 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
At SC21 today, Xilinx launched its most powerful FPGA-based accelerator card – the Alveo U55C – specifically targeting HPC workloads and the datacenter. FPGAs (field programmable gate arrays) have a long productive history as customized accelerator chips used in many embedded applications. It’s only in the last few years that FPGA suppliers have begun offering card-based versions targeting more broadly-based applications; notably the new cards require less ‘chip design and programming expertise’.
Supported by Xilinx’s Vitis Unified Software Platform FPGA, developers and users can skip the need to use granular a hardware description language to program gate arrays and instead use more familiar tools including high-level languages, AI frameworks, function libraries, and compilers. Xilinx is positioning these cards as simply another accelerator to be targeted by developers that can offer all the traditional advantages associated with gate arrays.
The Xilinx datacenter group, now in its third year, has been smoothing out the kinks in making FPGA-based cards easier to deploy. The portfolio now includes seven cards. The new Alveo U55C/Vitis combination supports several HPC-centric functionalities such as RoCE (RDMA over Converged Ethernet), MPI support, and domain-specific development environments including graph analytics, finite element method software, and AI frameworks (see slides below).


“Three years ago, Xilinx started to see that the types of compute that we’re doing including embedded applications were moving into data centers and our ability to accelerate those applications in data centers wasn’t there because we didn’t have applicable interfaces and products for data centers,” said Nathan Chang, HPC product manager, data center group, Xilinx, in a briefing with HPCwire. Likening FPG boards to accelerators broadly, Chang said, “The great thing that happened with GPUs is the paved the way for other accelerators, such as FPGA.”
Analyst Steve Conway of Hyperion Research agrees, “Demand for FPGAs and the revenue for FPGAs has been growing, not quite as fast as for GPUs. The role is different because with FPGAs you can make a tighter fit with an HPC application than you can, generally, with a GPU. We know, for example, that some investment banks on Wall Street have used GPUs as kind of the first step in a process to port their codes onto gate arrays. They might get a 2x or 3x speed-up [with GPUs]. These firms then say, ‘Okay, now we have the confidence to move it onto an FPGA, and we’ll get a 20x to 30x speed-up.”
The persistent obstacle to wider use has been the need to program FPGA at the gate level. Chang said less than one percent of the world’s developers have Verilog and RTL skills.
Xilinx, like others, has steadily worked to abstract away these low-level circuit design skills such that developers can use straightforward APIs to program FPGAs. This is critical in cutting NRE costs and time-to-deploy for board-based products. Xilinx has also beefed up hardware and protocol capabilities.
“With the Alveo U55C, we’ll be leveraging RoCE v2 [and] data center bridging, and you’ll have 200 gigs of Ethernet of bandwidth on every card” said Chang. “You’ll see people building Alveo networks that compete with InfiniBand in performance and latency. Bear in mind also, you can still do this on a lossy network, but the performance may not all of the performance may not be there. The MPI integration allows HPC developers to scale out Alveo data pipelining capabilities across large workloads.”

Xilinx debuted the Vitis toolset in 2019 and has been aggressively building it out. “The whole point was to abstract away the need to develop machine level code like RTL and Verilog or and the need to include hardware design concepts in your development of an application,” said Chang.
The new Alveo U55C card is a single-slot full height, half-length (FHHL) form factor with a low 150W max power. The company says it offers superior compute density and doubles the HBM2 to 16GB compared to its predecessor, the dual-slot Alveo U280 card. The U55C provides more compute in a smaller form factor for creating dense Alveo accelerator-based clusters. It’s built for high-density streaming data, high IO math, and big compute problems that require scale out like big data analytics and AI applications.
“Architecturally, FPGA-based accelerators like Alveo cards provide the highest performance at the lowest cost for many compute-intensive workloads. By introducing a standards-based methodology that enables the creation of Alveo HPC clusters using a customer’s existing infrastructure and network, we’re delivering those key advantages at massive scale to any data center. This is a major leap forward for even broader adoption of Alveo and adaptive computing throughout the data center,” said Salil Raje, executive vice president and general manager, Data Center Group, Xilinx, in the official announcement
As part of the announcement Xilinx highlighted a few HPC and AI uses cases. Here’s an excerpt from the press release:
- “CSIRO, Australia’s national research organization along with the world’s largest radio astronomy antenna array, is utilizing Alveo U55C cards for signal processing in the Square Kilometer Array radio telescope. Deploying the Alveo cards as network-attached accelerators with HBM allows for massive throughput at scale across the HPC signal processing cluster. The Alveo accelerator-based cluster allows CSIRO to tackle the massive compute task of aggregating, filtering, preparing and processing data from 131,000 antennas in real time. The 460Gbps of HBM2 bandwidth across the signal processing cluster is served by 420 Alveo U55C cards fully networked together across P4-enabled 100Gbps switches. The Alveo U55C cluster delivers processing performance with overall throughput at 15Tb/s in a compact power and cost efficient footprint. CSIRO is now completing an example Alveo reference design in order to help other radio astronomy or adjacent industries achieve the same success.
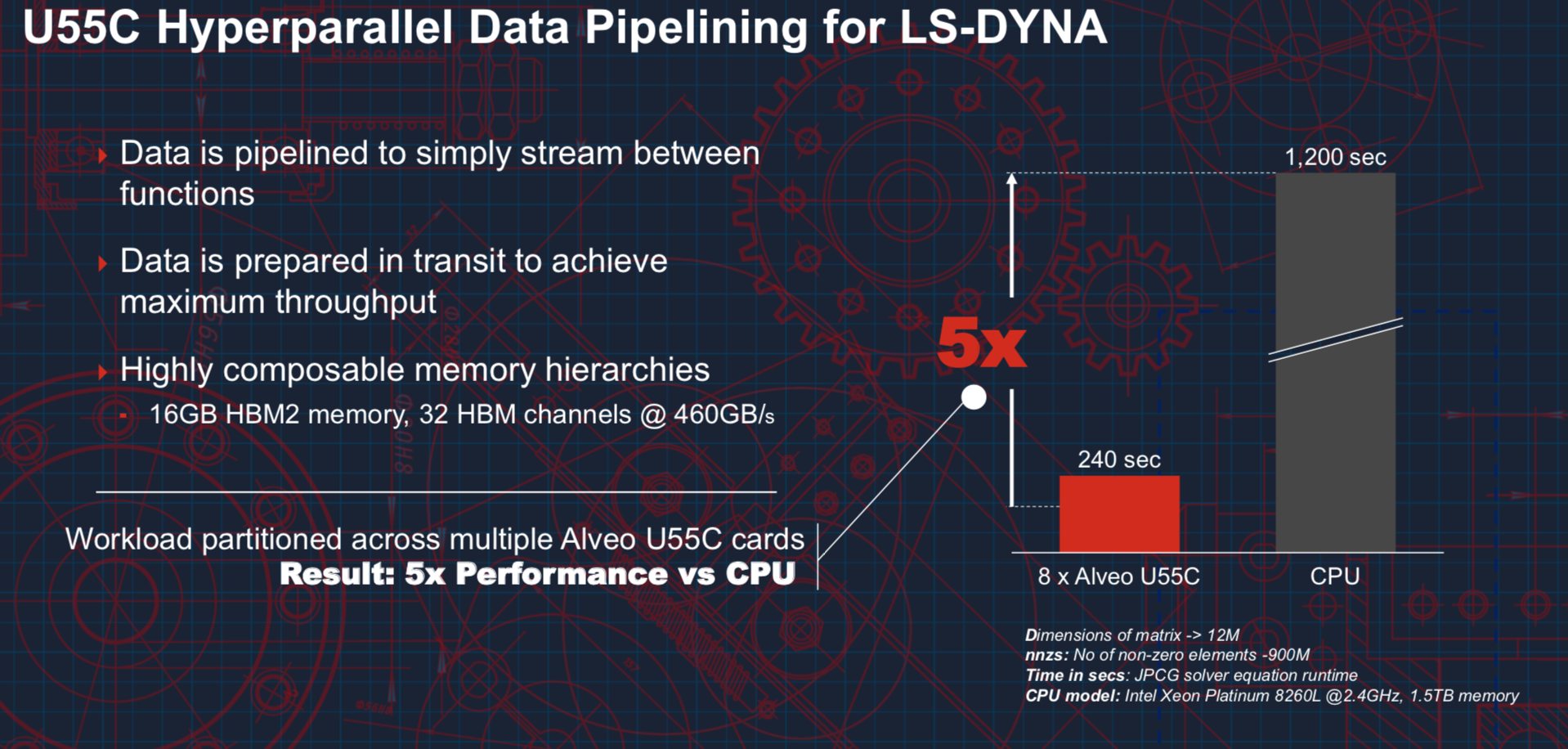
- “Ansys LS-DYNA crash simulation software is used by nearly every automotive company in the world. The design of safety and structural systems hinges on the performance of models as they mitigate the costs of physical crash testing with computer-aided design finite element method (FEM) simulations. FEM solvers are the primary algorithms driving simulations with hundreds of millions of degrees of freedom, these enormous algorithms can be broken out into more rudimentary solvers like PCG, Sparse matrices, ICCG. By scaling out across many Alveo cards with hyperparallel data pipelining, LS-DYNA can accelerate performance by more than 5X in comparison to x86 CPUs. This results in more work per clock cycle in an Alveo pipeline with LS-DYNA customers benefiting from game changing simulation times.
- “TigerGraph, provider of a leading graph analytics platform, is using multiple Alveo U55C cards to cluster and accelerate the two most prolific algorithms that drive graph-based recommendation and clustering engines. Graph databases are a disruptive platform for data scientists. Graphs take data from silos and bring focus to the relationships between data. The next frontier for graph is finding those answers in real time. Alveo U55C accelerates the query times and predictions for recommendation engines from minutes down to milliseconds. By utilizing multiple U55C cards to scale up analytics, the superior computational power and memory bandwidth accelerates graph query speeds up to 45X faster compared to CPU-based clusters. The quality of scores is also increases by up to 35 percent, resulting in greater confidence dramatically lowering false positives to low single digits.”
Conway said the use cases cited are consistent with FPG’s expanding HPC/AI adoption. He noted, “FPGAs have long been used heavily for HPC workloads where you have an organization that basically runs one application 24-by-365; so putting the extra work in to get an additional speed up is worth it. The SKA example world be a perfect circumstance where you got this one application and you want it to run like crazy.”
“Again, it’s kind of the FPGA versus GPU thing. GPUs, whether they’re from AMD or Nvidia or Intel, have a very important place in the market because they are data array kind of processors and we’re in the age of big data and AI. If I stand back a little bit further, you’ve got the HPC market [which] has never been big enough financially to have its own processor. So it’s always had to borrow [one] at least since the time of vector processors. In this case, x86 became dominant, but it’s not a super tight fit, because it wasn’t designed from the beginning for HPC workloads. That left room for things like GPUs to come in and it left room for FPGAs to get in to the mix,” said Conway.
Lastly, there is AMDs pending $36 billion purchase of Xilinx, which is expected to be completed around the end of this year barring last minute glitches. Intel purchased FPGA maker Altera for about $16 billion in 2015. The expansion of a FPG-based-board accelerator market in the datacenter is in both companies’ interest. It will be interesting to see what addition HPC applications and toos develop back-ends for the Vitis platform.
The Alveo U55C is available now and MSRP is $4795, says Xilinx.


























































