 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The battle among high-performance computing hubs to stack up on cutting-edge computers for quicker time to science is getting steamy as new chip technologies become mainstream.
A European supercomputing hub near Munich, called the Leibniz Supercomputing Centre, is deploying Cerebras Systems’ CS-2 AI system as part of an internal initiative called Future Computing to assess alternative computing technologies to inject more speed into the region’s scientific research.
“The idea exactly is to explore these new technologies and see how they would fit with the scientists’ needs and whatever they actually require to do their breakthrough research,” said Dieter Kranzlmüller, director of the supercomputing center, which is also known as Leibniz-Rechenzentrum, or LRZ.
LRZ is thinking less about HPC systems and AI systems, but more in “terms of the character realization of the workflows and the work to be done and what makes sense for the architectures,” said Laura Schulz, LRZ’s head of strategy. She added the CS-2 AI system will be part of wider supercomputing backbone that will be available to researchers in the Bavarian region.
“We’ve got multiple GPUs, we have FPGAs, we have a variety of CPUs, we have prototypes, engineering samples, a really nice assembly, and so we attempt to keep this moving forward,” Shulz said.
LRZ is one of three top supercomputing centers in Germany, with the others being Jülich Supercomputing Centre, which hosts the world’s eight-fastest supercomputer called JUWELS as rated by the Top500 list, and High-Performance Computing Center in Stuttgart, which hosts the 43rd ranked Hazel Hen supercomputer.
The CS-2’s Wafer Scale Engine 2 chip has 850,000 cores and 40GB of memory. The chip is the size of a wafer, and with 2.6 trillion transistors, it is considered the world’s largest chip. The CS-2 is being hooked up with HPE’s Superdome Flex, which can be characterized as staging hardware for CS-2 to perform faster calculations on complex data sets.
Large AI models require huge datasets, and the HPE server has a large shared memory compute which allows the system to very quickly handle pre- and post-processing tasks during the training process. This is enabled by a large number of I/O slots with high-bandwidth connectivity so there are no bottlenecks in data transfers to the CS-2.
An entire dataset can be kept in the Superdome Flex and served to the deep learning and training processes happening on the CS-2, which involves a lot of data movement, said Arti Garg, HPE’s chief strategist for AI.
“The HPE servers are solving a different problem. They are feeding the data into the CS-2. Large models require huge datasets. The datasets are processed and sent to the CS-2 by the HPE system,” said Andrew Feldman, CEO of Cerebras Systems, in an email exchange.
The HPE server simplifies the orchestration, and helps in convergence and accuracy when training AI models. The CS-2 has the ability to run multiple machine learning models simultaneously.
As data sets become larger, the conventional computing approaches to AI are taking longer to deliver results, and that’s where new types of accelerated systems like CS-2 fit in, said Andy Hock, vice president of product management at Cerebras Systems.
He gave an example of the natural language processing, with models growing so large that the compute requirements grew over 1,800 times in a span of two years. The BERT model had 110 million parameters in 2018, and the most recent GPT-3 – which is considered a spin-off of BERT – reached 175 billion parameters in 2020.
“We don’t see this trend waning. We’ve seen the introduction of larger models since then, in the trillion-parameter range, and expect in the near future, that state-of-the-art models may be in the multi-trillion parameter range,” Hock said.
The CS-2 cores are identical and fully programmable, and are optimized for the type of machine-learning compute operations that are common on both large-scale AI and HPC workloads.
Hock said the CS-2 can be thought of as a massive sparse linear algebra accelerator because each core is directly connected to its four nearest neighbors across the entire device via a high-bandwidth low-latency interconnect. The data flow traffic pattern between the cores is fully programmable at compile time.
The interconnect transfers data at 220 petabytes per second, and the WSE-2 retains parameters of neural networks on the chip as it is being executing, which speeds up computation. The hooks for the multi-billion parameter models are stored in the MemoryX technology that Cerebras announced last year, which handles neural networks with up to 120 trillion parameters.
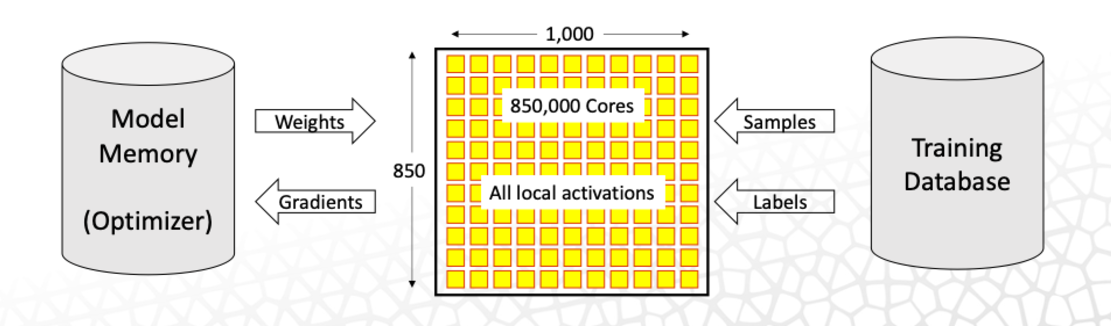
“The technology allows us to hold the parameters off chip, but achieve the performance as if they were on chip. By disaggregating compute and memory, MemoryX enables researchers to run models 100 times larger than today’s largest models on a single CS-2,” Cerebras’ Feldman said.
Developers can use standard ML frameworks approaches like TensorFlow and PyTorch to program for the CS-2. The compiler intercepts the program at compile time and translates the program into an executable that can run on CS-2 devices.
Cerebras also has a lower-level software development kit targeted at HPC users for projects ranging from signal processing to physics-based modeling and simulation.
“We’re continuing to improve on this stack release, to bring more and more features to bear to increase the range of applications that the users can work on,” Hock said.
Related
Wafer Scale to ‘Brain-Scale’ – Cerebras Touts Linear Scaling up to 192 CS-2 Systems
PSC’s Neocortex Upgrades to Cerebras CS-2 AI Systems
Cerebras Doubles AI Performance with Second-Gen 7nm Wafer Scale Engine

























































