 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
A new version of a standard backed by major cloud providers and chip companies could change the way some of the world’s largest datacenters and fastest supercomputers are built.
![]() The CXL Consortium on Tuesday announced a new specification called CXL 3.0 – also known as Compute Express Link 3.0 – that eliminates more chokepoints that slow down computation in enterprise computing and datacenters.
The CXL Consortium on Tuesday announced a new specification called CXL 3.0 – also known as Compute Express Link 3.0 – that eliminates more chokepoints that slow down computation in enterprise computing and datacenters.
The new spec provides a communication link between chips, memory and storage in systems, and it is two times faster than its predecessor called CXL 2.0.
CXL 3.0 also has improvements for more fine-grained pooling and sharing of computing resources for applications such as artificial intelligence.
CXL 3.0 is all about improving bandwidth and capacity, and can better provision and manage computing, memory and storage resources, said Kurt Lender, the co-chair of the CXL marketing work group (and senior ecosystem manager at Intel), in an interview with HPCwire.
Hardware and cloud providers are coalescing around CXL, which has steamrolled other competing interconnects. This week, OpenCAPI, an IBM-backed interconnect standard, merged with CXL Consortium, following the footsteps of Gen-Z, which did the same in 2020.
CXL released the first CXL 1.0 specification in 2019, and quickly followed it up with CXL 2.0, which supported PCIe 5.0, which is found in a handful of chips such as Intel’s Sapphire Rapids and Nvidia’s Hopper GPU.
The CXL 3.0 spec is based on PCIe 6.0, which was finalized in January. CXL has a data transfer speed of up to 64 gigatransfers per second, which is the same as PCIe 6.0.
The CXL interconnect can link up chips, storage and memory that are near and far from each other, and that allows system providers to build datacenters as one giant system, said Nathan Brookwood, principal analyst at Insight 64.
CXL’s ability to support the expansion of memory, storage and processing in a disaggregated infrastructure gives the protocol a step-up over rival standards, Brookwood said.
Datacenter infrastructures are moving to a decoupled structure to meet the growing processing and bandwidth needs for AI and graphics applications, which require large pools of memory and storage. AI and scientific computing systems also require processors beyond just CPUs, and organizations are installing AI boxes, and in some cases, quantum computers, for more horsepower.

CXL 3.0 improves bandwidth and capacity with better switching and fabric technologies, CXL Consortium’s Lender said.
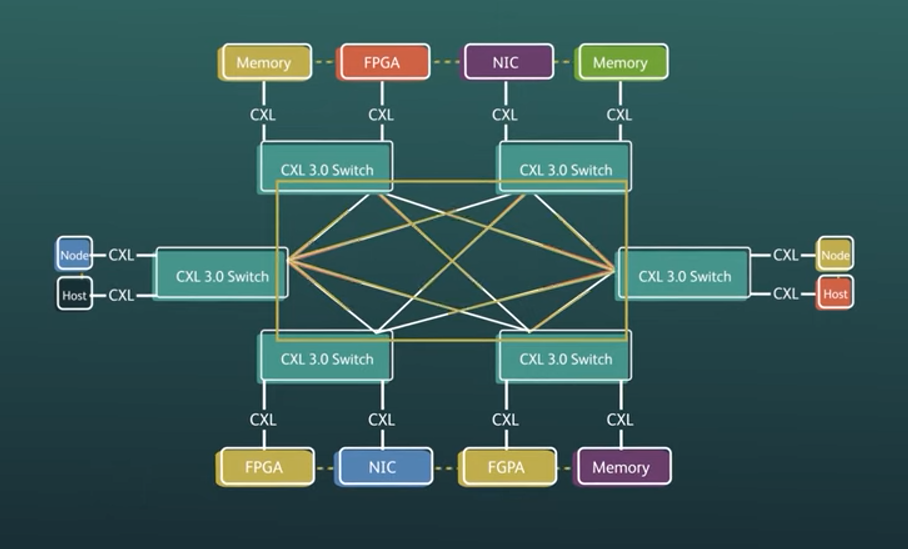
“CXL 1.1 was sort of in the node, then with 2.0, you can expand a little bit more into the datacenter. And now you can actually go across racks, you can do decomposable or composable systems, with the … fabric technology that we’ve brought with CXL 3.0,” Lender said.
At the rack level, one can make CPU or memory drawers as separate systems, and improvements in CXL 3.0 provide more flexibility and options in switching resources compared to previous CXL specifications.
Typically, servers have a CPU, memory and I/O, and can be limited in physical expansion. In disaggregated infrastructure, one can take a cable to a separate memory tray through a CXL protocol without relying on the popular DDR bus.
“You can decompose or compose your datacenter as you like it. You have the capability of moving resources from one node to another, and don’t have to do as much overprovisioning as we do today, especially with memory,” Lender said, adding “it’s a matter of you can grow systems and sort of interconnect them now through this fabric and through CXL.”
The CXL 3.0 protocol uses the electricals of the PCI-Express 6.0 protocol, along with its protocols for I/O and memory. Some improvements include support for new processors and endpoints that can take advantage of the new bandwidth. CXL 2.0 had single-level switching, while 3.0 has multi-level switching, which provides more latency on the fabric.
“You can actually start looking at memory like storage – you could have hot memory and cold memory, and so on. You can have different tiering and applications can take advantage of that,” Lender said.
The protocol also accounts for the ever-changing infrastructure of datacenters, providing more flexibility on how system administrators want to aggregate and disaggregate processing units, memory and storage. The new protocol opens more channels and resources for new types of chips that include SmartNICs, FPGAs and IPUs that may require access to more memory and storage resources in datacenters.
“HPC composable systems… you’re not bound by a box. HPC loves clusters today. And [with CXL 3.0] now you can do coherent clusters and low latency. The growth and flexibility of those nodes is expanding rapidly,” Lender said.
The CXL 3.0 protocol can support up to 4,096 nodes, and has a new concept of memory sharing between different nodes. That is an improvement from a static setup in older CXL protocols, where memory could be sliced and attached to different hosts, but could not be shared once allocated.
“Now we have sharing where multiple hosts can actually share a segment of memory. Now you can actually look at quick, efficient data movement between hosts if necessary, or if you have an AI-type application that you want to hand data from one CPU or one host to another,” Lender said.
The new feature allows peer-to-peer connection between nodes and endpoints in a single domain. That sets up a wall in which traffic can be isolated to move only between nodes connected to each other. That allows for faster accelerator-to-accelerator or device-to-device data transfer, which is key in building out a coherent system.
“If you think about some of the applications and then some of the GPUs and different accelerators, they want to pass information quickly, and now they have to go through the CPU. With CXL 3.0, they don’t have to go through the CPU this way, but the CPU is coherent, aware of what’s going on,” Lender said.
The pooling and allocation of memory resources is managed by a software called Fabric Manager. The software can sit anywhere in the system or hosts to control and allocate memory, but it could ultimately impact software developers.
“If you get to the tiering level, and when you start getting all the different latencies in the switching, that’s where there will have to be some application awareness and tuning of application. I think we certainly have that capability today,” Lender said.
It could be two to four years before companies start releasing CXL 3.0 products, and the CPUs will need to be aware of CXL 3.0, Lender said. Intel built in support for CXL 1.1 in its Sapphire Rapids chip, which is expected to start shipping in volume later this year. The CXL 3.0 protocol is backward compatible with the older versions of the interconnect standard.
CXL products based on earlier protocols are slowly trickling into the market. SK Hynix this week introduced its first DDR5 DRAM-based CXL (Compute Express Link) memory samples, and will start manufacturing CXL memory modules in volume next year. Samsung has also introduced CXL DRAM earlier this year.
While products based on CXL 1.1 and 2.0 protocols are on a two-to-three-year product release cycle, CXL 3.0 products could take a little longer as it takes on a more complex computing environment.
“CXL 3.0 could actually be a little slower because of some of the Fabric Manager, the software work. They’re not simple systems when you start getting into fabrics, people are going to want to do proof of concepts and prove out the technology first. It’s going to probably be a three-to-four year timeframe,” Lender said.
Some companies already started work on CXL 3.0 verification IP six to nine months ago, and are finetuning the tools to the final specification, Bender said.

The CXL has a board meeting in October to discuss the next steps, which could also involve CXL 4.0. The standards organization for PCIe, called the PCI-Special Interest Group, last month announced it was planning PCIe 7.0, which increases the data transfer speed to 128 gigatransfers per second, which is double that of PCIe 6.0.
Lender was cautious about how PCIe 7.0 could potentially fit into a next-generation CXL 4.0. CXL has its own set of I/O, memory and cache protocols.
“CXL sits on the electricals of PCIe so I can’t commit or absolutely guarantee that [CXL 4.0] will run on 7.0. But that’s the intent — to use the electricals,” Lender said.
Under that case, one of the tenets of CXL 4.0 will be to double the bandwidth by going to PCIe 7.0, but “beyond that, everything else will be what we do – more fabric or do different tunings,” Lender said.
CXL has been on an accelerated pace, with three specification releases since its formation in 2019. There was confusion in the industry on the best high-speed, coherent I/O bus, but the focus has now coagulated around CXL.
“Now we have the fabric. There are pieces of Gen-Z and OpenCAPI that aren’t even in CXL 3.0, so will we incorporate those? Sure, we’ll look at doing that kind of work moving forward,” Lender said.

























































