 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
While Nvidia (again) dominated the latest round of MLPerf training benchmark results, the range of participants expanded. Notably, Google’s forthcoming TPU v4 performed well, Intel had broad participation featuring systems with 3rd Gen Xeons and with its Habana Labs Gaudi chips, and Graphcore had submissions based on its IPU chips. There was an entry from China – Peng Cheng Laboratory – using Arm CPUs and sixty-four AI processors (Huawei Ascend 910).
In this latest round (MLPerf Training v1.0) released in concert with ISC21, MLPerf received submissions from 13 organizations and released over 650 peer-reviewed results for machine learning systems spanning from edge devices to data center servers. “Submissions this round included software and hardware innovations from Dell, Fujitsu, Gigabyte, Google, Graphcore, Habana Labs, Inspur, Intel, Lenovo, Nettrix, NVIDIA, PCL & PKU, and Supermicro,” reported MLCommons.
 You may recall that MLCommons is the entity running MLPerf which was started in 2018. MLCommons remained somewhat in the background until last December when it reorganized the team and announced, “Today, MLCommons, an open engineering consortium, launches its industry-academic partnership to accelerate machine learning innovation and broaden access to this critical technology for the public good. The non-profit organization initially formed as MLPerf now boasts a founding board that includes representatives from Alibaba, Facebook AI, Google, Intel, NVIDIA and Professor Vijay Janapa Reddi of Harvard University; and a broad range of more than 50 founding members. The founding membership includes over 15 startups and small companies that focus on semiconductors, systems, and software from across the globe, as well as researchers from universities like U.C. Berkeley, Stanford, and the University of Toronto.”
You may recall that MLCommons is the entity running MLPerf which was started in 2018. MLCommons remained somewhat in the background until last December when it reorganized the team and announced, “Today, MLCommons, an open engineering consortium, launches its industry-academic partnership to accelerate machine learning innovation and broaden access to this critical technology for the public good. The non-profit organization initially formed as MLPerf now boasts a founding board that includes representatives from Alibaba, Facebook AI, Google, Intel, NVIDIA and Professor Vijay Janapa Reddi of Harvard University; and a broad range of more than 50 founding members. The founding membership includes over 15 startups and small companies that focus on semiconductors, systems, and software from across the globe, as well as researchers from universities like U.C. Berkeley, Stanford, and the University of Toronto.”
The idea, of course, is to provide a set of machine learning benchmarks for training and inferencing that can be used to compare diverse systems. Initially, systems using Nvidia GPUs comprised the bulk of participants and to some extent that made MLPerf seem to be largely a Nvidia-driven showcase. Recent broader participation by Google, Graphcore, Intel and its subsidiary Habana is a positive step with the hope that more of the new AI accelerators and associated systems will start participating.
MLCommons reported that “Compared to the last submission round, the best benchmark results improved by up to 2.1x, showing substantial improvement in hardware, software, and system scale.” The latest training round included two new benchmarks to measure performance for speech-to-text and 3D medical imaging:
- Speech-to-Text with RNN-T. RNN-T: Recurrent Neural Network Transducer is an automatic speech recognition (ASR) model that is trained on a subset of LibriSpeech. Given a sequence of speech input, it predicts the corresponding text. RNN-T is MLCommons’ reference model and commonly used in production for speech-to-text systems.
- 3D Medical Imaging with 3D U-Net. The 3D U-Net architecture is trained on the KiTS 19 dataset to find and segment cancerous cells in the kidneys. The model identifies whether each voxel within a CT scan belongs to a healthy tissue or a tumor, and is representative of many medical imaging tasks.
The full MLPerf test training set includes BERT, DLRM, Mask R-CNN, ResNet-50 v1.5, SSD, RNN-T, 3d-UNet and MiniGO.
Similar to past MLPerf Training results, the submissions consist of two divisions: closed and open. Closed submissions use the same reference model to ensure a level playing field across systems, while participants in the open division are permitted to submit a variety of models. Submissions are additionally classified by availability within each division, including systems commercially available, in preview, and R&D.

“We’re thrilled to see the continued growth and enthusiasm from the MLPerf community, especially as we’re able to measure significant improvement across the industry with the MLPerf Training benchmark suite,” said Victor Bittorf, co-chair of the MLPerf Training working group.
The bulk of systems entered still relied on a variety of Nvidia GPUs and the company was quick to claim victory in a pre-briefing with media and analysts.
“Only Nvidia, submitted across all eight benchmarks and in the commercially available category,” said Paresh Kharya, senior director of product management, data center computing. “Nvidia’s Selene supercomputer, which is a DGX SuperPod, set all eight performance records. We completed four out of eight tests in less than a minute, the most complex test, which was the MiniGo benchmark took less than 16 minutes. Google submitted TPU v4 as a preview submission, a category that implies that it’s not yet commercially available for customers to use. And unlike the commercially available category, preview does not require software used for submissions to be available either. Comparing Google’s preview submission to Nvidia’s commercially available submission on the relatively harder tasks that took more than a minute, our DGX SuperPod outperformed [Google’s TPU v4] on 3D-Unit and Mask R-CNN.”
He added, “It’s interesting to look at normalizing the performance to a single chip, because that removes the scaling as a variable. Different submitters use different sized servers; some of used four chip servers, some eight, some has used clusters with 64, and like in case of Nvidia, we’ve used up to 4000 chips in our cluster. It’s important to note that performance does not scale perfectly with the number of chips. So in order to do a fair comparison, we took the closest chip-count submission for normalizing to a single chip, for example on Bert, Habana submitted with 8 chips, so we [compared] their array submission to our eight chips; Graphcore submitted with 64 chips, so we compared our 64-chip submission to Graphcore submission and so on. On a per chip basis as well, Nvidia A-100 set all eight performance records in the commercially available category. The A-100 was up to three times faster than Graphcore and up to eight times faster than Habana. On three of the eight [exercises] Google TPU under preview had a slight edge over A-100 in terms of the per chip normalized performance.”
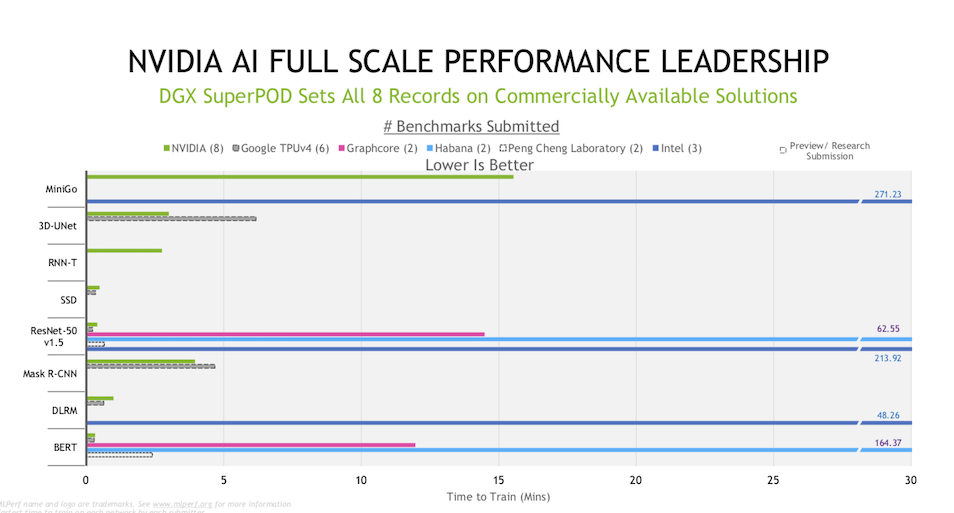
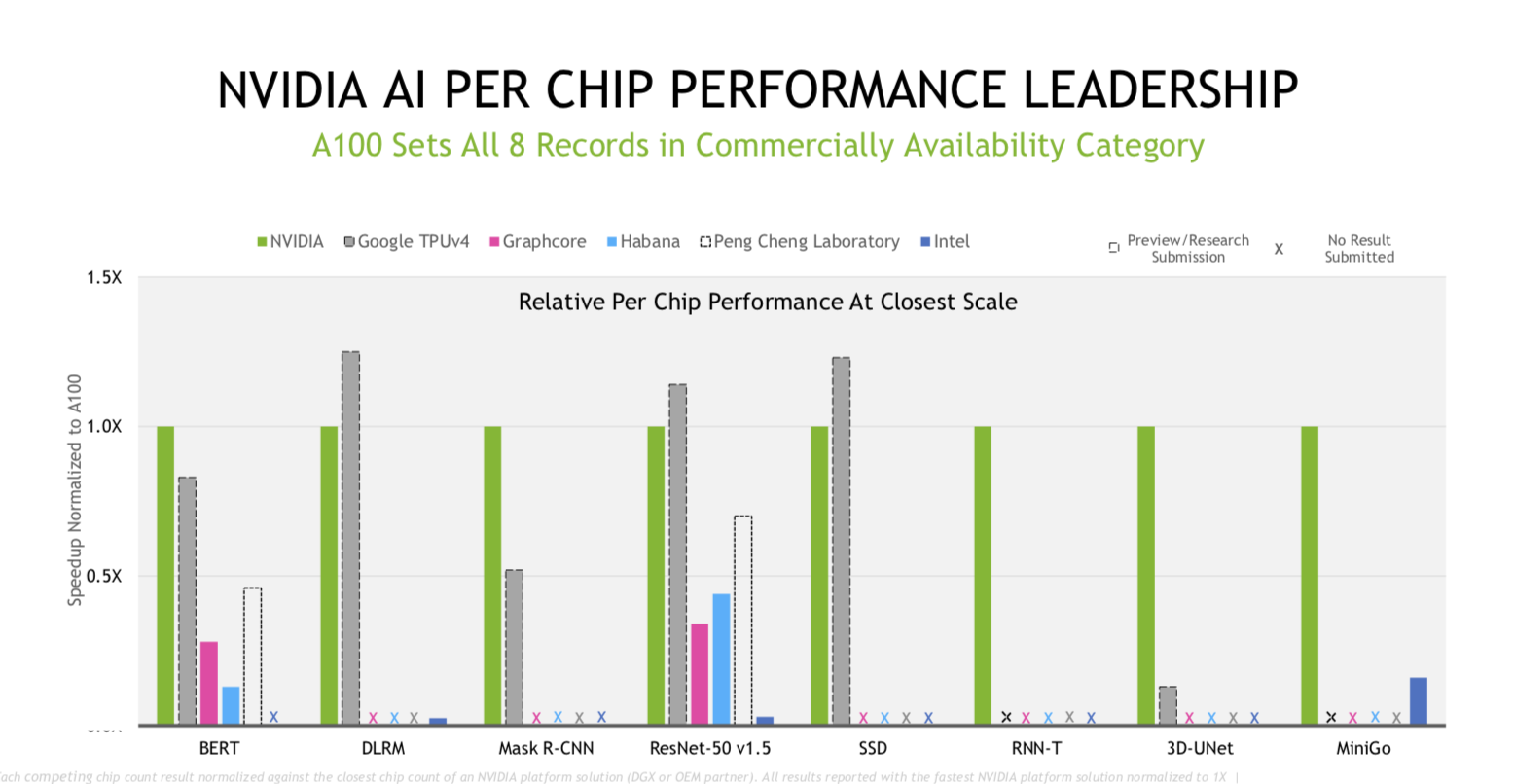
Kharya’s description, though biased, captures some of the challenges faced when interpreting MLPerf results. It is necessary to look closely at the specific system configurations, the specific exercise, and also to consider price points. That said, the overall improvement in training time on MLPerf’s exercises is testament to the rapid AI technology advances occurring. For Nvidia, Kharya singled out several software advances, including CUDA Graphs, as well as implementation of SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) as key performance advances.
As part of the exercise, MLPef invites statements from participants about their systems and their performances on MLPerf. These run the gamut from simple marketing messages to providing relevant detail about products being tested and, occasionally, an explanation of influences on the MLPerf performance. As MLPerf is still young and because part of the point of the MLPerf exercise is to provide comparisons among diverse platforms running the same tests, HPCwire has included the vendor submitted statements (lightly edited) at the end of the article.
As an example, here’s statement from Google:
“In ML Perf Training 1.0, Google has demonstrated our continued performance leadership in cloud-based machine learning infrastructure. We showcased the record-setting performance and scalability of our fourth-generation Tensor Processing Units (TPU v4), along with the versatility of our machine learning frameworks and accompanying software stack. Best of all, these capabilities will soon be available to our cloud customers.
We achieved a roughly 1.7x improvement in our top-line submissions compared to last year’s results using new, large-scale TPU v4 Pods with 4,096 TPU v4 chips each. Using 3,456 TPU v4 chips in a single TPU v4 Pod slice, many models that once trained in days or weeks now train in a few seconds. Our top-line improvements and new training times are summarized here:
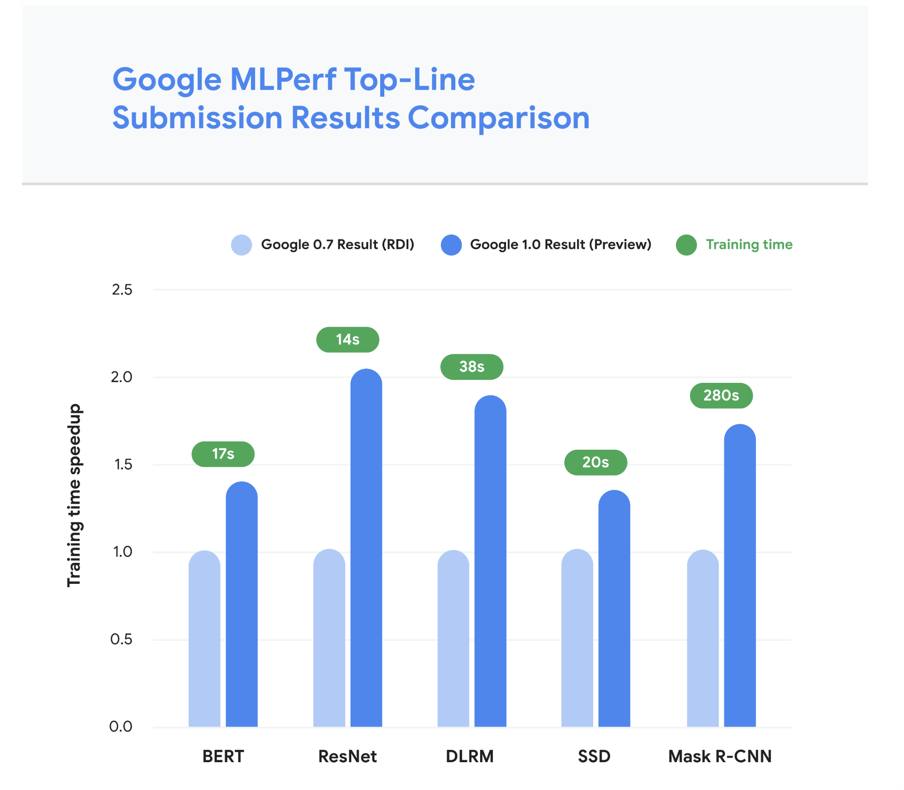
“These performance improvements were made possible by the compute power of TPU v4, unparalleled interconnect bandwidth within each TPU pod, and at-scale software optimizations leveraging novel innovations provided in the hardware.
“Large-scale machine learning training is increasingly important to Google, and we use TPU v4 Pods extensively within Google to develop research breakthroughs such as MUM and LaMDA, and improve our core products such as Search and Translate. Until recently, achieving this scale and speed of compute required building bespoke on-premise compute clusters at a considerable cost. As our CEO announced at Google I/O, we are excited to make these same exaflop-scale TPU v4 Pods publicly available via Google Cloud later this year.”
Intel said in its statement, “Leveraging Intel DL Boost with bfloat16 on a 64-socket cluster of 3rd Gen Xeon Platinum processors, we’ve shown that Xeon can scale with the size of the DL training job by adding more servers. The bfloat16 format delivers improved training performance without sacrificing accuracy or requiring extensive hyperparameter tuning. Our submissions demonstrate our continuous software optimization for popular deep learning frameworks and workloads, achieving a training time of 15 minutes for DLRM in the open division, 214 minutes for Resnet50, and 272 minutes for MiniGo.
“For DLRM open division, we show ~3x improvement in TTT over our closed division submission by enabling the following key software optimizations:
- Hybrid optimizer approach for large-batch training without a convergence penalty.
- Extend model parallelism for embedding tables along the embedding dimension to achieve larger scale-out.”
- Utilize memory footprint advantage of bfloat16 format for mixed precision training by eliminating fp32 master copy of weights”
Again, it’s best to consult the results directly. The next expected round of MLPerf testing will be on inferencing and is scheduled to be made public later this year. Participating vendors’ submitted statements are below.
Link to MLCommons announcement: https://mlcommons.org/en/news/mlperf-training-v10/
Link to MLPerf v1. training results: https://mlcommons.org/en/training-normal-10/
Link to Nvidia blog: https://blogs.nvidia.com/blog/2021/06/30/mlperf-ai-training-partners/
MLPerf provided comments from participants, lightly edited:
Fujitsu
We participated in this round, MLcommons training v1.0, by measuring the following benchmarks: MASKRCNN, Resnet50 and SSD without any special software or settings. Anyone can reproduce our results.
The system used for this measurement, PRIMGERGY GX2460 M1, is a middle range computing node. It consumes less power and small area in 2U rack mount size, and can be used for various ways, not only for training but for inference. We also participated in MLcommons previous inference round for data centers with this system. The result can be confirmed at MLcommons website.
The system has two AMD EPYC processors and four NVIDIA Tesla A100s as accelerators, which are connected with PCI express and have their own 40GB memory in HBM. Its storage is 1.75TiB SSD connected via SATA 6.0 Gbps.
Gigabyte
This round, we chose the new succession product- G492-ZD2 with the latest new Technology-PCIE Gen4 product, designed with NVIDIA HGX A100 80GB, the most powerful end-to-end AI and HPC platform for data centers. It allows researchers to rapidly deliver real-world results and deploy solutions into production at scale.
This is the first time for our team to join this competition on Training v1.0. We completed the benchmark of Image-classification, Speech-to-text and Recommendation, and will continue to study and fine-tune our configuration for more applications.
Google
In ML Perf Training 1.0, Google has demonstrated our continued performance leadership in cloud-based machine learning infrastructure. We showcased the record-setting performance and scalability of our fourth-generation Tensor Processing Units (TPU v4), along with the versatility of our machine learning frameworks and accompanying software stack. Best of all, these capabilities will soon be available to our cloud customers.
We achieved a roughly 1.7x improvement in our top-line submissions compared to last year’s results using new, large-scale TPU v4 Pods with 4,096 TPU v4 chips each. Using 3,456 TPU v4 chips in a single TPU v4 Pod slice, many models that once trained in days or weeks now train in a few seconds. Our top-line improvements and new training times are summarized here (see chart higher in the article):
These performance improvements were made possible by the compute power of TPU v4, unparalleled interconnect bandwidth within each TPU pod, and at-scale software optimizations leveraging novel innovations provided in the hardware.
Large-scale machine learning training is increasingly important to Google, and we use TPU v4 Pods extensively within Google to develop research breakthroughs such as MUM and LaMDA, and improve our core products such as Search and Translate. Until recently, achieving this scale and speed of compute required building bespoke on-premise compute clusters at a considerable cost
Graphcore
Graphcore is delighted to share its first ever set of MLPerf results, after submitting to the available category on our debut round. Our IPU-POD16 and IPU-POD64 delivered an extremely strong performance on both ResNet-50 and BERT training.
These two systems – powered by Graphcore’s second generation Intelligence Processing Unit (IPU) are designed as cost-effective solutions for specialist AI compute in the datacenter.
Characteristic features of the Graphcore IPU-POD include the disaggregation of server and AI accelerators, allowing the number of CPUs and IPUs to be configured in varying ratios, in line with the requirements of different workloads. Graphcore supports a range of host server options from leading providers, including Dell, Samsung, Supermicro and Inspur.
Central to our strong performance in MLPerf is the deployment of novel techniques including Hybrid Model and Data parallelism, FP16 master weights, the use of external streaming memory, & small batch training.
Our BERT implementation employs a packed sequencing technique whereby we pack multiple unrelated short sequences from the training dataset together to build full sequences of length 512. This reduces unnecessary computation involving padding tokens, is highly scalable and thus increases efficiency. In addition, the BERT implementation also highlights the cost benefits from disaggregating the host from the IPUs as we need only a single host within an IPU-POD64. We make further improvements to the BERT model to accelerate convergence while maintaining the target accuracy, & these improvements are reflected in our open submission.
All software used for our submissions are available from the MLPerf repository, to allow anyone to reproduce our results. The Graphcore github repository also covers new and emerging models like EfficientNet and techniques like sparsity) where the IPU’s unique architecture can enable innovators to create the next breakthroughs in machine intelligence.
Inspur
In MLCommons Training V1.0, Inspur made submissions on three systems, NF5488A5, NF5488M6 and NF5688M6. NF5488A5 is Inspur’s flagship server with extreme design for large-scale HPC and AI computing. It contains 8 A100-500W GPUs with liquid cooling. NF5488 system is capable of high temperature tolerance with operating temperature up to 40℃. It can be deployed in a wide range of data centers with 4U design, greatly helps to lower cost and increase operation efficiency.
NF5688M6 based on 3rd Gen Intel Xeon scalable processors increases performance by 46% from Previous Generation, and can support 8 A100 500W GPUs with air cooling. It accommodates more than 10 PCIe Gen4 devices, and brings about a 1:1:1 balanced ratio of GPUs, NVMe storage and NVIDIA Mellanox InfiniBand network.
In the closed division, the single node performance of Resnet50, Bert, SSD, DLRM and MaskRCNN are improved by 17.95%, 56.85%, 18.61%, 42.64% and 32.28% respectively on Inspur systems compared with the best single node performance achieved in Training v0.7.
Intel
For this submission, we’re pleased to present results for our 3rd Gen Intel Xeon Scalable processors, as well as the Habana Gaudi deep learning training accelerator.
Today, Intel demonstrates for the first time with MLPerf Training V1.0 that customers can train models as fast as they want with the Xeon servers they already have. 3rd Gen Intel Xeon Scalable processors are the only x86 data center CPU with built-in AI acceleration, including support for end-to-end data science tools, and a broad ecosystem of smart solutions.
Leveraging Intel DL Boost with bfloat16 on a 64-socket cluster of 3rd Gen Xeon Platinum processors, we’ve shown that Xeon can scale with the size of the DL training job by adding more servers. The bfloat16 format delivers improved training performance without sacrificing accuracy or requiring extensive hyperparameter tuning.
Our submissions demonstrate our continuous software optimization for popular deep learning frameworks and workloads, achieving a training time of 15 minutes for DLRM in the open division, 214 minutes for Resnet50, and 272 minutes for MiniGo.
For DLRM open division, we show ~3x improvement in TTT over our closed division submission by enabling the following key software optimizations:
- Hybrid optimizer approach for large-batch training without a convergence penalty.
- Extend model parallelism for embedding tables along the embedding dimension to achieve larger scale-out.
- Utilize memory footprint advantage of bfloat16 format for mixed precision training by eliminating fp32 master copy of weights.
These optimizations deliver high compute and scaling efficiency while reducing memory requirements to facilitate training of large models at scale, without requiring discrete accelerators, using the millions of Xeon platforms deployed worldwide. Our submission also provides a window into the ongoing software optimizations in deep learning that will carry forward to our next-generation Intel Xeon Scalable processors.
Habana Labs (owned by Intel)
We’re pleased to deliver the first results for the Habana® Gaudi® deep learning training processor, a purpose-built AI processor in Intel’s AI XPU portfolio. This Gaudi MLPerf submission and results are tangible evidence of Intel delivering on its multi-solution AI XPU strategy.
Habana’s MLPerf submission for training provides results on language (BERT) and vision (ResNet-50) benchmarks with a Supermicro Gaudi server (SMC SYS-420GH-TNGR), featuring 8 Gaudi processors. Gaudi is Habana’s first-generation training accelerator and is fabricated on TSMC 16-nanometer process.
With this MLPerf submission, Habana did not apply additional software optimization, such as data packing or layer fusion, to boost our performance. We aimed to submit results that are closest to the reference code and are representative of out-of-the-box performance that customers can get using our SynapseAI TensorFlow software today. Consequently, it is easy for customers to make small adjustments to the model (change data, switch layers), while maintaining similar performance. The MLPerf TTT results delivered on TensorFlow are similar to the training throughput our early customers see today.
This highlights the usability of Gaudi and demonstrates the capabilities of our SynapseAI software stack, which includes Habana’s graph compiler and runtime, communication libraries, TPC kernel library, firmware, and drivers. SynapseAI is integrated with TensorFlow and PyTorch frameworks and is performance-optimized for Gaudi.
We are currently working with AWS to make Gaudi-based EC2 instances available soon, where we focus on bringing significant price-performance improvements for end-customers training AI models in AWS. Gaudi’s architecture enables that thanks to high utilization and high level integration.
We are looking forward to the next submission in which we plan to optimize our results (especially for BERT), add submission at scale, and in PyTorch as well.
Lenovo
Our goal through MLPerf Training v1.0 is to bring clarity to infrastructure decisions so our customers can focus on the success of their AI deployment overall. We demonstrated performance benefits of our latest Lenovo Neptune liquid-cooled-GPU rich systems that deliver Exascale grade performance in a standard, dense data center footprint. We also showcased the efficiency and performance of our air-cooled systems, and provided both PCIe and HGX performance results that can easily be deployed by enterprises of all sizes.
Nettrix
Nettrix Information Industry (Beijing) Co., Ltd. (Hereinafter referred to as Nettrix) is a server manufacturer integrating R&D, production, deployment, and O&M, as well as an IT system solution provider. It aims to provide customers industry-wide with various types of servers and IT infrastructure products such as common rack based on X86 architecture, artificial intelligence, multiple nodes, edge computing and JDM life cycle customization.
Nettrix’s two latest AI servers: X660 G45 and X640 G40, submitted a total of 7 benchmark results in this ML Perf Training 1.0 review for BERT, DLRM, MASKRCNN, Resnet50, SSD, RNNT, and UNET3D, and some of the results in the two-way single server, achieving very good results.
X640 G40 is an all-in-one GPU server with both training and inference functions, with the ability to scale massive local storage, support many different GPU topologies, and optimize GPU interconnections for different applications and models, making it an efficient all-in-one computing platform. The X660 G45 AI server is a high-performance computing platform developed for deep learning training, with high-speed interconnections between GPUs using the NVLink bus of up to 600GB/s. In addition, each GPU can be equipped with an exclusive 200G HDR cache network and U.2 cache, making it a very good choice for training business scenarios.
Nvidia
In MLPerf v1.0, the NVIDIA ecosystem submitted on every benchmark with our commercially available platform and further improved on our record setting performance powered by NVIDIA A100 Tensor Core GPUs.
In the last 2.5 years since the first MLPerf training benchmark launched, NVIDIA performance has increased by up to 6.5x per GPU, increasing by up to 2.1x with A100 from the last round. We demonstrated scaling to 4096 GPUs which enabled us to train all benchmarks in less than 16 minutes and 4 out of 8 in less than a minute. The NVIDIA platform excels in both performance and usability, offering a single leadership platform from data center to edge to cloud.
Direct submissions were made by our partners Dell, Fujitsu, Gigabyte, Inspur, Lenovo, Nettrix and Supermicro which accounted for three-quarters of all submissions. Partners submit to MLPerf as it is an invaluable apples-to-apples benchmark for customers evaluating AI platforms as part of their vendor selection process. The majority of NVIDIA partners submitted performance results on NVIDIA Certified Systems, which are OEM servers certified by NVIDIA to bring accelerated computing to enterprise customers.
With our full stack innovation, NVIDIA continues to provide rapid year-over-year improvements. The key performance improvements in this round came from the following:
- Extended CUDA graphs across all benchmarks. Neural networks are traditionally launched as individual kernels from the CPU to execute on the GPU. In MLPerf v1.0 we launch the entire sequence of kernels as a graph on the GPU, minimizing communication with the CPU
- Implemented SHARP to double the effective interconnect bandwidth between nodes. SHARP offloads collective operations from the CPU to the network to decrease data traversing between endpoints
- Increased scale to a record number of 4096 GPUs to train a single benchmark
- Introduced spatial data parallelism to split a single image across 8 GPUs for image segmentation networks like 3D-UNet and thus use more GPUs for higher total system throughput
- Leveraged HBM2e GPU memory on A100 which increases the memory bandwidth by nearly 30% to 2 TB/s
We are constantly updating our software including our Deep learning frameworks containers to make these cutting-edge capabilities available on NGC, our software hub for GPU applications.
PCL & PKU
Peng Cheng Laboratory (PCL) is a new type of scientific research institution and is headquartered in Shenzhen, Guangdong, China. PCL focuses on the strategic, forward-looking, original scientific research and core technology development in the field of network communications, cyberspace and artificial intelligence. Peng Cheng Cloud Brain II, composed of 4,096 AI processors and 2,048 ARM Processors, is capable of the theoretical peak AI computing performance of 1E FLOPS FP16 and 2E OPS INT8.
A united team consisting of scientists and engineers from PCL and Peking University (PKU) worked on Peng Cheng Cloud Brain II and participated in MLPerf Training v1.0 round as part of our benchmarking initiative to identify the performance and needs of the systems to support ML workflows. Our united team focused on ResNet and BERT in different pod scales numbered 2, 4, and 16. One pod includes thirty-two host processors named HUAWEI Kunpeng 920, and sixty-four AI processors named HUAWEI Ascend 910. The software includes the MindSpore framework, and ModelArts as a choice. We have accumulated significant experience while participating in the MLPerf Training v1.0 project, which will benefit us in both current system usages and our future system designs.
Supermicro
In MLPerf Training v1.0, we have submitted six PCIe Gen 4 systems to address the performance for multiple use cases, including medical image segmentation, general object detection, recommendation systems, and natural language processing.
Supermicro’s SYS-420GP-TNAR, AS-4124GO-NART and AS-2124GQ-NART with NVIDIA’s HGX A100 GPUs can pass data directly from GPU to GPU, to avoid the pass-through overhead from processors and system memory. By shortening the data path to the accelerator, it shortens the training time for applications such as computer vision and recommendation system.
With multiple configurations of processors, accelerators, system form factors, cooling solutions, and scale out options, Supermicro would like to provide our customers the most comprehensive and convenient solution to solve the AI problems. We are happy to see all the results we ran on MLPerf using our portfolio of systems, and we will keep optimizing the solutions for customer’s different requirements to help achieve the best TCO.

























































