 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
It’s an understatement to say the effort to adapt AI technology for use in scientific computing has gained steam. Last spring, the Department of Energy released a formal report – AI for Science – suggesting an AI program not unlike the exascale program reaching fruition now. There’s also the broader U.S. National Artificial Intelligence Initiative pushing for AI use throughout society. Last week, as part of a year-long celebration of its 75th founding anniversary, Argonne National Laboratory held a Director’s Special Colloquium on AI for Science: From Atoms to the Cosmos.

Led by Rick Stevens (Argonne’s associate laboratory director for computing, environment and life sciences) and featuring a keynote and panel, the virtual meeting provided an interesting glimpse into both progress and challenges for AI use in science. It was the fourth colloquium in a series. The others tackled: Decarbonization Within Reach; The Quantum Revolution; and Energy Storage for a Changing World.

Keynote speaker Jonathan Rowe, a prominent computer scientist and mathematician with posts at the University of Birmingham and the Alan Turing Institute, set the stage: “Often, when I give talks on AI, I concentrate on all the great things that AI methods have already done in different scientific areas. But today, I’m going to do something slightly different, and we’ll talk about a number of challenges that that still remain in trying to make AI even better and more effective in helping with scientific research. We’ve made some progress on some, we’ve got some ideas about [some] and many, I think we’re still scratching our heads on.”
With that he plunged ahead, calling out ten AI challenges. (A recording of the full ANL colloquium is posted.) Perhaps number one wasn’t surprising – Data Management.
Considered boring by too many, said Rowe, “it’s essential that we start getting to grips with issues to do with data management. There’s all sorts of basic questions about how we manage data [of] that scale. For example, a very basic question is: what should you keep, and what should you throw away when you’re producing data? As an example, CERN routinely throw away nearly all the data that they generate from each experimental run because they simply can’t store everything they produce. They can barely store the essentials. They only store what’s necessary to support the conclusion they’re writing about as a result of the experiment.”

“So what does that mean? That means if you come up with an alternative theory about what might have happened in a particular experiment, you can’t go back and check the data. You have to ask to rerun the experiment and collect what you need for it. So that’s becoming a really big issue. We can generate so much data, but you have to somehow decide what are you going to keep and what are you going to throw away? That raises the question, ‘what [does] open access to data actually mean?’ The big programs like Square Kilometer Array, LSST (Large Synoptic Survey Telescope), they’re publicly funded, and they all promise their data is going to be open access. So LSST will produce something like 15 terabytes of data for one night’s observation. Could someone in the world just ask for that? It’s just not practical,” said Rowe.
“The second challenge is the whole question of how we incorporate scientific knowledge into our AI. The whole purpose of doing science is understanding and generating more knowledge. AI is really good at predicting stuff based on data and that’s useful in a lot of situations. But scientists are not satisfied with just being able to predict stuff. They want to be able to understand the system that’s producing the prediction. That’s really tricky. How can we use our existing scientific knowledge to make sure the AI methods produce better results? How can we make sure the results are even scientifically valid?
“One idea, which I guess quite a few people do, is to incorporate the current physical constraints or scientific constraints into your loss function when you’re when you’re doing your neural network. The example I’ve actually got here is from the lab for molecular biology, where they’re using some Bayesian system, and then incorporate information about molecular structure as a constraint in the Bayesian optimization system. That kind of gives you results that are, you know, physically more realistic than if you don’t do that, but still doesn’t necessarily produce stuff that really obeys the laws of physics,” he said.

“Another idea is to incorporate your physical understanding via a model or a simulation. What I’m showing here is the output of a system we developed with British Antarctic Survey for predicting at the Arctic sea ice. We trained it on hundreds of years’ worth of data, because that data was artificially generated through a physics based model. Then we fine-tuned it with actual observations. But that meant we’ve got a system that really does tend to conform to what’s known physically about the Arctic,” said Rowe.
Here’s the list of challenges that Rowe discussed: data management; scientific knowledge; uncertainty and noise; finding rare things; hidden structures; finding all of the 3D structures in a volume; counting and tracking; AI for digital twins; benchmarking; and closing the loop.
Rowe explored each challenge area and briefly discussed a few solution approaches being explored. One topic that touched on all of the challenges was benchmarking.
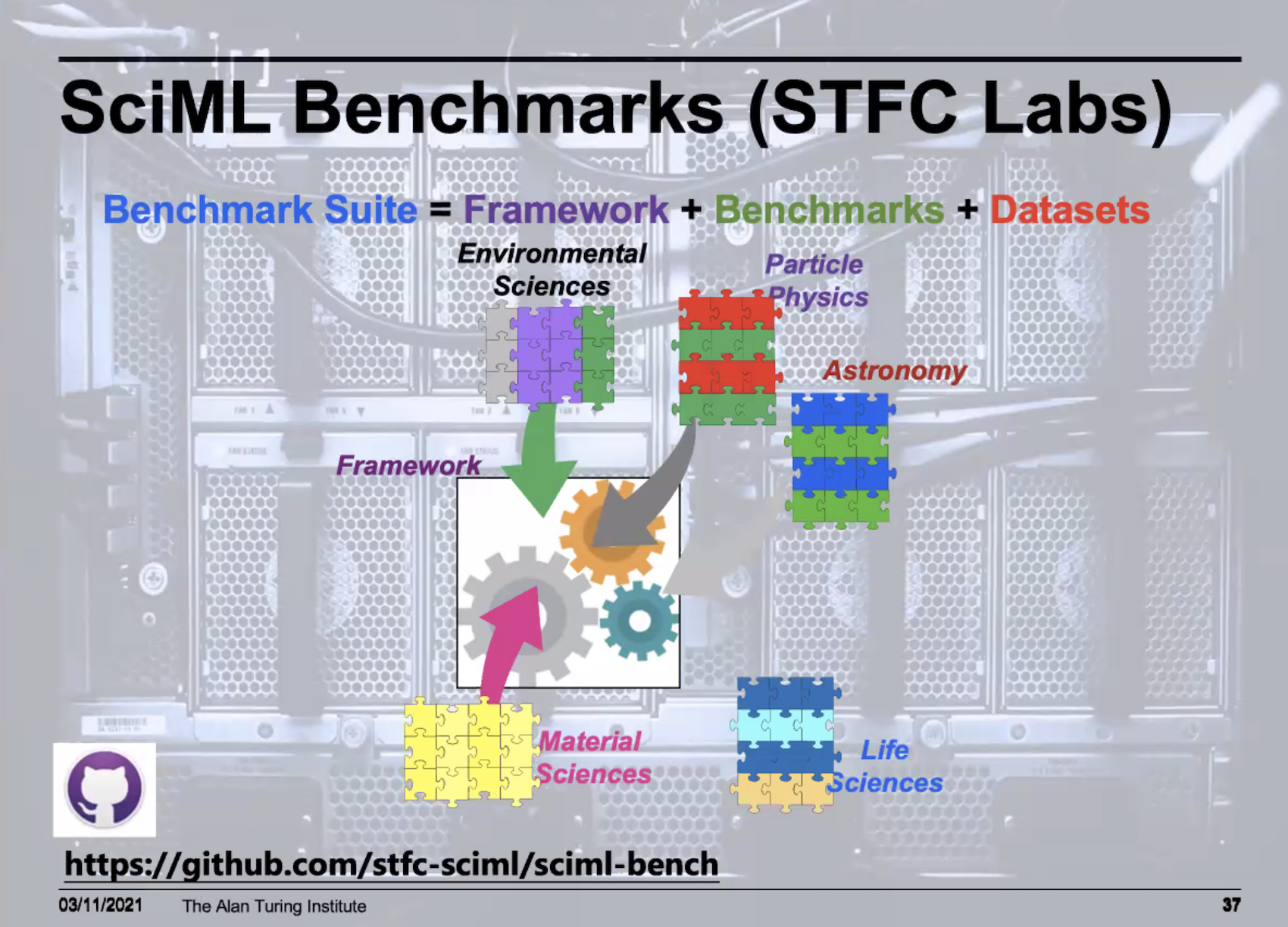
“We’ve got lots of different AI methods now. And we’ve got lots of different scientific data sets. What you’d like to be able to do is to work out for each different kind of data set, and for each different kind of scientific question, what are the best AI methods that are available. Or if you’re a computer scientist, and you’ve come up with what you think is a really neat AI method, you’d like to know how it compares to some of the other ones. And this is really hard right now,” said Rowe. “Similarly, the datasets are produced in different labs around the world and just kind of sit there. Somehow, you need to get these together, and you need to get them together in a way that makes it very easy to do comparisons and benchmarking.”
Rowe noted there is a fair amount of work is being done around benchmarking and cited work by the SciML group. “I want to call out one because this is done by the guys from the scientific machine learning group at the Rutherford [Appleton] labs, who we collaborate with. They’ve started putting forward something called SciML bench available on GitHub, which is really good start putting together a framework to do this. And they’ve got data now from environmental sciences, particle physics, astronomy, and so forth, where you can begin to do this benchmarking, if you’re interested in that. Please go and check it out and see how we might be able to add to it and help,” he said.
(An excerpt from the SciML website showing its tools is included at the end of the article)

The panel was also fascinating. Besides Stevens and Rowe, panelists included: Patrick Riley who leads the AI group at Relay Therapeutics, applying learning methods to the discovery process; Douglas Finkbeiner, professor of Astronomy and Physics at Harvard University; Subramanian Sankaranarayanan, group leader of the theory and modeling group in the Nanoscience and Technology division at ANL; and Rebecca Willett, a professor of statistics and computer science at the University of Chicago.
It’s best to watch the video directly to catch the interplay. One interesting current use of AI was cited by Douglas Finkbeiner of Harvard University. “For example, we want to see the dark mass of the universe. [Using] gravitational lensing, we can see the distortions in background objects behind the mass that requires measurements of the shapes and brightnesses of billions of galaxies,” said Finkbeiner. “Two ways we’ve used AI for that are to keep the telescope system in focus and to de-blend galaxies.”
“Jonathan [Rowe] mentioned the LSST survey at the Bureau Rubin telescope that will produce several petabytes of data over the years. I’ve probably ordered 1000 detections [for] each of tens of billions of objects. So it’s quite a bit of data. [J]ust keeping a telescope like that very complex eight-meter optical system in focus is a bit of a challenge. There are 50 control parameters in the optical system that need to be fixed correctly. It turns out, there’s a nice way to do that with convolutional neural nets. Then once you’ve actually got the images, you can pull out information about the individual galaxies. That’s not so hard if that galaxy is just off by itself isolated, but often these galaxies are kind of overlapping each other, and that is much more of a challenge. We’ve been applying convolutional neural nets to deep-learning the galaxies.”
Link to video: https://www.youtube.com/watch?v=sUYCCfdJkjM
Link to ANL website hosting AI in Science colloquia material: https://www.anl.gov/event/ai-for-science-from-atoms-to-the-cosmos
EXCERPT FROM SCIML WEBSITE
SciML: Open Source Software for Scientific Machine Learning
SciML is a NumFOCUS sponsored open source software organization created to unify the packages for scientific machine learning. This includes the development of modular scientific simulation support software, such as differential equation solvers, along with the methodologies for inverse problems and automated model discovery. By providing a diverse set of tools with a common interface, we provide a modular, easily-extendable, and highly performant ecosystem for handling a wide variety of scientific simulations.
High Performance and Feature-Filled Differential Equation Solving. The library DifferentialEquations.jl is a library for solving ordinary differential equations (ODEs), stochastic differential equations (SDEs), delay differential equations (DDEs), differential-algebraic equations (DAEs), and hybrid differential equations which include multi-scale models and mixtures with agent-based simulations. The templated implementation allows arbitrary array and number types to be compatible, giving compatibility with arbitrary precision floating point numbers, GPU-based computations, unit-checked arithmetic, and other features. DifferentialEquations.jl is designed for both high performance on large-scale and small-scale problems, and routinely benchmarks at the top of the pack.
Physics-Informed Model Discovery and Learning. SciML contains a litany of modules for automating the process of model discovery and fitting. Tools like DiffEqParamEstim.jl and DiffEqBayes.jl provide classical maximum likelihood and Bayesian estimation for differential equation based models, while DiffEqFlux.jl enables the training of embedded neural networks inside of differential equations (neural differential equations or universal differential equations) for discovering unknown dynamical equations, DataDrivenDiffEq.jl estimates Koopman operators (DMD) and utilizes methods like SInDy to turn timeseries data into LaTeX for driving differential equations, and ReservoirComputing.jl for Echo State Networks that learn to predict the dynamics of chaotic systems.
A Polyglot Userbase. While the majority of the tooling for SciML is built using the Julia programming language, SciML is committed to ensure that these methodologies can be used throughout the greater scientific community. Tools like diffeqpy and diffeqr bridge the DifferentialEquations.jl solvers to Python and R respectively, and we hope to see many more developments along these lines in the near future.
Compiler-Assisted Model Analysis and Sparsity Acceleration. Scientific models generally have structures like locality which leads to sparsity in the program structures that can be exploited for major performance acceleration. The SciML builds a set of interconnected tools for generating numerical solver code directly on the models that are being simulated. SparsityDetection.jl can automatically detect the sparsity patterns of Jacobians and Hessians from arbitrary source code, while ModelingToolkit.jl can rewrite differential equation models to re-arrange equations for better stability and automatically parallelize code. These tools then connect with affiliated packages like SparseDiffTools.jl to accelerate solving with DifferentialEquations.jl and training with DiffEqFlux.jl.
ML-Assisted Tooling for Model Acceleration. SciML supports the development of the latest ML-accelerated toolsets for scientific machine learning. Methods like Physics-Informed Neural Networks (PINNs) and Deep BSDE methods for solving 1000 dimensional partial differential equations are productionized in the NeuralPDE.jl library. Surrogate-based acceleration methods are provided by Surrogates.jl.
Differentiable Scientific Data Structures and Simulators. The SciML ecosystem contains pre-built scientific simulation tools along with data structures for accelerating the development of models. Tools like LabelledArrays.jl and MultiScaleArrays.jl make it easy to build large-scale scientific models, while other tools like NBodySimulator.jl provide full-scale simulation simulators.
Tools for Accelerated Algorithm Development and Research. SciML is an organization dedicated to helping state-of-the-art research in both numerical simulation methods and methodologies in scientific machine learning. Many tools throughout the organization automate the process of benchmarking and testing new methodologies to ensure they are safe and battle tested, both to accelerate the translation of the methods to publications and to users. We invite the larger research community to make use of our tooling like DiffEqDevTools.jl and our large suite of wrapped algorithms for quickly test and deploying new algorithms.
























































