 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this regular feature, HPCwire highlights newly published research in the high-performance computing community and related domains. From parallel programming to exascale to quantum computing, the details are here.

Large eddy simulation of isothermal and non-isothermal turbulent flows in ventilated classrooms
A team of researchers from Argonne National Laboratory and the University of Illinois at Urbana-Champaign used the Oak Ridge National Laboratory’s Summit supercomputer to perform “large eddy simulations of a modified Nielsen test case, and a newly designed model classroom, with different arrangements of student units and ventilation pathways.” The effort was conducted to understand “the physics of isothermal and buoyant turbulent flows in enclosed ventilated spaces, and on the location and extent of dead zones.” In this paper, they were able to determine “the flow physics in the high Reynolds number jet region, resolve the regions of the flow near the solid wall surfaces, and simulate the effects of temperature gradients on the flow.”
Authors: Ramesh Balakrishnan, Rao Kotamarthi, and Paul Fischer
Hyperparameter optimization of data-driven AI models on HPC systems
As part of the European Center of Excellence in Exascale Computing “Research on AI- and Simulation-Based Engineering at Exascale” program, researchers from CERN, Switzerland, and from the National Institute of Chemical Physics and Biophysics, Estonia, test and evaluate advanced hyperparameter search algorithms, including the Random Search, Hyperband, and ASHA, for “accuracy and accuracy per compute resources spent.” They demonstrated that with the use of high performance computing resources, hyperparameter optimization significantly increased the performance of machine-learned particle flow. In particular, “in the case of MLPF, the ASHA algorithm in combination with Bayesian optimization gives the largest performance increase per compute resources spent out of the investigated algorithm.”
Authors: Eric Wulff, Maria Girone, and Joosep Pata
not open-source ).
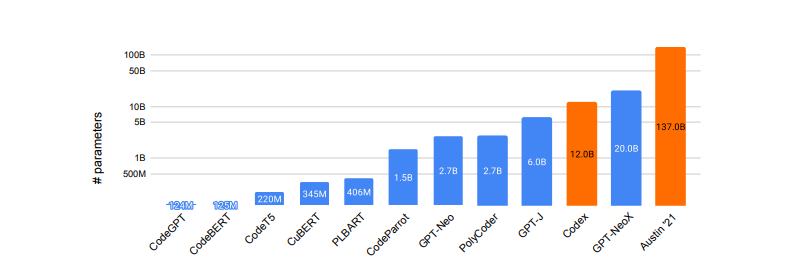
A systematic evaluation of large language models of code
In this preprint paper, researchers from the School of Computer Science at Carnegie Mellon University present “a systematic evaluation of existing models of code – Codex, GPT-J, GPT-Neo, GPT-NeoX, and CodeParrot – across various programming languages.” In addition, they discovered the missing puzzle “piece in the form of a large open-source model trained exclusively on a multi-lingual corpus of code.” Thus releasing three new models, ranging from 160M to 2.7B parameters, dubbed PolyCoder, now available to the public in Github. In particular, PolyCoder “with 2.7B parameters based on the GPT-2 architecture, that was trained on 249GB of code across 12 programming languages on a single machine. In the C programming language, PolyCoder outperforms all models including Codex.”
Authors: Frank F. Xu, Uri Alon, Graham Neubig, Vincent J. Hellendoorn
Distributed non-negative RESCAL with automatic model selection for Exascale data
A multi-institutional, international team introduced pyDRESCALk, a “distributed non-negative RESCAL algorithm for heterogeneous CPU/GPU architectures with automatic selection of the number of latent communities (model selection)” that is written in Python. In this paper, computer scientists demonstrated the results of the scaling tests performed using the Grizzly and Kodiak supercomputers at Los Alamos National Laboratory, and showed “the algorithm’s scalability, and efficient node utilization on large-scale data.” They demonstrated “the correctness of pyDRESCALk with real-world and large synthetic tensors, and the efficacy showing near-linear scaling that concurs with the theoretical complexities. Finally, pyDRESCALk determines the number of latent communities in an 11-terabyte dense and 9-exabyte sparse synthetic tensor.”
Authors: Manish Bhattarai, Namita Kharat, Erik Skau, Benjamin Nebgen, Hristo Djidjev, Sanjay Rajopadhye, James P. Smith, and Boian Alexandrov

model.
BaGuaLu: targeting brain scale pretrained models with over 37 million Cores
In this paper written by a team of international researchers from Tsinghua University, DAMO Academy, Alibaba Group, Zhejiang Lab, Beijing Academy of Artificial Intelligence, the authors present “BaGuaLu, the first work targeting training brain scale models on an entire exascale supercomputer, the New Generation Sunway Supercomputer.” In ancient Chinese mythology, BaGuaLu is known as a magic stove that creates effective medicine. Researchers found that by combining “hardware-specific intra-node optimization and hybrid parallel strategies, BaGuaLu enables decent performance and scalability on unprecedentedly large models.” Ultimately, they demonstrated: “BaGuaLu can train 14.5-trillion parameter models with a performance of over 1 EFLOPS using mixed-precision and has the capability to train 174- trillion-parameter models, which rivals the number of synapses in a human brain.”
Authors: Zixuan Ma , Jiaao He, Jiezhong Qiu, Huanqi Cao, Yuanwei Wang, Zhenbo Sun, Liyan Zheng, Haojie Wang, Shizhi Tang, Tianyu Zheng, Junyang Lin, Guanyu Feng, Zeqiang Huang, Jie Gao, Aohan Zeng, Jianwei Zhang, Runxin Zhong, Tianhui Shi, Sha Liu, Weimin Zheng, Jie Tang, Hongxia Yang, Xin Liu, Jidong Zhai, and Wenguang Chen
Design strategies and approximation methods for high-performance computing variability management
A group of researchers from Virginia Tech and Arizona State University focuses on input/output variability in a study that dives into performance variability management in high performance computing. In this case study, “comparisons are conducted for synthetic data analysis and HPC variability management application to explore the prediction accuracy of grid-based designs (GBDs) and, space-filling designs (SFDs) under different approximation methods.” They perform a “comprehensive investigation of design strategies and the prediction ability of approximation methods.” In addition, the researchers “use both synthetic data simulated from three test functions and the real data from the HPC setting.” The researchers showed that “overall the prediction error decreases as the design size increases. We find that no design outperforms all others uniformly. The Gaussian process (GP) with SFD, however, generates the best results under most scenarios”
Authors: Yueyao Wang, Li Xu, Yili Hong, Rong Pan, Tyler Chang, Thomas Lux, Jon Bernard, Layne Watson, and Kirk Cameron
The impact of hardware specifications on reaching quantum advantage in the fault tolerant regime
In this study, a team of international researchers at the University of Sussex and Universal Quantum, United Kingdom, and Qu & Co B.V., The Netherlands, “investigate how hardware specifications can impact the final run time and the required number of physical qubits to achieve a quantum advantage in the fault tolerant regime.” The team “utilize various space and time optimization strategies that have been previously considered within the field of error-correcting surface codes.” Specifically, they compare Game of Surface Code’s Units and AutoCCZ factories and “calculate the number of physical qubits required to break the 256-bit elliptic curve encryption of keys in the Bitcoin network within the small available time frame in which it would actually pose a threat to do so.” They were able to demonstrate that “it would require 317 x 106 physical qubits to break the encryption within one hour using the surface code, a code cycle time of 1 ls, a reaction time of 10 ls, and a physical gate error of 103.” To break the encryption in one day, it would take 13 x 106 physical qubits.
Authors: Mark Webber, Vincent Elfving, Sebastian Weidt, and Winfried K. Hensinger
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.


























































