 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
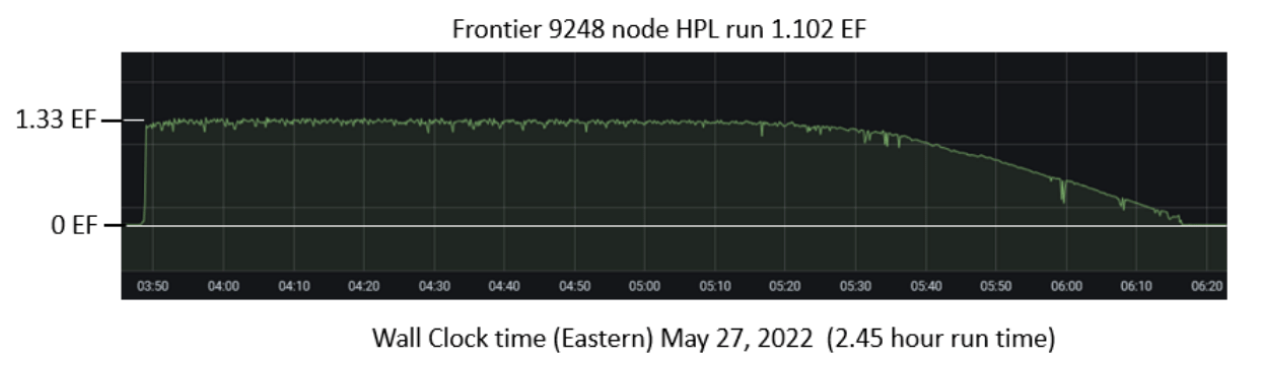
The 59th installment of the Top500 list, issued today from ISC 2022 in Hamburg, Germany, officially marks a new era in supercomputing with the debut of the first-ever exascale system on the list. Frontier, deployed at the Department of Energy’s Oak Ridge National Laboratory, achieved 1.102 exaflops in its highest-scoring High Performance Linpack run, which was completed over the course of two hours and thirty minutes Friday morning in Oak Ridge, Tenn. It was widely anticipated that Frontier would debut on this list, but the run that put them over the one exaflops line was filed in the nick of time, according to list co-author Jack Dongarra.
A new Frontier
Frontier consists of 74 HPE Cray EX cabinets, housing 9,408 nodes, each equipped with one AMD Milan “Trento” 7A53 Epyc CPU and four AMD Instinct MI250X GPUs. Total GPU count: 37,632. Nodes are connected by HPE’s Slingshot-11 interconnect. Each node sports 512GiB DDR4 memory on the CPU and 512GiB HMB2e (128GiB per GPU) with coherent memory across the node.

At 1.102 exaflops of Linpack performance, Frontier is faster than the next seven systems on the Top500 combined. You can’t discount the 0.1 either, said Oak Ridge National Laboratory Director Thomas Zacharia at a media pre-briefing held yesterday. “Each 0.1 represents 100 petaflops, so it’s easy to sort of round off and not think about it. But each decimal point represents a huge capability.”
 Occupying a 372m2 footprint at the Oak Ridge Leadership Computing Facility (OLCF), Frontier aggregates 9.2 petabytes of memory (4.6 petabytes of DDR4 and 4.6 petabytes of HBM2e). There are 37 petabytes of node local storage, and access to 716 petabytes of center-wide storage.
Occupying a 372m2 footprint at the Oak Ridge Leadership Computing Facility (OLCF), Frontier aggregates 9.2 petabytes of memory (4.6 petabytes of DDR4 and 4.6 petabytes of HBM2e). There are 37 petabytes of node local storage, and access to 716 petabytes of center-wide storage.
The Top500 entry for Frontier lists a peak speed (rPeak) of 1.69 exaflops, but stakeholders at HPE and Oak Ridge expect further optimizations to increase peak speed to the project target of 2 exaflops. The Linpack score would also be improved in this case (and likely also Linpack efficiency, which is currently only 65.4 percent) confirmed Thomas Zacharia in a media briefing held yesterday.
The top ten
Besides breaking the exascale barrier — you can read more about that achievement here — the list saw robust activity in the leadership segment with three new systems in the top ten. In addition to Frontier’s rocketing debut, EuroHPC’s LUMI claimed third place and GENCI’s Adastra took 10th place. Both machines followed in the footsteps of Frontier by leveraging the same HPE Cray EX architecture (AMD Milan CPUs, AMD Instinct MI250X GPUs and Slingshot-11 networking).
Installed at CSC’s datacenter in Kajaani, Finland, LUMI is the largest machine of the EuroHPC cohort. LUMI achieved 151.90 Linpack petaflops out of a potential theoretical 214.3 petaflops, which comes out to 71 percent Linpack efficiency. The Top500 machine appears to be a partial build of the full system spec. LUMI’s main partition is expected to deliver 375 HPL petaflops out of 550 peak petaflops, CSC and EuroHPC have reported previously.
Rounding out the top 10 camp, the GENCI Adastra machine in France extracted 46.1 Linpack petaflops out of a theoretical peak of 61.6 petaflops, a Linpack efficiency of 75 percent.
The new HPE Cray EX systems — Frontier, LUMI and Adastra — weren’t just Top500 winners. They also led the Green500 rankings. The number-one Green500 system, achieving 62.68 gigaflops-per-watt energy efficiency, is the Frontier Test and Development system (one of them; the other is “Crusher”). Frontier-TDS is a 1-cabinet iteration of the Cray EX Frontier supercomputer; it provides 19.20 Linpack petaflops (out of a theoretical peak of 23.11), netting a 29th place ranking on the Top500.
 Frontier ranks second on the Green500 with 52.23 gigaflops per watt. LUMI takes a green third-place finish, delivering 51.63 gigaflops per watt. Frontier and Frontier-TDS both submitted at the more rigorous power quality level 3 tier.
Frontier ranks second on the Green500 with 52.23 gigaflops per watt. LUMI takes a green third-place finish, delivering 51.63 gigaflops per watt. Frontier and Frontier-TDS both submitted at the more rigorous power quality level 3 tier.
With Frontier jumping into first place, Riken’s 442-petaflops Fugaku machine is now in second place. The Fujitsu Arm A64FX system was king of the Top500 hill for two years after entering the list in June 2020. With 158,976 A64FX CPU (1x) nodes, Fugaku has maintained the number-one Top500 ranking, the number- one mixed precision HPL-AI ranking (with a score of 2.0 exaflops after a bump in performance in November 2021), the number one HPCG ranking (16 petaflops) and the machine has also made a strong showing on the Green500. Fugaku, mini-Fugaku (“A64FX prototype”) and Wisteria, which also uses A64FX chips, are the only non-accelerated systems in the top 50 of the Green500 (top 57, actually!) to not use accelerators. The systems are #34, #30 and #35 on the current Green500 list, respectively.
Following the new number-three LUMI are the IBM machines Summit (#4) and Sierra (#5), then China’s Tianhe-1A in sixth place. NERSC’s Perlmutter HPE Cray EX system is now in seventh place. Then comes the Nvidia Selene “AI supercomputer” in eighth, followed by Tianhe-2A, the Chinese/NUDT system.
Processors represented in the top ten cohort include AMD CPUs, AMD GPUs, Fujitsu Arm chips, IBM Power CPUs, Sunway CPUs and Nvidia GPUs. The only systems to use Intel CPUs in this grouping are the 2010-era Tianhe-1A system, originally installed at the National Supercomputer Center in Tianjin, China, and the 2013-era Tianhe-2A system, installed at the National Super Computer Center in Guangzhou, China.

All told, the top 10 systems deliver an aggregate 2.27 HPL exaflops out of a potential 3.22 peak exaflops, an efficiency of 70.53 percent.
The broader list
It was only four years ago, in June 2018, that the aggregate performance of the entire Top500 list crossed the exaflops barrier for the first time with 1.22 combined exaflops. The total aggregate performance of the current list is 4.40 exaflops out of 6.85 theoretical peak exaflops (77.8 efficiency).
It’s also helpful to look at the total aggregate performance of the top 100 machines on this latest list as a rough proxy for true HPC machines rather the more loosely coupled IT/Web machines that tend to populate the back half of the list. That top 100 grouping delivers 3.31 exaflops out of a potential 4.76 exaflops peak, which comes out to 69.48 Linpack efficiency.
The 59th Top500 list welcomes 39 new systems in total, with a wide geographical distribution. The U.S. has the most with nine, followed by Germany with five. For the first time in almost a decade, China has no new systems on the list. Despite that, China still has the largest number of systems on the list: 173 compared to 127 for the U.S., which has the second-most systems. By performance share, however, the U.S. lengthens its lead significantly on account of Frontier. The U.S. claims 2.08 exaflops of the list’s total 4.40 exaflops. China’s flops share, meanwhile, falls to 530.24 petaflops, which is roughly 25 percent of the U.S. share.
A conspicuous absence
Speaking of China, the nation is said to have stood up two exascale systems that were in essence validated not by the Top500 or the HPL benchmark, but by the Gordon Bell Prize. The two systems include one called OceanLight that is operated by Wuxi Supercomputing Center and sited in Qingdao, and another, Tianhe-3, located in the city of Tianjin, east of Beijing. Tianhe-3 is based on a Phytium 2000+ FTP Arm chip plus a Matrix 2000+ MTP accelerator. The system, said to have been completed last fall, offers an estimated 1.7 exaflops peak performance and just over 1.3 exaflops on Linpack.
A source we spoke with ahead of ISC 2022 in Hamburg, who works with David Kahaner’s Asian Technology Information Program, said that China is planning a 10-exaflops machine in the 2025-2026 timeframe. The same person disputed recent reporting that said China would have 10 exascale systems by 25, saying that it must have been a misunderstanding. There were two 10-exaflops systems in the works for 2025, our source told us, but now it is much more likely there is only one 10-exaflops system planned for 2026. Like OceanLight, it will implement the Wuxi Sunway architecture, which is based on Alpha cores.
Noted Chinese HPC expert James Lin (vice director, HPC Center, Shanghai Jiao Tong University) said on Twitter a little over a week ago that the Top500 had become a de facto entity list. (The stated purpose of the entity list is to curtail or block the transfer of advanced technology to entities that have been deemed to pose a significant threat to U.S. interests.) “The vendors and the host centers of the top supercomputers in China are on both lists,” he tweeted. “To be on Top500 is to foster international collaboration, but the result is the opposite. We don’t submit to Top500 in order to maintain connections.” The backing entity and supplier vendors of several Chinese systems benchmarked for the list indeed have ended up on the U.S. entity list in recent years.
The vendor landscape
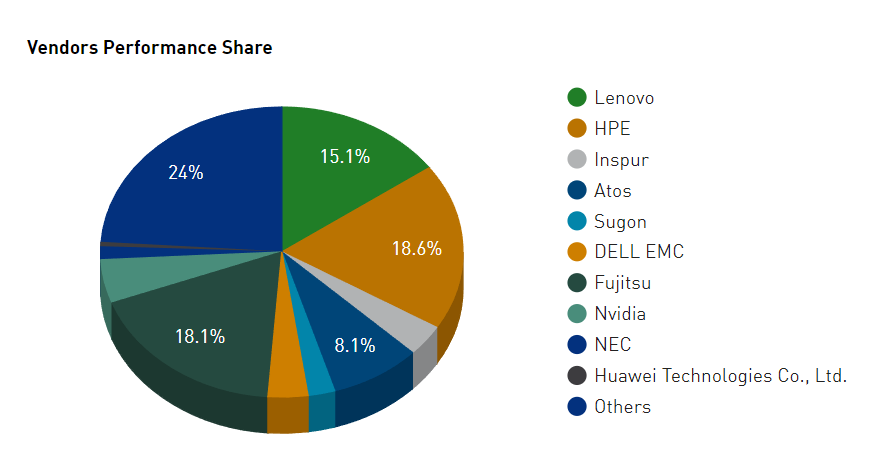
Lenovo, no stranger to the Top500, benchmarked the largest number of new systems (17), and with 14 new systems, HPE had the second-highest number (seven of the 14 employed AMD+AMD nodes, connected by Slingshot-11, including a trio of NNSA/LLNL systems). In terms of all 500 systems, the lineup by pure system count was Lenovo (180), HPE (84) and Inspur (50). By performance share, it shifts to: HPE (18.6 percent), Fujitsu (18.1 percent) and Lenovo (15.1 percent). There were no new Nvidia vendor systems on the list. Eos is expected to put in a good showing, but the DGX H100 nodes that power it won’t start shipping until next quarter, according to Nvidia.

Nvidia is the manufacturer of 19 systems on this list, and it was collaboratively involved in building five others: Sierra (#5), Chervonenkis (#22), Lassen (#30), Galushkin (#40) and Lyapunov (#43).
Intel claims a 77.40 percent share of Top500 systems, down from 81.60 percent six months ago. With 94 systems in total, AMD’s share of the list has grown to 18.80 percent, a jump from 14.60 percent six months ago. Half of the new systems on the list are powered by AMD components.
No IBM systems arrived on or left the list. There are still nine: Summit (#4), Sierra (#5), Marconi-100 (#21), Lassen (#30), PANGEA III (#33), AiMOS (#24), HPC2 (#160), SuperMUC Phase 2 (#205) with Lenovo, and Longhorn (#303).


























































