 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In the first of a series of guest posts on heterogenous computing, James Reinders, who returned to Intel last year after a short “retirement,” considers how SYCL will contribute to a heterogeneous future for C++. Reinders digs into SYCL from multiple angles and offers suggestions and tips on how to learn more.
SYCL is a Khronos standard that brings support for fully heterogeneous data parallelism to C++. That is much easier to say than it is to grasp why it is so important. SYCL is not a cure-all; SYCL is a solution to one aspect of a larger problem: how do we enable programming in the face of an explosion of hardware diversity that is coming?
Programming in the face of a Cambrian Explosion
John Hennessy and David Patterson described why we are entering “A New Golden Age for Computer Architecture.” They sum up their expectations saying “The next decade will see a Cambrian explosion of novel computer architectures, meaning exciting times for computer architects in academia and in industry.”
CPUs, GPUs, FPGAs, AI chips, ASICs, DSPs, and other innovations will vie for our attention to deliver performance for our applications. Add in the growing ability to integrate multiple dies into single packages in ways we’ve never seen before, and the combined opportunity to accelerate computing through more diversity is extraordinary.
The profound implication for programming is that we need simple solutions to support all hardware. This would never happen in a world of proprietary standards and technologies that ultimately always seek to advantage their creators.

For decades, we have written code focused on performance from a single type of device in the system, and our tools only needed to excel at delivering performance from that single device type.

As hardware diversity explodes (xPU simply means any computational unit from any vendor with any architecture), we can expect that a single application could use multiple device types for computation. This breaks our prior ability to rely on toolchains and languages that have a focused goal to exploit only a single type, or brand, of device.
In the future, we will increasingly need to be critical of tools and languages if they cannot expose the best capabilities of every part of a fully heterogeneous system. We need to demand support for open, multivendor, and multiarchitecture as a base expectation. Put another way, using our xPU term (any computational unit from any vendor with any architecture), we need to expect support for xPUs to be the norm for tools, libraries, compilers, frameworks, and anything else we rely upon as software developers.
“SYCL is not a cure-all; SYCL is a solution to one aspect of a larger problem: how do we enable programming in the face of an explosion of hardware diversity that is coming?”
How SYCL helps for a Cambrian Explosion
When we ask the question “how do we program a truly heterogeneous machine?”, we quickly see we need two things: (1) a way to learn at runtime about all the devices that are available to our application, and (2) a way to utilize the devices to help perform work for our application.
SYCL is a built upon modern C++ to solve exactly these two challenges for heterogeneous machines via two fundamental SYCL capabilities: queue and queue.submit.
SYCL queue
When a SYCL queue is constructed, it creates a connection to a single device. Our options for device selection are (a) accept a default that the runtime picks for us, (b) ask for a certain class of devices (like a GPU, or a CPU, or an FPGA), (c) supply even more hints (e.g., a device supporting device allocations of universal shared memory and FP16), or (d) take full control, examine all devices available, and score them using any system we choose to program.
// use the default selector
queue q1{}; // default_selector
queue q2{default_selector()};
// use a CPU
queue q3{cpu_selector()};
// use a GPU
queue q4{gpu_selector()};
// be a little more prescriptive
queue q6{aspect_selector(std::vector{aspect::fp16, aspect::usm_device_allocations})};
// use complex selection described in a function we write
queue q5{my_custom_selector(a, b, c)};
Constructing a SYCL queue to connect us to a device can be done to whatever level of precision we desire.
SYCL queue.submit
Once we have a queue, we can submit work to it. We refer to these as ‘kernels’ (of code). The order in which work is performed is left to the runtime provided it does not violate any known dependencies (e.g., data needs to be created before it is consumed). We do have an option to ask for an in-order queue if that programming style suits our needs better.
// I promised a queue.submit… here it is…
q.submit([&](handler &h) {
h.parallel_for(num_items,
[=](auto i) { sum[i] = a[i] + b[i]; }
);
});
// it can also be shortened…
q.parallel_for(num_items,
[=](auto i) { sum[i] = a[i] + b[i]; }
);
Work is submitted to a queue which in turn is connected to a device.
The line of code doing the summation is executed on the device.
Kernel programming is an effective approach for parallelism programming
Kernel programming is a great way to express parallelism because we can write a simple operation, like the summation in the above example, and then effectively tell a device to “run that operation in parallel on all the applicable data.” Kernel programming is a well-established concept found in shader compilers, CUDA, and OpenCL. Modern C++ supports this elegantly with lambda functions, as shown in the code examples above.
SYCL Implementations
When we (at Intel) created a project to implement SYCL for LLVM, we gave it the descriptive name Data Parallel C++ (DPC++). LLVM is a fantastic framework for compilers. Many companies have migrated their compiler efforts to use LLVM, including AMD, Apple, IBM, Intel, and Nvidia.
DPC++ is not the only implementation available for use, SYCL enjoys broad support and there are at least five compilers implementing SYCL support at this time: DPC++, ComputeCpp, triSYCL, hipSYCL, and neoSYCL. Intel was the initial creator of the LLVM project to implement SYCL known as DPC++, Codeplay created ComputeCpp, AMD and Xilinx created triSYCL, hipSYCL is from the University of Heidelberg, and neoSYCL is from NEC.
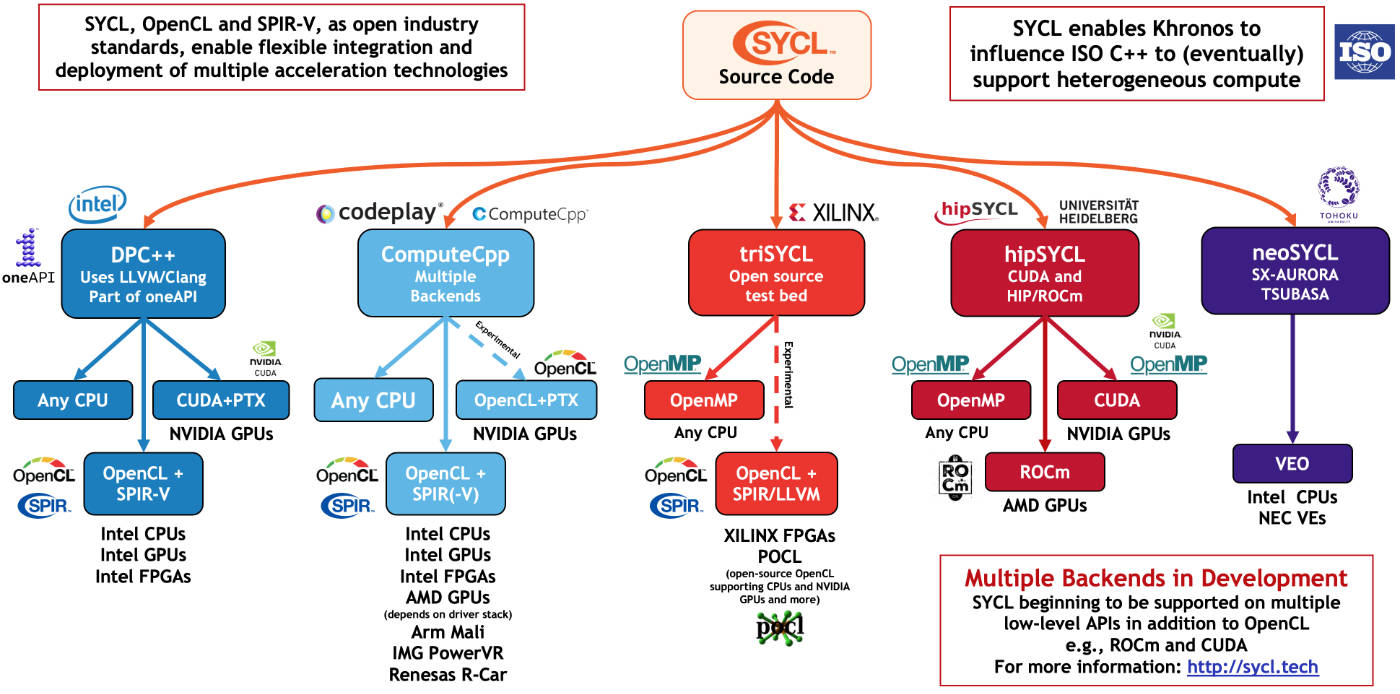
Implications of spanning more than GPUs
Today, for maximum performance applications already do the work of specializing key routines for specific devices. For instance, libraries often choose different implementations for different CPUs or different GPUs.
SYCL offers a way to write common cross-architecture code while allowing specialization when we decide it is justified.
SYCL support for enumerating devices includes the ability to probe the platform and backends, and their capabilities. A key objective is to be open, multivendor, and multiarchitecture.
Many SYCL applications will employ generic program structure and kernel code that can execute on many devices, using device selectors and device queries to compute parameter adjustments. There is no magic/silver bullet here; the programming abstraction allows us to write portable programs, but the capabilities of the devices may require us to rewrite portions of our applications to get the most out of a given device.
Portability and Performance Portability are important, and the demands of a diverse heterogeneous world are getting serious attention far beyond what I can cover here. There’s a community growing around shared best practices (P3HPC). Their workshop (P3HPC = Performance, Portability & Productivity in HPC), held in conjunction with SC21, has a rich collection of presentations. For interested readers, the current state-of-the-art in measuring portability and performance portability is well summarized in “Navigating Performance, Portability, and Productivity.”
C++ parallelism
SYCL is modern C++, based entirely on standard C++ capabilities including templates and lambdas, and does not require any new keywords or language features. We have no syntax to learn beyond modern C++. Extending C++ compilers to be SYCL-aware enables optimizations that boost performance, and allow automatic invocation of multiple backends to create executables for arbitrarily many architectures in a single build.
Today SYCL offers answers to questions critical for full heterogeneous programming. These include “How do I manage local and remote memories, with various coherency models?”, “How do I learn about diverse compute capabilities?”, and “How do I assign work to specific devices, feed them the data they need, and manage their results?”
C++23 is next up in the evolution of C++ in supporting parallel programming. The current direction described for “std::execution” in p2300 aims to provide foundational support for structured asynchronous execution. Understandably, C++23 will not try to solve all the challenges of heterogeneous programming. Nor should it try to do so. Nor should it be criticized for not doing so.
Today, SYCL solves these problems in a way that lets us target hardware from many vendors, with many architectures, usefully. These will inform future standardization efforts, not only in C++ but in other efforts including Python. We have work to do now – SYCL enables that, and we will learn together along the journey.
Open, Multivendor, Multiarchitecture
If you believe in the power of diversity of hardware, and want to harness the impending Cambrian Explosion, then SYCL is worth a look. It’s not the only open, multivendor, multiarchitecture play – but it is the key one for C++ programmers.
SYCL is not magic, but it is a solid step forward in helping C++ users be ready for this New Golden Age of Computer Architecture. As programmers, we can help foster diversity in hardware by keeping our applications flexible. SYCL offers a way to do that, while keeping as much of our code common as fits our needs.
Learn More
For learning, there is nothing better than jumping in and trying it out yourself. The best collection of learning information about SYCL is https://sycl.tech/ including numerous online tutorials, a link for our SYCL book (free PDF download), and a link to the current SYCL 2020 standards specification. In my introductory XPU blog, I explain how to access Intel DevCloud (free online account with access to Intel CPUs, GPUs, and FPGAs), and give tips on trying out multiple SYCL compilers. Following those directions, you can be compiling and running your first SYCL program a few minutes from now.
About the Author

James Reinders believes the full benefits of the evolution to full heterogeneous computing will be best realized with an open, multivendor, multiarchitecture approach. Reinders rejoined Intel a year ago, specifically because he believes Intel can meaningfully help realize this open future. Reinders is an author (or co-author and/or editor) of ten technical books related to parallel programming; his latest book is about SYCL (it can be freely downloaded here).


























































