 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
At last month’s 11th International Symposium on Highly Efficient Accelerators and Reconfigurable Technologies (HEART), a group of researchers led by Martin Schulz of the Leibniz Supercomputing Center (Munich) presented a “position paper” in which they argue HPC architectural landscape of High-Performance Computing (HPC) is undergoing a seismic shift.
“Future architectures,” they contend, “will have to provide a range of specialized architectures enabling a broad range of workloads, all under a strict energy cap. These architectures will have to be integrated within each node—as already seen in mobile and embedded systems—to avoid data movements across nodes or even worse, across system modules when switching between accelerator types.”
That HPC is transforming is hardly in dispute, and the authors – Martin Schulz, Dieter Kranzlmüller, Laura Brandon Schulz, Carsten Trinitis, Josef Weidendorfer – acknowledge many familiar pressures (end of Dennard scaling, declining Moore’s Law, etc.) and propose four guiding principles for the future of HPC architecture:
- Energy consumption is no longer merely a cost factor but also a hard feasibility constraint for facilities.
- Specialization is key to further increase performance despite stagnating frequencies and within limited energy bands.
- A significant portion of the energy budget is spent moving data and future architectures must be designed to minimize such data movements.
- Large-scale computing centers must provide optimal computing resources for increasingly differentiated workloads.
Their paper, On the Inevitability of Integrated HPC Systems and How they will Change HPC System Operations, digs into each of the four areas. They note that integrated heterogeneous systems (interesting turn of phrase) “are a promising alternative, which integrate multiple specialized architectures on a single node while keeping the overall system architecture a homogeneous collection of mostly identical nodes. This allows applications to switch quickly between accelerator modules at a fine-grained scale, while minimizing the energy cost and performance overhead, enabling truly heterogeneous applications.”
A core ingredient in achieving this kind of integrated heterogeneity is the use of chiplets.
“Simple integrated systems with one or two specialized processing elements (e.g., with GPUs or with GPUs and tensor units) are already used in many systems. Research projects, like ExaNoDe, are currently investigating integration with promising results. Also, several commercial chip manufacturers are rumored to be headed in this direction,” write the researchers. “Currently and most prominently, the European Processor Initiative EPI) is looking at a customizable chip design combining ARM cores with different accelerator modules (Figure 1). Additionally, several groups are experimenting with clusters that GPUs and FPGAs within nodes, either for alternative workloads directed at the appropriate architecture or for solving large parallel problems with algorithms mapped to both architectures. Future systems are likely to push this even further, aiming at a closer integration and a larger diversity of architectures, leading to systems with more heterogeneity and flexibility in their usage.”

This integrated approach is not without challenges, agree the researchers: “[W]hile it is easy to run a single application across the entire system— since the same type of node is available everywhere—a single application is likely not going use all specialized compute elements at the same time, leading to idle processing elements. Therefore, the choice of the best-suited accelerator mix is an important design criterion during procurement, which can only be achieved via co-design between the computer center and its users on one side and the system vendor on the other. Further, at runtime, it will be important to dynamically schedule and power the respective compute resources. Using power overprovisioning, i.e., planning for a TDP and maximal node power that is reached with a subset of dynamically chosen accelerated processing elements, this can be easily achieved, but requires novel software approaches in system and resource management.”
They note the need for programming environments and abstractions to exploit the different on-node accelerators. “For widespread use, such support must be readily available and, in the best case, in a unified manner in one programming environment. OpenMP, with its architecture-agnostic target concept, is a good match for this. Domain-specific frameworks, as they are, e.g., common in AI, ML or HPDA (e.g., Tensorflow, Pytorch or Spark), will further help to hide this heterogeneity and help make integrated platforms accessible to a wide range of users.”
To cope with intra-node device diversity and inevitable idle periods among various devices, the researchers propose developing a “new level of adaptivity coupled with dynamic scheduling of compute and energy resources to exploit an integrated system fully.” The core of this adaptive management approach, the suggest, is a feedback loop, as shown in figure 2 below.
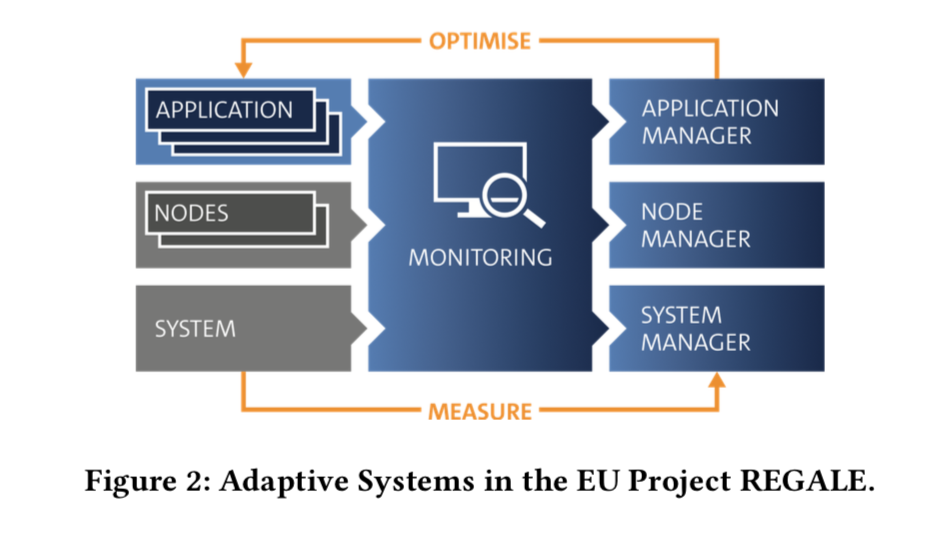
This adaptive approach is being investigated as part of EU research project REGALE, launched this spring. REGALE uses measured information across all system layers and uses that information to adaptivity drive the entire stack:
- Application Level. Changing application resources in terms of number and type of processing elements dynamically.
- Node Level. Changing node settings, e.g. power/energy consumption via techniques like DVFS or power capping as well as node level partitioning of memory, caches, etc.
- System Level. Adjusting system operation based on work- loads or external inputs, e.g., energy prices or supply levels.
The position paper is a quick read and best done directly. While the level and type of integration may vary, in their conclusion the researchers, “argue that such integration has to be on-node or even on-chip in order to: minimize and shorten expensive data transfers; enable fine-grained shifting between different processing elements running within a node; and to allow applications to utilize the entire machine for scale-out experiments rather than only individual modules or sub-clusters of a particular technology.”
Only such an approach, they contend, will enable design and deployment of large-scale compute resources capable of providing a diversified portfolio of computing, at scale and at optimal energy efficiency. Time will tell.
Link to paper: https://dl.acm.org/doi/10.1145/3468044.3468046

























































