 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this regular feature, HPCwire highlights newly published research in the high-performance computing community and related domains. From parallel programming to exascale to quantum computing, the details are here.

Simulating hundreds of millions of atoms on JUWELS
The booster module of the JUWELS supercomputer at Jülich Supercomputing Centre is capable of 44 Linpack petaflops of supercomputing power, placing it seventh on the most recent Top500 list. Here, an international team of European researchers “push[es] the boundaries of electronic structure-based ab initio molecular dynamics … beyond 100 million atoms” through a combination of several methods, demonstrating a sustained performance of 324 petaflops in mixed precision with an efficiency of 67.7 percent.
Authors: Robert Schade, Tobias Kenter, Hossam Elgabarty, Michael Lass, Ole Schütt, Alfio Lazzaro, Hans Pabst, Stephan Mohr, Jürg Hutter, Thomas D. Kühne and Christian Plessl.
Exploring Folding@home’s SARS-CoV-2 simulations
Last year, the crowdsourced computing project Folding@home banded together over a million citizen scientists to power some of the earliest simulations of key elements of the novel coronavirus. This paper explores that work, which resulted in the simulation of 0.1 seconds of the viral proteome and the opening of the spike protein complex. The researchers also describe their discovery of “over 50 ‘cryptic’ pockets [on the proteome] that expand targeting options for the design of antivirals.”
Authors: Maxwell I. Zimmerman, Justin R. Porter, Michael D. Ward, Sukrit Singh, Neha Vithani, Artur Meller, Upasana L. Mallimadugula, Catherine E. Kuhn, Jonathan H. Borowsky, Rafal P. Wiewiora, Matthew F. D. Hurley, Aoife M. Harbison, Carl A. Fogarty, Joseph E. Coffland, Elisa Fadda, Vincent A. Voelz, John D. Chodera and Gregory R. Bowman.

Scaling real-time analytics simultaneously across three supercomputers
Science infrastructure is improving, these researchers say, speeding up data and accelerating analytics – but HPC, they add, “remains largely untapped by live experiments” because of data transfer and batch-queueing impediments. To address those issues, they introduce Balsam, “a distributed orchestration platform enabling workflows at the edge to securely and efficiently trigger analytics tasks across a user-managed federation of HPC sites.” They test Balsam across the Theta, Summit and Cori supercomputers, simultaneously scaling real-time analytics from two Department of Energy light sources.
Authors: Michael Salim, Thomas Uram, J. Taylor Childers, Venkat Vishwanath and Michael E. Papka.
Automating building and testing in HPC environments
“While automated builds and deployment as well as systematic software testing have become common practice when developing software in industry, it is rarely used for scientific software, including tools,” write these authors from the Jülich Supercomputing Center. The researchers cite possible reasons: domain scientists might not get enough exposure to testing tools; the necessary infrastructures might be considered superfluous overhead; the tools might require too much modification; and more. The authors present the challenges they encountered when setting up such automated building and testing infrastructures for a series of projects, highlighting successes and remaining open issues.
Authors: Christian Feld, Markus Geimer, Marc-André Hermanns, Pavel Saviankou, Anke Visser and Bernd Mohr.
 Developing HPC benchmarks for high-resolution image training for deep learning
Developing HPC benchmarks for high-resolution image training for deep learning
In this paper, a team from Barcelona urges the development of benchmarks for high-resolution image training for deep learning on HPC systems. “[A] proper benchmark can steer the design of next-generation hardware by properly identifying … requirements, and quicken the deployment of novel solutions,” they write. To that end, the researchers assess the differences between low-resolution/fixed-shape images and high-resolution/variable-shape images, assessing how the type of image affects performance on three HPC clusters.
Authors: Ferran Parés Pont, Pedro Megias, Dario Garcia-Gasulla, Marta Garcia-Gasulla, Eduard Ayguadé and Jesús Labarta.
Teaching parallel and distributed computing concepts in simulation with WRENCH
“Teaching parallel and distributed computing topics in a hands-on manner is challenging, especially at introductory, undergraduate levels,” writes this team from the University of Hawai‘i at Mānoa and the University of Southern California. This paper focuses on teaching students to use highly distributed, heterogeneous platforms with large numbers of high-end compute nodes using a series of simulation-driven activities developed using the WRENCH simulation framework.
Authors: Henri Casanova, Ryan Tanaka, William Koch and Rafael Ferreira da Silva.
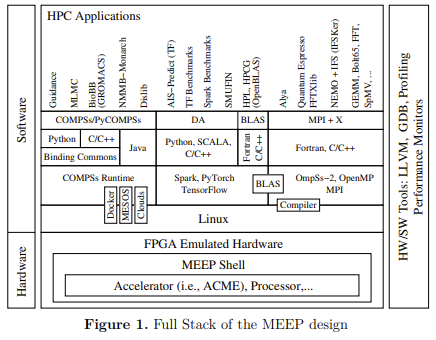 Introducing the MareNostrum Experimental Exascale Platform: MEEP
Introducing the MareNostrum Experimental Exascale Platform: MEEP
“In this paper, we introduce the vision of the MareNostrum Experimental Exascale Platform (MEEP), an open source platform enabling software and hardware stack experimentation targeting the … HPC ecosystem,” write these researchers from the Barcelona Supercomputing Center, home of the MareNostrum 4 supercomputer. MEEP, they say, is built with state-of-the-art FPGAs, “making it ideal to emulate chiplet-based HPC accelerators.” They conclude: “MEEP invites software developers and hardware engineers to build the application, compiler, libraries and the hardware to solve future challenges in the HPC, AI, ML, and DL domains.”
Authors: Alexander Fell, Daniel J. Mazure, Teresa C. Garcia, Borja Perez, Xavier Teruel, Pete Wilson and John D. Davis.
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.


























































