations in both datacenter and edge categories.
Also included in the latest results round were a set of power metrics co-developed with prominent benchmarking group Standard Performance Evaluation Corp. (SPEC).
![]() “The ability to measure power consumption in ML environments will be critical for sustainability goals all around the world,” said Klaus-Dieter Lange, SPECpower committee chair, in the MLPerf announcement. “MLCommons developed MLPerf in the best tradition of vendor-neutral standardized benchmarks, and SPEC was very excited to be a partner in their development process. We look forward to widespread adoption of this extremely valuable benchmark.
“The ability to measure power consumption in ML environments will be critical for sustainability goals all around the world,” said Klaus-Dieter Lange, SPECpower committee chair, in the MLPerf announcement. “MLCommons developed MLPerf in the best tradition of vendor-neutral standardized benchmarks, and SPEC was very excited to be a partner in their development process. We look forward to widespread adoption of this extremely valuable benchmark.
Digging out differentiating value from the MLPerf results isn’t easy. Because systems configurations vary, it is necessary to closely review individual results of specific systems and their configurations (accelerators, memory, etc.) on specific workloads. Happily, MLPerf provides easy access to the data for slicing and dicing.
It is possible but perhaps less useful to sort the data on a topline basis. For example, in the closed, datacenter category, systems from Inspur, DellEMC, Nvidia and Supermicro had the top scores (queries per sec) on ImageNet using the Resnet model. In the closed, edge category, Qualcomm posted the best performance (latency) for the same test followed by DellEMC and Nvidia.
Broadly MLPerf has organized its benchmark efforts into two divisions – closed (standard apples-to-apples test) and open (allows some variation) – and three categories – available (systems/components are available now); preview (systems/components will appear on next round of tests); and R&D/Internal (most speculative and latitude). MLPerf says, “[It] aims to encourage innovation in software as well as hardware by allowing submitters to re-implement the reference implementations. MLPerf has two Divisions that allow different levels of flexibility during reimplementation. The Closed division is intended to compare hardware platforms or software frameworks “apples-to-apples” and requires using the same model as the reference implementation. The Open division is intended to foster innovation and allows using a different model or retraining.”
Shown below are the MLPerf models and scenarios used in its latest inference exercise.

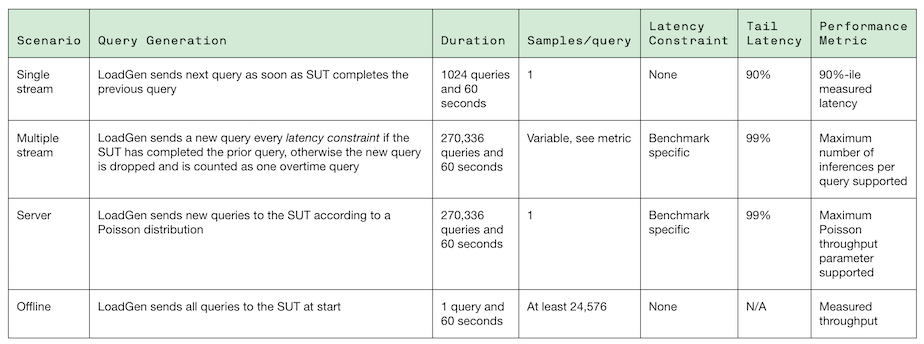
Submitters included: Alibaba, Centaur, DellEMC, EdgeCortix, Fujitsu, Gigabyte, HPE, Inspur, Intel, Krai, Lenovo, Moblint, Neuchips, Nvidia, Qualcomm, Supermicro and Xilinx.
![]()
Today’s inference results follow a similar release last October. “The schedule that we’ve set for inference and training [releases] is that they are six months apart. So we’ll have inference in Q1, training in Q2, inference in Q3, and training in Q4,” said David Kanter, executive director of MLCommons, the parent organization of MLPerf. Last year the pandemic forced MLPerf to skip a cycle. The plan is to return to that schedule.
The broad idea is that MLPerf will provide useful metrics for use in evaluating and selecting systems and accelerators. So far, Nvidia is the main participant among accelerator suppliers, although Intel had Xeon-based submissions and there were Arm- and FPGA-based entries. Again, the proof is in the details with Intel arguing its 3rd gen Xeon CPUs, with built-in AI acceleration, are sufficient and cost-effective for many application. Likewise, Arm supporters say its low-power characteristics make it a strong candidate for edge applications.
This is from Intel’s Wei Li, VP and GM, machine learning performance, “We continue to submit a wide range of MLPerf results across data types, frameworks, and usage models ranging from image processing, natural language processing (NLP), and recommendation systems. We do this because we know how important it is for customers to understand performance expectations from their Xeon CPUs, to decide whether they deliver the performance and TCO for their unique needs. Not only did we deliver more compute and memory capacity/bandwidth with our new 3rd Gen Xeon processors (formerly codenamed “Ice Lake”), but we also realized a big jump in per socket performance – up to 46% more compared to Cascade Lake such as ResNet50-v1.5 in v0.7.”
Dell ran the MLPerf inference benchmarks on a wide range of systems and Dell exec Acosta Armando offered this in a written statement, “With so many technology choices for AI workloads, MLPerf benchmarks provide insight into the performance implications of various computing elements. At Dell Technologies, we continue to push technology, so you can go further. We are committed to giving our customers choice and helping them fine-tune their infrastructure to fit their workloads and environments. That’s why we submitted 124 entries with 11 combinations of CPUs and accelerators. We want you to find the best platform for your needs.”
(MLPerf provided similar written statements from many of the latest round of submitters and HPCwire has included them at the end of this article.)
It does seem that MLPerf is gaining market traction. At a press-analyst pre-briefing earlier this week, Robert Daigle, AI business and innovation leader for Lenovo, said, “We’re already seeing MLPerf in RFP requests from customers as a standard way to evaluate infrastructure. So it is [becoming] very important to customers is a starting point.”
MLPerf has received criticism because it has not attracted participation from many of the new accelerator companies such as Habana (now Intel), Cerebras, SambaNova et. al. Others point out most of those chips are not yet widely-used and that the cost (resources and time) required to prepare submissions to MLPerf (inference or training) isn’t insignificant. Presumably a greater diversity of AI chips will participate in MLPerf over time.
Longtime AI watcher Karl Freund, founder and principal analyst, Cambrian.ai told HPCwire, “While I am disappointed that more companies do not submit, all AI chip aspirants run the MLPerf code to understand their chips’ performance, which will improve their software and even improve their future designs. And customers will increasingly demand results, or run it themselves, even if these results are not submitted or made public. It’s still very early in the AI game, and MLPerf will play a huge role as the market matures.”
Nvidia hasn’t been shy about touting its performance, and left unchallenged, perhaps it shouldn’t be. Nvidia GPU-equipped systems fared well including those with its latest A30 and A10 GPUs.
Paresh Kharya, senior product director, Nvidia, said in a pre-briefing, “We outperformed the competition across the board. A100 continues to be the highest performing accelerator in the market across all of these application workloads. Nvidia was the again the only company to submit across all of these different tests. The A100 was between 17 times to 314 times faster than the best CPU submissions across these tests. There were not a lot of chip startup submissions. There’ve been lot of claims, but again, they’re missing from submitting to the standard tests. There was submissions from Qualcomm’s AI 100 on two tests, the computer vision Resnet 50 and SSD large, and A100 outperformed the Qualcomm submissions.
“We’re seeing a very similar sort of trend in in this slide. Edge scenarios, we’ve covered single stream and multi stream. But offline is a common scenario. There were some submissions from EdgeCortix, which used Alveo from Xilinx as their solution. There were submissions from Centaur. We submitted our edge GPUs, as well as our Jetson Xavier. The results that you see here (below) are normalized to Jetson Xavier NX. Across the board you see Nvidia’s results outperforming the competition,” said Kharya.
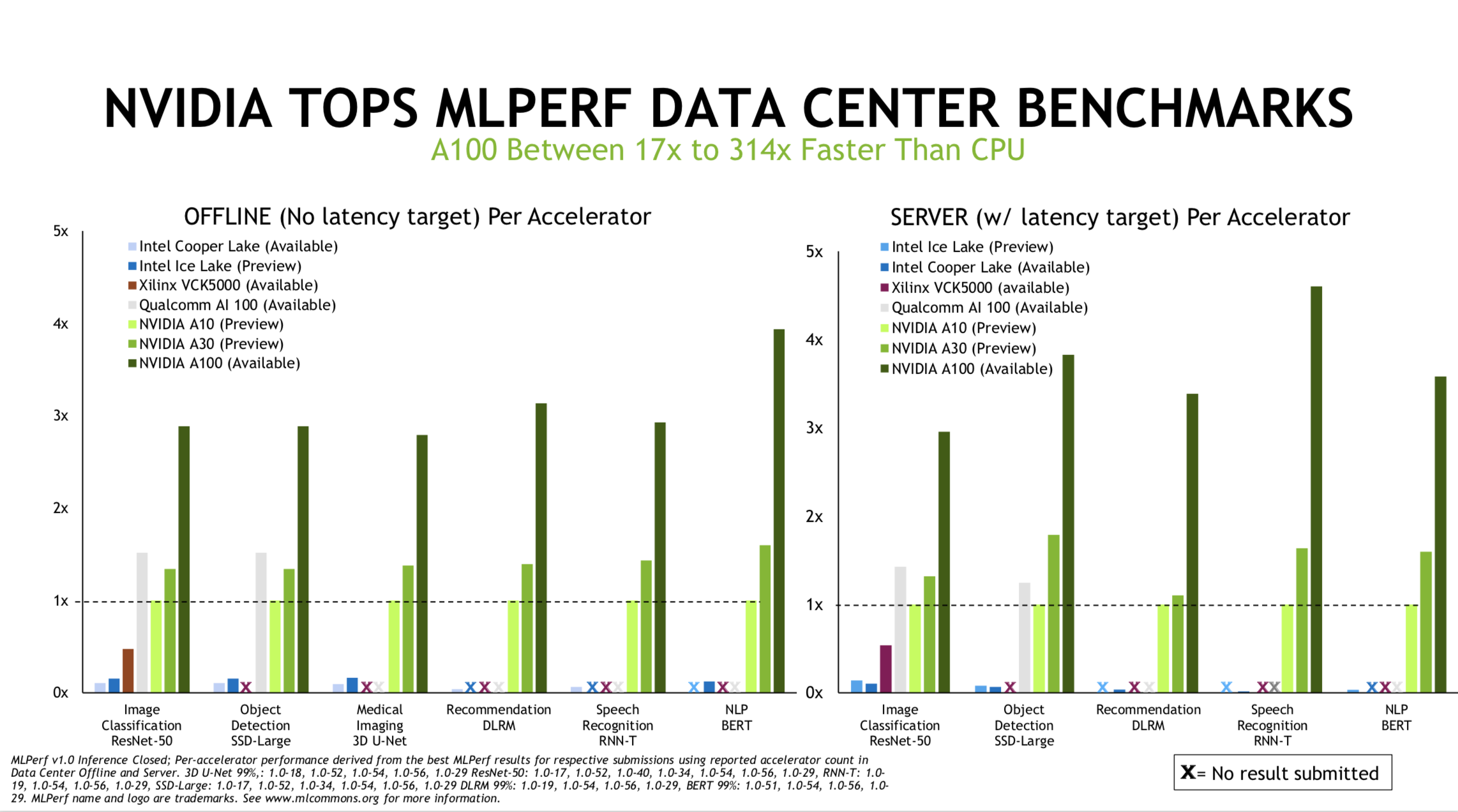


Competitive zeal is never lacking at Nvidia.
Besides adding the power category, MLPerf also made two small rule changes. “One is that for datacenter submissions, we require that any external memory be protected with ECC,” said Kanter. “And we also adjusted the minimum runtime, to better capture sort of equilibrium behavior. Many of you are familiar with diamond dynamic voltage and frequency scaling systems where when the system is, you know, cool, you can run at a faster frequency and get more performance. Well, you know, the reality is we kind of want the steady state behavior, especially for things in the data center. And you know, that for like, say, a client device, like a notebook or a smartphone, that’s sort of different animal, but, you know, this is more focused on data center edge systems.”
Link to MLPerf inference data set, https://mlcommons.org/en/inference-datacenter-10/
Link to MLPerf release, https://mlcommons.org/en/news/mlperf-inference-v10/
Link to Nvidia release, https://nvidianews.nvidia.com/news/nvidia-sets-ai-inference-records-introduces-a30-and-a10-gpus-for-enterprise-servers
SUBMITTER STATEMENTS PROVIDED BY MLPERF
The following descriptions were provided by the submitting organizations as a supplement to help the public understand the submissions and results. The statements do not reflect the opinions or views of MLCommons.
Alibaba, Weifeng Zhang, Chief Scientist of Heterogeneous Computing, Alibaba Cloud Infrastructure
“Established in 2009, Alibaba Cloud, the digital technology and business intelligence backbone of Alibaba Group, is among the world’s top three IaaS providers, according to Gartner. Alibaba Cloud provides a comprehensive suite of cloud computing services to businesses worldwide, including merchants doing business on Alibaba Group marketplaces, startups, corporations and public services.
“In this round of submission to MLCommons Inference Benchmark 1.0, we leveraged Alibaba’s compiler-based heterogeneous computing acceleration platform, named Sinian, to automatically search and optimize the neural network architecture for image classification. The Sinian-designed neural network is significantly more efficient to achieve the benchmark accuracy goal than standard ResNet-50. Moreover, Sinian conducts op fusion optimizations very aggressively across a very large scope to unleash the full computing power of Nvidia’s GPUs.
“Overall, in our open division results, the system performance with a T4 GPU goes beyond quintuple of our previous submission to Inference ver0.5 in the closed division. Similarly, the system with 8 A100 GPUs reaches an impressive performance number of 1 million samples per second. Sinian also performs full-stack optimizations for machine learning applications, taking advantage of new GPU architectures with least manual effort. It helps boost the performance of the system with an A10 GPU (in preview category) to more than 50% of the system with an A100 GPU.”
Centaur, speaker: N/A
“Centaur Technology’s AI Coprocessor (AIC) is the industry’s first high-performance, deep learning (DL) coprocessor integrated into a server-class x86 processor. The company is one of the founding members of MLCommons and has submitted certified MLPerf results in every release of the Inference benchmark. The AIC-based system-on-chip (SoC) targets Edge server applications, bringing the combined benefit of high-performance x86 processing and low-latency AI acceleration in a single, cost-effective chip. The AIC provides 20 tera-operations-per-second compute capability for AI workloads. The SoC integrates a fast memory system and eight high-performance x86 CPU cores that handle general-purpose computing while assisting with AI workloads.
“Centaur proves its AI performance with official scores for MLPerf v1.0 Inference (Edge system, Closed division, Available category). The AIC-accelerated x86 SoC achieved an impressive sub-millisecond latency (0.976 ms) on ResNet-50 and 1.178 ms latency for SSD MobileNet-V1. The system produced equally impressive throughputs of 1,281 FPS for ResNet-50 and 1,988 FPS for SSD MobileNet-V1. These scores reflect Centaur’s software advances with approximately 10% latency improvement and 2% throughput improvement, compared to its prior MLPerf v0.7 submission.
“Centaur’s AIC-accelerated x86 SoC’s target cost-sensitive and space-constrained edge-server products that are out of reach for many other AI accelerators. DL systems are commonly offered as massive, cloud-based datacenters or tiny, lower-performance devices. This creates a large gap in DL hardware solutions where high performance, small form factor, and secure local processing are key. Visit the website to learn more about how Centaur Technology is using its AIC and x86 SoC expertise to deliver the best solutions to these AI markets.”
Dell Technologies, Armando Acosta, Dell Technologies Global HPC, AI and Data Analytics product management and planning
“With so many technology choices for AI workloads, MLPerf benchmarks provide insight into the performance implications of various computing elements. At Dell Technologies, we continue to push technology, so you can go further. We are committed to giving our customers choice and helping them fine-tune their infrastructure to fit their workloads and environments. That’s why we submitted 124 entries with 11 combinations of CPUs and accelerators. We want you to find the best platform for your needs.
“Given that more performance often results in more heat, power consumption is an important consideration in the design of efficient systems for TCO, so we go to great lengths to optimize the power and cooling algorithms on our systems. We captured and reported power consumption data as part of our submission, and we commend MLCommons for adding power consumption as a reportable metric.
“For customers to get the most out of their systems, optimization is a must, and we are committed to sharing in best practices for the benefit of the community. Come take a test drive in one of our worldwide Customer Solution Centers. Collaborate with our HPC & AI Innovation Lab and/or tap into one of our HPC & AI Centers of Excellence.”
EdgeCortix, Hamid Reza Zohouri, director of product
“EdgeCortix Inc. an AI hardware acceleration startup founded in late 2019, participated in MLPerf v1.0 Inference round as part of our endeavour to bring energy-efficient machine learning inference to the edge. EdgeCortix takes advantage of a tightly coupled compiler stack called MERA, together with their reconfigurable processor architecture named Dynamic Neural Accelerator (DNA), in order to reduce latency while keeping hardware utilization high for machine learning inference on streaming data. Our software stack enables seamless execution of deep neural networks written in PyTorch or TensorFlow-Lite on DNA, while effectively coordinating data movement with the host processor. The inference flow does not require custom quantization or model changes, and can directly make use of post-training quantizers built into Pytorch & TensorFlow-Lite. Our DNA processor IP is provided as synthesized bitstreams for FPGAs under the DNA-F series, as well as fully configurable IP for ASICs under the DNA-A series.
“To show early performance of DNA and the robustness of our software, in this round we submitted results under the edge category, using a DNA-F200 (3.7 INT8 TOPS peak) bitstream deployed over-the-air on a Xilinx Alveo U50 FPGA. In the closed division we submitted results for ResNet-50 written and quantized to INT8 in Pytorch and compiled with MERA, which achieved a batch-1 (single-stream) latency of 6.64 ms. In the open division, we submitted results from INT8 quantized MobileNet-v2 model available from Pytorch’s torchvision without any modification. This achieved a batch-1 latency of 2.61 ms.
“Our results highlight the high performance of DNA architecture despite being limited by the FPGA fabric — a limitation that would be eliminated when DNA is integrated into an ASIC, instead. Moreover, we showcase our robust software stack that can readily run multiple types of neural networks on real hardware, across FPGAs or ASICs.”
Fujitsu, speaker: N/A
“Fujitsu is a leading information and communications technology company that supports business through delivering robust and reliable IT systems by a group of computing engineers.
We participated in this round of MLPerf inference by measuring the inference performance of four types of neural networks: image recognition, object detection, natural language translation, and recommendation. We would like to highlight the amazing price-performance of our benchmark results, using a combination of an entry-level CPU and the latest GPU. Although the core count and CPU clock count are lower than those of the high-end model, the performance of the neural network measured this time is enough, and the performance is almost equivalent to that of the high-end model.
“No special software or settings are used for measurement. We used software published on the Internet and parameters published on the MLPerf site. Anyone can use it easily.
We will realize our brand promise, “shaping tomorrow with you” by proposing the optimum solution of performance and cost according to the customer’s application.”
Gigabyte, Pen Huang, product manager and product planning
“GIGABYTE Technology, an industry leader in high-performance servers, practiced in MLPerf Inference v1.0, which model: G492-ZD0 with the latest new Technology-PCIE Gen4 product, designed with NVIDIA HGX A100 80GB the most powerful end-to-end AI and HPC platform for data centers. It allows researchers to rapidly deliver real-world results and deploy solutions into production at scale.
“The test result addresses the excellent performance at Speech-to-text and Natural Language Processing two application field specially. Also, we could help customers to optimize system hardware configuration to enhance the performance for other applications.
“GIGABYTE will continue optimization of product performance, to provide products with high expansion capability, strong computational ability and applicable to various applications at data center scale.”
Inspur, Shawn Wu, vice minister of AI & HPC application software
“NF5488 is Inspur’s flagship server with extreme design for large-scale HPC and AI computing. It contains 8 A100 NVLINK GPUs and 2 powerful general-purpose CPUs, offers AI performance of 5 petaFLOPS and a high bandwidth of GPU-GPU Communication of 600GB/s. NF5488 system is capable of high temperature tolerance with operating temperature up to 40℃. It can be deployed in a wide range of data centers with 4U design, greatly helps to lower cost and increase operational efficiency.
“NF5468M6 system presents innovative designs and strikes a balance between superior performance and flexibility. It provides Balance/Common/Cascade topologies with software one-button switch, which well meets increasingly complex and diverse AI computing needs.
NE5260M5 is an edge server with building blocks optimized for edge AI applications, and 5G applications with capability of operating at temperatures between -5℃~45℃, and with features of high temperature tolerance, dustproof, corrosion-proof, electromagnetic compatibility, and quake-proof.
“In the offline scenario of datacenter closed division, the performance of RNN-T, Bert and DLRM are improved by 30.08%, 12.5% and 20.6%, respectively on NF5488A5 compared with the best performance achieved in Inference v0.7. In server scenario of datacenter closed division, the performance of ResNet-50, RNN-T, Bert and DLRM are improved by 4.84%, 46.81%, 19.97% and 23.39% respectively compared with the best performance achieved in Inference v0.7.
“In offline scenario of edge closed division, the performance of ResNet-50, RNN-T, Bert, 3D-Unet, SSD-Large and SSD-Small are improved by 77.8%, 129.4%, 74.9%, 110.89%, 70.69% and 72.17%, respectively on NE5260M5 compared with the best performance achieved in Inference v0.7. In single-stream scenario of edge closed division, the performance of those models: ResNet-50, RNN-T SSD-Large and SSD-Small are improved by 7.06%, 17.28%, 1.7% and 3.23% respectively compared with the best results in V0.7.”
Intel, Wei Li, vice president and general manager of Machine Learning Performance
“AI is a rich field with business demand for a variety of hardware. I would classify it into 3 categories: CPU, GPU and dedicated accelerator. Intel is investing in all 3 categories. Today, I will cover CPU AI. Businesses are choosing CPUs for AI because they not only run AI workloads but also enterprise applications. AI is really an end-to-end workload that starts with analytics where training and inference is a portion of the workflow. Quite often, CPUs can deliver an optimal solution for mixed workloads in terms of performance and total cost of ownership (TCO).
“Intel submitted MLPerf results this time on 3rd Gen Intel® Xeon® Scalable processors, which are the only mainstream data center CPU with built-in AI acceleration, support for end-to-end data science tools, and a broad ecosystem of innovative AI solutions. Intel is making it simpler and faster. We continue to submit a wide range of MLPerf results across data types, frameworks, and usage models ranging from image processing, natural language processing (NLP), and recommendation systems. We do this because we know how important it is for customers to understand performance expectations from their Xeon CPUs, to decide whether they deliver the performance and TCO for their unique needs. Not only did we deliver more compute and memory capacity/bandwidth with our new 3rd Gen Xeon processors (formerly codenamed “Ice Lake”), but we also realized a big jump in per socket performance – up to 46% more compared to Cascade Lake such as ResNet50-v1.5 in v0.7. We continue to optimize deep learning software and see up to 2.7X performance improvement compared to the last round of MLPerf submissions such as DLRM.”
Lenovo, Robert Daigle, AI Business & Innovation leader
“At Lenovo, we believe smarter technology can enrich lives, advance research and transform organizations of all sizes. We believe that Artificial Intelligence will play a critical role in both large and small organizations but, one of the key challenges with AI today, is the lack of standards and methods to evaluate the efficiency and effectiveness of infrastructure that supports AI workloads. Lenovo is a proud member of MLCommons and we’re committed to the mission of accelerating machine learning innovation that will benefit everyone. Our goal in the latest round of MLPerf Inference v1.0 benchmarks is to demonstrate performance metrics that best represent real-life use cases and enable organizations to make informed decisions for their AI infrastructure. As a result, you will see a broader range of benchmark results from Lenovo since we publish results across all categories instead of focusing on a select few.
“We are proud to be the only participant to provide comprehensive results for all of our submitted systems, demonstrating comprehensive performance to our current and future customers. The AI-Ready ThinkSystem SE350 with the NVIDIA T4 Tensor Core GPU, is a true edge server platform that can be deployed outside of a data center or IT closet while delivering enterprise grade performance and reliability in a rugged, compact form factor. With the ThinkSystem SE350, Lenovo demonstrates data center grade performance at the edge where it is needed to reduce latency and provide a more cost-efficient architecture. In the data center, the AI-Ready ThinkSystem SR670 demonstrates excellent performance across all data center benchmarks and is one of only two submissions providing NVIDIA A40 results.
“Lenovo leverages MLPerf benchmarking far beyond community submissions and leverages MLPerf to validate the performance of AI solutions, Reference Architectures and customer designs, ensuring the overall architecture maximizes performance and provides the best value for our customers.”
Krai, Anton Lokhmotov, founder
“Krai is a new startup, but our core team is not new to MLPerf. As dividiti, we submitted as many results to MLPerf Inference v0.5 and v0.7, as other 30 submitters combined. As Krai, we continued the tradition, submitting 1000+ results to v1.0, including 750+ with power measurements. We also take pride in having helped our partners, including Arm, Dell and Qualcomm, prepare highly competitive and fully compliant submissions.”
“Key to our success in performing thousands of experiments lies in using automated benchmarking workflows. Workflow automation turns a tedious and error-prone process into a fun and rewarding activity. Moreover, workflow users (e.g. MLPerf reviewers, industry analysts and potential buyers) can quickly reproduce and thus fully trust the benchmarking results. Eventually, we aim to enable easy validation and fair comparison of all MLPerf submissions.
“We are motivated by demonstrating the vast design space for ML inference. We view results on general-purpose systems such as the Raspberry Pi 4 as a useful vehicle for exploring model design trade-offs: from low accuracy models taking a few milliseconds to high accuracy models taking a few hundred milliseconds per inference. Moreover, tying the performance to the power consumption, the Raspberry Pi 4 can run the ResNet-50 workload at about 0.25 inferences per second per Watt. This baseline really puts it into perspective that an accelerated system such as the Qualcomm Edge AI Development Kit can run the same workload at over 200 inferences per second per Watt!
“We view rigorously benchmarking ML inference as only our first steps. We are fascinated by the opportunities that overall system optimization – from workloads to hardware – can bring to emerging industries such as robotics.”
Nvidia, Dave Salvator, senior manager, product marketing in Nvidia’s accelerated computing group
“Industry-standard benchmarks are essential for helping technology customers make informed buying decisions. Based upon a diverse set of usages and scenarios, the MLPerf 1.0 Inference benchmark is a proving ground where AI Inference solutions can be measured and compared. NVIDIA is a proud member of MLCommons, and we have actively collaborated in developing both MLPer training and inference benchmarks since their inception.
“In version 1.0, NVIDIA has once again delivered outstanding performance across all seven workloads, both for the Data Center and Edge suites, which span computer vision, medical imaging, recommender systems, speech recognition and natural language processing. Our TensorRT inference SDK played a pivotal role in making these great results happen. Nearly all NVIDIA submissions were done using INT8 precision, which delivers outstanding performance while meeting or exceeding MLPerf’s accuracy requirements.
“A new feature of MLPerf Inference 1.0 is measuring power and energy efficiency. NVIDIA made submissions for all Data Center scenarios, and nearly all of the Edge scenarios, a testament to our platform’s versatility, but also its great performance and energy efficiency.
“NVIDIA also made multiple submissions using our Triton Inference Server software, which simplifies the deployment of AI models at scale in production. These Triton-based results were within 3% of our custom implementations for each workload. Furthermore, Triton-based entries using CPU-only platforms were also submitted to demonstrate Triton’s versatility.
“Ampere-based GPUs like the NVIDIA A100 support Multi-Instance GPU (MIG), which lets developers partition a single GPU into as many as seven GPU instances. One of our MIG submissions demonstrated that when a GPU is fully loaded, with MIG instances simultaneously running all the diverse workloads of the MLPerf Inference 1.0 suite, each instance achieves 98% of the performance of that instance running on an otherwise idle GPU.
“All software used for NVIDIA submissions is available from the MLPerf repo, NVIDIA’s GitHub repo, and NGC, NVIDIA’s hub for GPU-optimized software for deep learning, machine learning, and high-performance computing.”
Qualcomm, John Kehrli, senior director of product management at Qualcomm
“The Qualcomm Cloud AI 100 leverages the Company’s heritage in advanced signal processing and power efficiency to deliver on AI inference processing in the cloud. Powered by the Qualcomm AI inference core, the AI 100 is capable of 400 TOPS and can deliver solutions from 50 TOPS devices to 100+ Peta-ops datacenter racks. The AI 100 SoC packs up to 144MB SRAM, high DDR BW and high-speed NoC. The AI 100 supports all AI Inferencing workloads, spanning ML frameworks and network models, including large networks with multi-accelerator aggregation, and incorporates full-stack AI software with comprehensive tools for cloud and edge AI deployment.
“Qualcomm partnered with MLPerf expert Krai for the Cloud AI 100 platform’s first ML Commons benchmark submission with Vision networks ResNet-50 and SSD Large. The datacenter submission uses a Gigabyte-282 Server host with five AI 100 HHHL 75W TDP accelerators. The two edge submissions use AEDK Platform with a Snapdragon™ 865 host, and AI 100 DM.2e configured for 15W TDP and AI 100 DM.2 accelerator configured for 20W TDP. Qualcomm also submitted its full system power for each benchmark workload to demonstrate its offline and server performance at low power. Qualcomm submissions are fully validated and automated for the reproducibility of benchmarks by Krai.
“Qualcomm’s ML Commons submissions delivered impressive and efficient inference benchmarks results at extremely low power with Cloud AI 100 Accelerators:
“On the ResNet-50 benchmark: The Datacenter solution using five AI 100 PCIe cards delivered 100,077 inferences per second with the system power of 562 Watts, resulting in 178 inferences per second per Watt. The Edge solution configured for 20 Watt TDP delivered 7,807 inferences per second with the system power of 36.4 Watts, resulting in a whopping 214 inferences per second per Watt.
“On the SSD-ResNet34 benchmark: The Datacenter solution delivered 1,778 inferences per second with the system power under 600 Watts. The Edge solution configured for 20 Watt TDP delivered 161 inferences per second with the system power of 36.3 Watts. The Edge solution configured for 15 Watt TDP delivered 93 inferences per second with the system power of 26.6 Watts.”
Supermicro, Chris Wong, sr. product manager, Accelerated Computing Solutions
“Supermicro has its long history of providing a broad portfolio of products for different use cases. In MLPerf Inference v1.0, we have submitted six systems in the datacenter inference category and one in the edge inference category. These are to address the performance for multiple use cases, including medical image segmentation, general object detection, recommendation systems, and natural language processing.
“Supermicro’s DNA is to provide the most optimal hardware solution for your workloads and services. For example, we provide four different systems for NVIDIA’s HGX A100 8GPU platform and HGX A100 4GPU respectively. Customers can configure the CPU and GPU baseboards based on their needs. Furthermore, we provide upgraded power supply versions to give you choices on using our cost-effective power solutions or genuine N+N redundancy to maximize your TCO. Supermicro also offers liquid cooling for HGX based-systems to help you deploy higher TDP GPU baseboards without thermal throttling.
“Supermicro HGX based platforms can pass the data directly from the device to avoid the pass-through overhead from processors and system memory. By shortening the data path to the accelerator, it shortens the latency for the whole inference experience in applications such as recommendation system in offline inference scenario.
“On the edge inference side, we submitted the high-performance blade system SBA-4119SG-X with A100 for the benchmark. This system is also configurable for two single-wide accelerators, for example, NVIDIA’s T4 or A10 GPU. Each blade itself is hardware separated, so the customers can choose what kind of accelerators they would like to use on each blade. It is also feasible if you would like to configure some of the blades as storage nodes for data that is going to be preprocessed or retrained. So, customers can have multiple purpose-built systems in a single box. We are happy to see all the results we ran on MLPerf using our portfolio of systems, and we will keep optimizing the solutions for customer’s different requirements to help achieve the best TCO.”
Xilinx, Nick Ni, director of product marketing for AI, software and ecosystem
“Xilinx is the inventor of the FPGA and adaptive SoCs. Xilinx adaptive computing devices enable Domain-Specific Architectures (DSAs) optimized for AI inference and associated pre/post-processing workloads. Xilinx devices are critical for AI productization. They support not only fast AI inferencing but also end-to-end application acceleration. For MLPerf Inference v0.7, using the ResNet-50 closed-division benchmark with our production Alveo U250 Data Center accelerator card, we demonstrated for the first time in the industry 100% of the Aveo U250 datasheet peak TOP/s. Now, for MLPerf v1.0, we have further improved the ResNet-50 inference throughput, achieving a result of 5,921 FPS using our Versal ACAP PCI-E card, a 44.6% increase compared to our previous submission. Xilinx provides the Vitis AI development environment for AI and software developers to take models trained using TensorFlow or PyTorch, and compile, quantize and optimize for Xilinx’s software-programmable adaptive computing platforms without hardware development know-how.
























































