Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Roughly a year ago the National Energy Research Scientific Computing Center (NERSC) launched Perlmutter, which was hailed at the time as the “world’s fastest AI supercomputer” by Nvidia whose GPUs provide much of Perlmutter’s power. Since then, NERSC has been aggressively ramping up its mixed AI-HPC workload capability – software, early science apps, AI tools, training, etc. What have we learned so far?
At this week’s AI Systems Summit, Wahid Bhimji, group lead and a big data architect in the data and analytics services group at NERSC, provided a fast-moving tour of NERSC/Perlmutter’s leap into the AI-for-Science world.
“We see at NERSC that AI for science has matured beyond proof of concepts and actually into production. But it’s only on the verge of having a transformative impact,” said Bhimji. “To do that will require using supercomputing scale and also coupling to existing scientific software, large scale scientific simulations, and also big scientific datasets. That’s a role for centers like NERSC, but work is needed across model development and applications as well as deploying suitable computing and tools and technologies and methods to use this computing.”


Named for the Nobel Prize winning cosmologist (Saul Perlmutter) NERSC’s latest system (specs in slide above) is still in “an early science phase where we’re exploiting this system for particular codes to shake it out but not charging the normal way for hours,” said Bhimji. Perlmutter comprises 12 cabinets with over 6,000 GPUs, and also features an all flash Lustre file system. “Phase two of this system is coming soon and includes CPU-only cabinets for [when] we run other science codes that can’t necessarily make use of GPUs. It will also include an upgrade to the whole system networking making use of HPE/Cray’s new Slingshot Ethernet-based high performance network.”
In line with expectations NERSC has seen a jump in AI workflow submissions, noted Bhimji.
“We know this through instrumentation which guides what we can deploy and ask. For example, we’ve instrumented a large fraction of the Python inputs on the system whether or not they use our Python software. We have a link [taken from the slide below] to the paper that shows how we do this. Through this, we can learn several lessons, for example, the large growth in users of PyTorch and TensorFlow, the overall number tripling from 2018 to 2020, and then doubling again in ’21.”
NERSC also does a regular user survey. “We can see that we have deep learning users [and] machine learning users across different science disciplines. [We’ve also seen] that there’s a need for computing scale in that people’s models often take days or even weeks on a single GPU or on single resources without using distributed ones.”
![]() Bhimji roughed out some of the lessons learned from early deployments and the survey. Broadly the ideas NERSC is gleaning now will help it prepare its various systems, including Perlmutter, for broader use by scientists seeking to use AI. The lessons are also useful, he hopes, for other institutions.
Bhimji roughed out some of the lessons learned from early deployments and the survey. Broadly the ideas NERSC is gleaning now will help it prepare its various systems, including Perlmutter, for broader use by scientists seeking to use AI. The lessons are also useful, he hopes, for other institutions.
“The first is that we see a demand for installations where functionality and performance are kind of guaranteed by us. From this survey we could see, perhaps surprisingly, that the majority of people actually use the modules we provide. But also, people need to be able to customize and install their own packages alongside the software. So we need to support recipes for using a condo cloning environment and building on top of it. For Perlmutter, we decided to explore and currently provide both our own compiler software but also make use of the NGC containers that NVIDIA provides,” he said.
“Now, not all HPC centers support containerization, but we have [supported it] for a while through a method called Shifter which makes performance-secure use of Docker containers and works well with the NGC containers and allows you to pull them in directly. This was crucial really in the deployment phase of Perlmutter to ensure a stable and performant software environment despite changes in the underlying system software stack. That said, we did have some deployment issues [and] thanks to a close collaboration with Nvidia. we were able to resolve – so this includes things [like], differences between the Docker and Shifter container stack.”

Given AI’s relative newness, it’s important to give scientists flexibility to try different AI approaches, said Bhimji.
“Scientists need the ability to experiment, particularly in this phase, where they’re exploring lots of different AI models for their science. To do that they need interactivity and one way to provide that is through JupyterHub. We have a very popular JupyterHub service at NERSC that has well over 2,000 users. It’s also a favorite way for people to develop machine learning code. So, all of these bars here in the survey (slide below) are people using Jupyter either at NERSC or elsewhere. At NERSC you can use Jupyter with either shared resources or even dedicated GPU nodes. You can get four GPUs just for your workload, and even multiple GPU nodes. It’s possible to start services that wait on the back system, but then can get quite large distributed resources. We also provide kernels for deep learning software with optimized versions, but also people can build their own kernels.”
Automation is another desirable element to offer, said Bhimji.
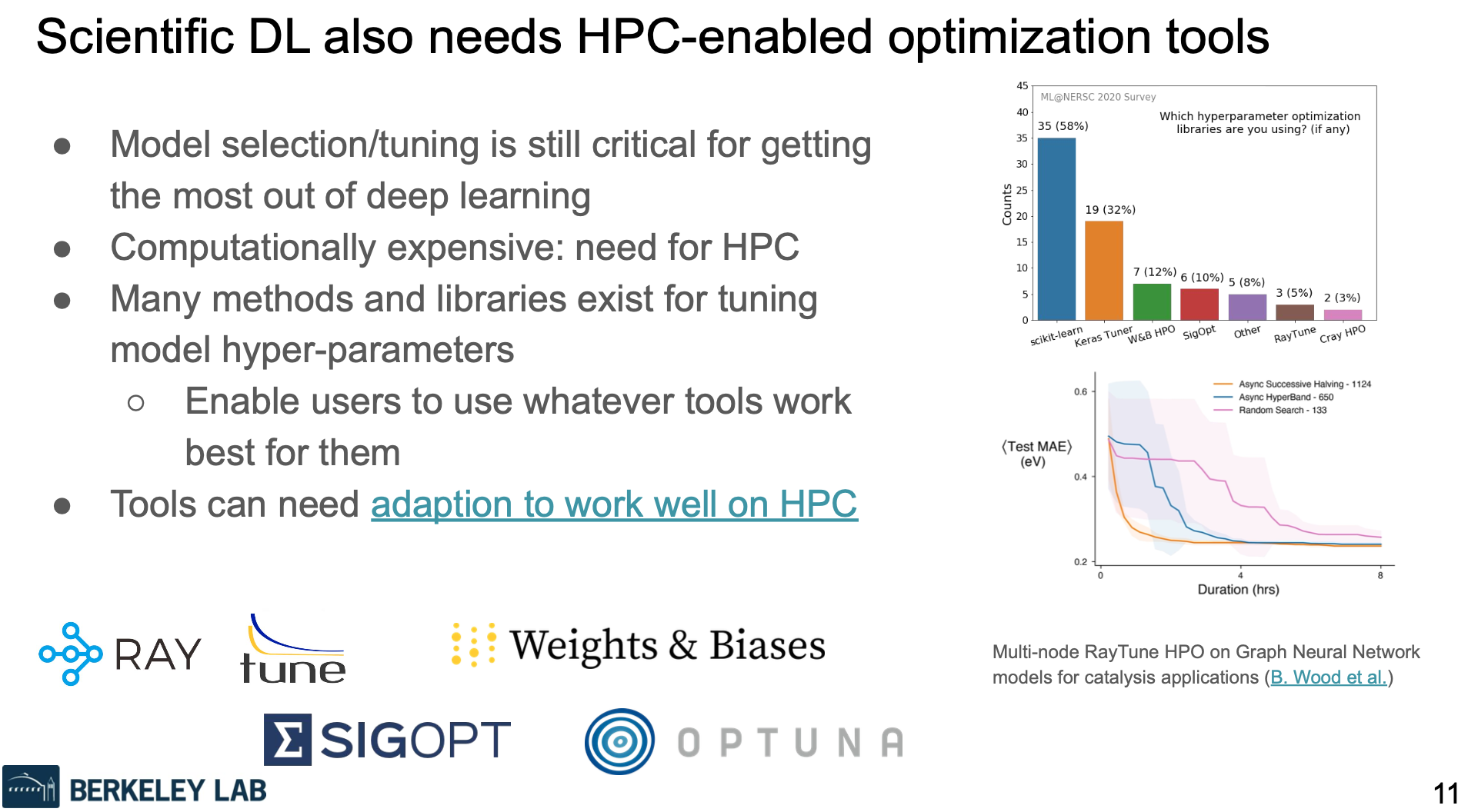
“A particular area for this is in hyperparameter optimization. Model selection and tuning is still pretty important in these deep learning models for getting performance and this is computationally expensive, which means a need for HPC again. But many different tools exist for performing this and we have to support using quite a large number of these NERSC. We’ve also seen that some [of these] can need adaptation to work well in our back systems and our back-system policies and the multi-user environment we’re in. So we have some work – for example, this blog post describes some work with Ray Tune to really enable these tools to work well on our systems,” he said.
As seen at the bottom right of the third slide below, Ray Tune was used to dramatically cut runtime on graph neural network models used on a NERSC catalyst deep learning project.


Aside from tools to help individual researchers, it is also necessary to tune the overall system for AI workflow requirements. Perhaps surprisingly, part of how NERSC has accomplished this is by participating in the MLPerf exercise, including work on developing the MLPerf HPC benchmark (HPC v.7) which debuted at SC20 and was run again at SC21 (HPC v1.0). The latest version included a new benchmark, OpenCatalyst, and also separated out strong-scaling and weak-scaling. The list of participating systems was impressive: Fugaku, Piz Daint (CSCS), Theta ANL), Perlmutter (NERSC), JUWELS Booster (Jülich SC), HAL cluster (NCSA), Selene (Nvidia) and Frontera (TACC).
“We’ve been heavily involved from the start of this HPC working group within the MLPerf organization and this is aiming to look at not only training in general but also particularly for scientific applications, and particularly [use of] HPC resources,” said Bhimji. He noted the new weak scaling metric, “really allows you to fill a big system with multiple models. So, they got submissions from various large HPC centers around the world. The [year-to-year] results are improved, which shows some progress here with large-scale submissions both for the strong scaling time-to-train benchmark a single model, but also these weak-scaling submissions at large-scale on Perlmutter and also on the world’s number one system Fugaku.”
“So what does this mean for Perlmutter? We were able to run this very early in Perlmutter’s deployment, which was really valuable for shaping the system and ensuring the scale of deep learning we wanted to do on the machine. We got some reasonable results – you’d really need to compare with the whole results – but I can tell you that we were the leading time-to-train results for the OpenCatalyst benchmark and close-second place to a well-tuned system, Nvidia’s Selene supercomputer. We also had the largest-scale GPU run, making use of a large fraction of the Perlmutter machine,” he said.
Bhimji noted, “It was okay coming second place to Selene because it allowed us to do some in-depth profiling afterwards to understand why we had any difference. From that, we could see that the dominant bottleneck was actually from the network. And so I don’t expect you to read this profile but the all-reduce stage was actually quite a bit slower than on Selene. But actually this is good news because we know that Perlmutter is having its network upgraded and we expect a potentially 4x improvement just from the hardware. We also even understood smaller one-node differences that we saw as coming from unoptimized kernels in this particular implementation, which is in MXNet. Those kernels will probably be improved, but at the moment are memory bandwidth bound since Selene was using the A100 GPU’s larger (80GB) memory.”


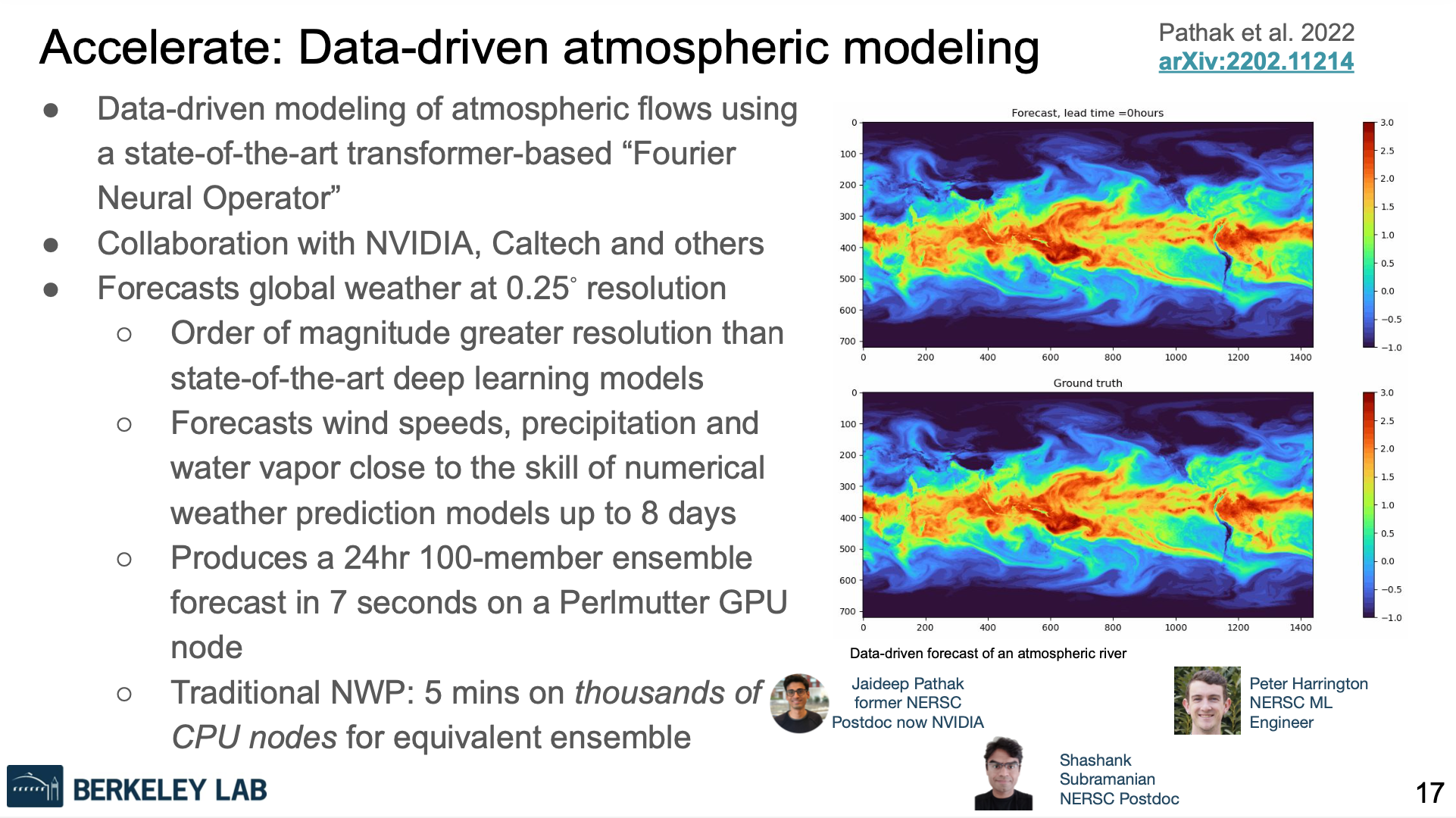
Bhimji also presented brief summaries of early science work that illustrated AI’s ability to speed analysis (astronomy), improve simulation (weather/climate), and automate (catalyst dataset). The following slides summarize all three projects.