 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this regular feature, HPCwire highlights newly published research in the high-performance computing community and related domains. From parallel programming to exascale to quantum computing, the details are here.
 EXA2PRO: a framework for high development productivity on heterogeneous computing systems
EXA2PRO: a framework for high development productivity on heterogeneous computing systems
In this paper, a team of international researchers (National Technical University of Athens, Greece; Center for Research and Technology Hellas, Chemical Process and Energy Resources Institute, Greece; Linköping University, Sweden; Center for Research and Technology Hellas, Chemical Process and Energy Resources Institute, Greece; Maison de la Simulation, CEA, CNRS, France; Université de Pau et des Pays de l’Adour, France; Bordeaux University, France; Center for Research and Technology Hellas, Information Technologies Institute, Greece) showcased the key components of the EXA2PRO framework, which aims to improve “developers’ productivity for applications that target heterogeneous computing systems.” The framework is “based on advanced programming models and abstractions that encapsulate low-level platform-specific optimizations and it is supported by a runtime that handles application deployment on heterogeneous nodes.” The researchers “applied the EXA2PRO framework to four HPC applications and demonstrated how it can be used to automatically deploy and evaluate applications to a wide variety of heterogeneous clusters.”
Authors: Lazaros Papadopoulos, Dimitrios Soudris, Christoph Kessler, August Ernstsson, Johan Ahlqvist, Nikos Vasilas, Athanasios I. Papadopoulos, Panos Seferlis, Charles Prouveur, Matthieu Haefele, Samuel Thibault, Athanasios Salamanis, Theodoros Ioakimidis, and Dionysios Kehagias
Deep reinforcement learning for computational fluid dynamics on HPC systems
Researchers from the Institute of Aerodynamics and Gas Dynamics at the University of Stuttgart, Hewlett Packard Enterprise (HPE), the High Performance Computing Center Stuttgart at the University of Stuttgart, and the Laboratory of Fluid Dynamics and Technical Flows at the University of Magdeburg “Otto von Guericke” describe the Relexi framework that they have developed. Relexi “bridges the gap between machine learning workflows and modern computational fluid dynamics (CFD) solvers on HPC systems providing both components with its specialized hardware.” It is “a scalable reinforcement learning (RL) framework… built with modularity in mind and allows easy integration of various HPC solvers by means of the in-memory data transfer provided by the SmartSim library.” In this paper, the researchers demonstrated the “Relexi framework can scale up to hundreds of parallel environments on thousands of cores.” According to the researchers, this capability will make it possible for HPC resources to tackle massive problems or shorten the turnaround times of projects. Lastly, the researchers demonstrated “the potential of an RL-augmented CFD solver by finding a control strategy for optimal eddy viscosity selection in large eddy simulations.”
Authors: Marius Kurz, Philipp Offenhauser, Dominic Viola, Oleksandr Shcherbakov , Michael Resch, Andrea Beck
 DQRA: deep quantum routing agent for entanglement routing in quantum networks
DQRA: deep quantum routing agent for entanglement routing in quantum networks
Researchers from the College of Computing and Software Engineering at the Kennesaw State University in Marietta, Georgia, tackle routing in quantum networks with a “machine-learning-powered quantum routing model for quantum networks” named Deep Quantum Routing Agent (DQRA). In this paper, the authors detail the deep reinforcement routing scheme DQRA, which uses an “empirically designed deep neural network that observes the current network states to accommodate the network’s demands, which are then connected by a qubit-preserved shortest path algorithm.” According to the research team, the “training process of DQRA is guided by a reward function that aims toward maximizing the number of accommodated requests in each routing window.” They demonstrate that on average “DQRA is able to maintain a rate of successfully routed requests at above 80 percent in a qubit-limited grid network and approximately 60 percent in extreme conditions.”
Authors: Linh Le and Tu N. Nguyen
A framework to exploit data sparsity in tile low-rank Cholesky factorization
This paper by a multi-institutional team of researchers from the Innovative Computing Laboratory at the University of Tennessee, the Extreme Computing Research Center, Division of Computer, Electrical, and Mathematical Sciences and Engineering at King Abdullah University of Science and Technology, Oak Ridge National Laboratory, and the University of Manchester proposes a software “framework that couples the PaRSEC runtime system and the HiCMA numerical library to solve challenging 3D data-sparse problems.” In this paper, the researchers demonstrate “the efficiency and scalability of HiCMA-PaRSE.” Performance results performed by researchers found that implementing their HiCMA-PaRSE framework demonstrated “up to 7-fold on Shaheen II and 9-fold on Fugaku performance superiority in situations where the 3D unstructured mesh deformation application renders a matrix operator with low density.” In addition, the software framework “solves a formally dense 3D problem with 52M mesh points on 65K cores in about half an hour.”
Authors: Qinglei Cao, Rabab Alomairy, Yu Pei, George Bosilca, Hatem Ltaief, David Keyes, and Jack Dongarra

Modeling pre-Exascale AMR parallel I/O workloads via proxy applications
In this paper, computer scientists from Oak Ridge National Laboratory in Tennessee and the Georgia Institute of Technology in Georgia dive into ”the modeling of pre-exascale input/output (I/O) workloads of Adaptive Mesh Refinement (AMR) simulations through a simple proxy application.” According to the authors, the ultimate goal of this study is “to provide an initial level of understanding of AMR I/O workloads via lightweight proxy applications models to facilitate autotune data management strategies in anticipation of exascale systems.” Using the Summit supercomputer, the scientists collected data from the AMReX Castro framework “for a wide range of scales and mesh partitions for the hydrodynamic Sedov case as a baseline to provide sufficient coverage to the formulated proxy model.” The results from this study demonstrated that “MACSio can simulate actual AMReX non-linear ‘static’ I/O workloads to a certain degree of confidence on the Summit supercomputer using the present methodology.”
Authors: William F. Godoy, Jenna Delozier, and Gregory R. Watson
HPC extensions to the OpenKIM processing pipeline
A team of researchers from the department of aerospace engineering and mechanics at the University of Minnesota and at the San Diego Supercomputer Center at the University of California, San Diego, develop extensions to the OpenKIM processing pipeline to efficiently enable the use of high performance computing resources with Open Knowledgebase of Interatomic Models (OpenKIM ). OpenKIM is “an NSF Science Gateway that archives fully functional computer implementations of interatomic models (potentials and force fields) and simulation codes that use them to compute material properties. Interatomic models are coupled with compatible simulation codes and executed in a fully automated manner by the OpenKIM processing pipeline, a cloud-based computation platform.” However, previous studies have suggested that the use of the pipeline is not sufficient enough to support large-scale computations. Therefore, researchers detail in this paper the extensions to the OpenKIM processing pipeline to achieve better results using high performance computing resources.
Authors: Daniel S. Karls, Steven M. Clark, Brendon A. Waters, Ryan S. Elliott, and Ellad B. Tadmor
A Taxonomy of Error Sources in HPC I/O Machine Learning Models
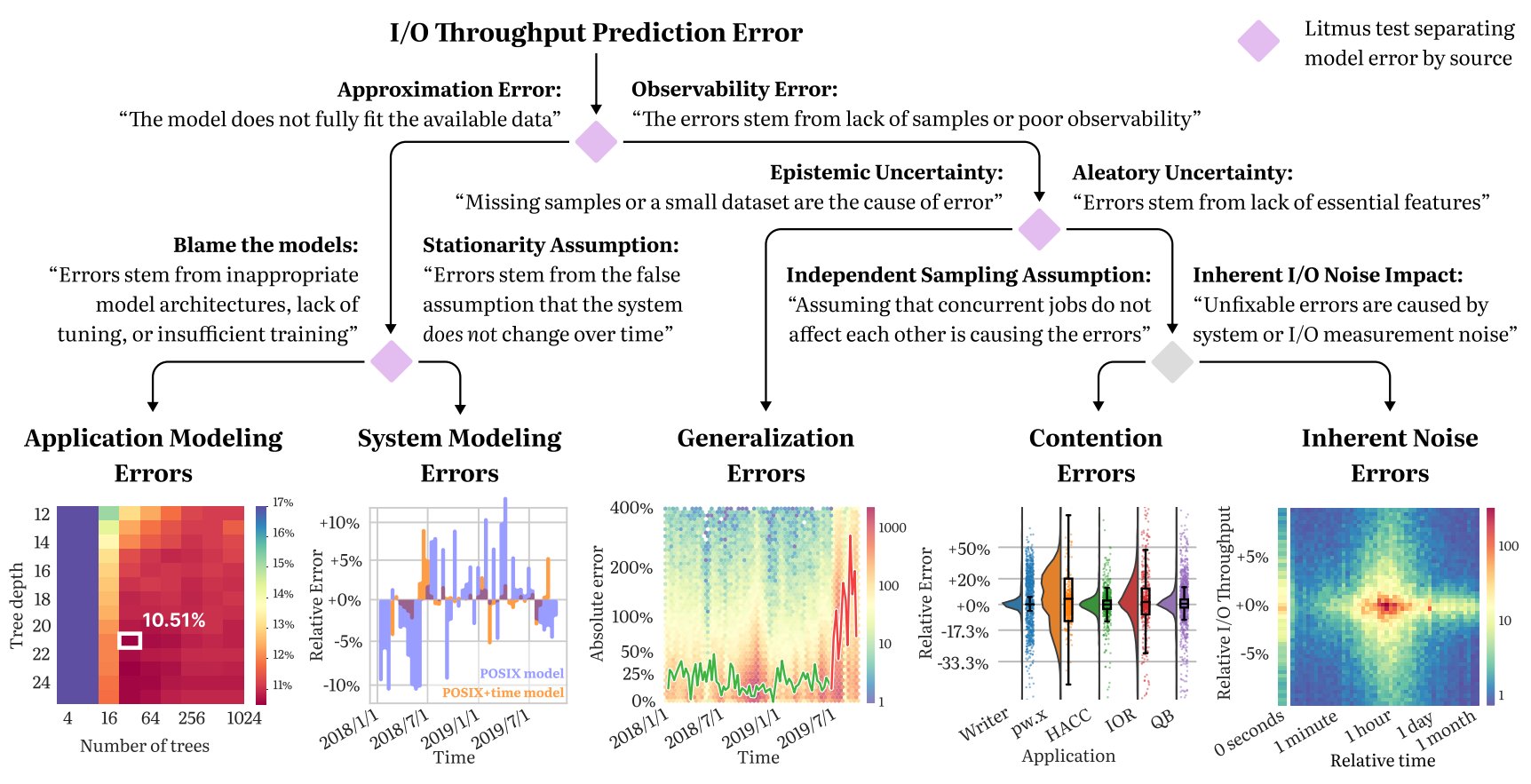 In this paper, a multi-institute research team analyze datasets from the ALCF Theta supercomputer and the NERSC Cori supercomputer to better understand I/O throughput modeling. “We look at why ML models of I/O throughput can wildly mispredict HPC jobs performance. Most of the time, [it’s on account of] bad models or insufficient training, but we found that several other effects are in play — undiagnosed overfitting, contention between jobs, system noise, etc.,” said lead author Mihailo Isakov (Arizona State University) in a Tweet. Isakov also reported that the paper had been accepted by the Supercomputing Conference (SC22). It is currently accessible as an Arxiv pre-print.
In this paper, a multi-institute research team analyze datasets from the ALCF Theta supercomputer and the NERSC Cori supercomputer to better understand I/O throughput modeling. “We look at why ML models of I/O throughput can wildly mispredict HPC jobs performance. Most of the time, [it’s on account of] bad models or insufficient training, but we found that several other effects are in play — undiagnosed overfitting, contention between jobs, system noise, etc.,” said lead author Mihailo Isakov (Arizona State University) in a Tweet. Isakov also reported that the paper had been accepted by the Supercomputing Conference (SC22). It is currently accessible as an Arxiv pre-print.
Authors: Mihailo Isakov, Mikaela Currier, Eliakin del Rosario, Sandeep Madireddy, Prasanna Balaprakash, Philip Carns, Robert B. Ross, Glenn K. Lockwood, Michel A. Kinsy
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.


























































