 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
HPC application developers have long relied on programming abstractions that were developed and used almost exclusively within the realm of traditional HPC. OpenMP was created more than 25 years ago to simplify shared-memory parallel computing because programming languages of the day had few to no such features and vendors were developing their own, incompatible abstractions for symmetric multiprocessing.
CUDA C was designed and released by NVIDIA in 2007 as extensions to the C language to support programming massively parallel GPUs, again because the C language lacked the necessary features to support parallelism directly. Both of these programming models have been highly successful because they provide the necessary abstractions to overcome the shortcomings of the languages that they extended in a user-friendly manner.
The landscape has changed a lot, however, in the years since these models were initially released and it’s time to reevaluate where they should fit in a programmer’s toolbox. In this post I discuss why you should be parallel programming natively with ISO C++ and ISO Fortran.
Parallel Programming is Becoming the Standard
Parallel programming was once a niche field reserved only for government labs, research universities, and certain forward-looking industries, but today it is a requirement for all industries. Because of this, mainstream programming languages now support parallel programming natively, and an increasing number of developer tools support these features. It is now possible for applications to be developed to support parallelism from the start, with no need for a serial baseline code.
Such parallel-first codes can be taken to any computer system, whether it’s based on multi-core CPUs, GPUs, FPGAs, or some other novel processor we haven’t thought of yet, and be expected to run on day one. This frees developers from the need to port applications to new systems and enables them to focus on productively optimizing their application or expanding its capabilities instead.
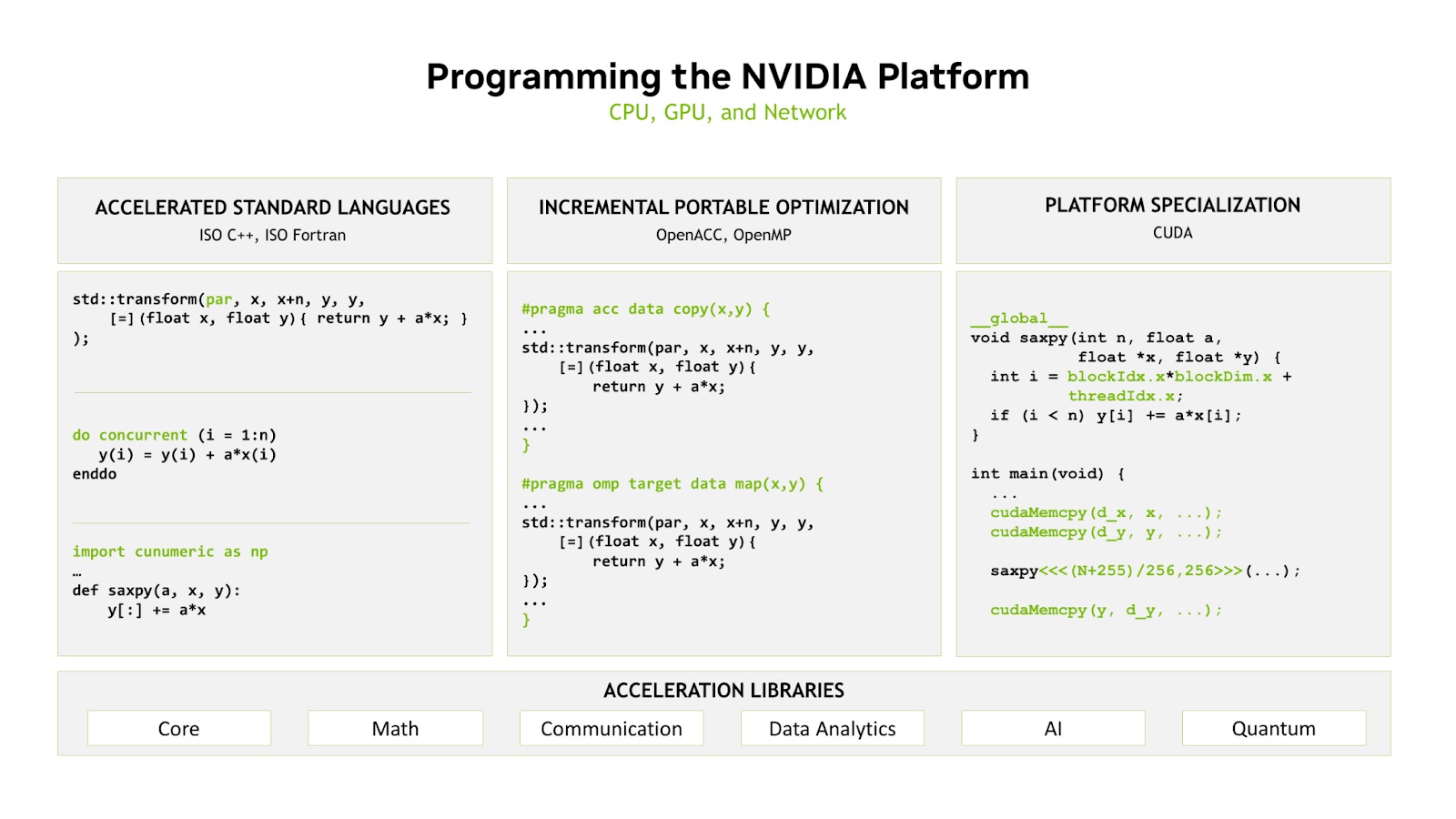
NVIDIA provides three approaches to programming for our platform, all of which are layered on the foundation of our decades-long investment in accelerated libraries and compilers. All of these approaches are fully composable, giving the programmer the choice of how to best balance their productivity, portability, and performance goals.
ISO Languages Achieve Performance and Portability
New application development should be performed using ISO standard programming languages and the parallel features they provide. There is no better example of portable programming models than the ISO languages, so developers should expect that applications written to these standards will run anywhere. Many of the developers we’ve worked with have found that the performance gains from refactoring their applications using standards-based parallelism in C++ or Fortran are already as good as or better than their existing code.
Some developers have elected to perform further optimizations by introducing portable directives, OpenACC, or OpenMP, to improve data movement or asynchrony and obtain even higher performance. This results in application code that’s still fully portable and high-performance. Developers who want to obtain the highest performance in key parts of their applications may choose to take the additional step of optimizing portions of the application with a lower-level approach, such as CUDA, and take advantage of everything the hardware has to offer. And, of course, all of these approaches interact nicely with our expert-tuned accelerated libraries.
Expanding the Standards to Leverage Innovations
There’s a misconception in the industry that CUDA is the language used by NVIDIA to lock-in users, but in fact it’s our language for innovating and exposing the features of our hardware most directly. CUDA C++ and Fortran are in many ways co-design languages, where we can expose hardware innovations and iterate on the programming model quickly. As best practices are developed in the CUDA programming model, we believe they can and should be codified in standards.
For instance, due to the successes of our customers in utilizing mixed-precision arithmetic, we worked with the C++ committee to standardize extended floating point types in C++23. Thanks in a large part to the work of our math libraries team, we have worked with the community to propose a C++ extension for a standardized linear algebra interface that will map well to not only our libraries but community-based and proprietary libraries from other vendors as well. We strive to improve parallel programming and asynchrony in the ISO standard languages because it’s the best thing for our customers and the community at large.
What Do Developers Think?
Professor Jonas Latt at the University of Geneva uses nvc++ and the C++ parallel algorithms in the Pallabos library and said that, “The result produces state-of-the-art performance, is highly didactical, and introduces a paradigm shift in cross-platform CPU/GPU programming in the community.”
Dr. Ron Caplan of Predictive Science Inc. said of his experience using nvfortran and Fortran Do Concurrent, “I can now write far fewer directives and still expect high performance from my Fortran applications.”
And Simon McIntosh-Smith from the University of Bristol said when presenting his team’s results using nvc++ and parallel algorithms, “The ISO C++ versions of the code were simpler, shorter, easier to write, and should be easier to maintain.”
These are just a few of the developers already reaping the rewards of using standards-based parallelism in their development.
Standards-Based Parallel Programming Resources
NVIDIA has a range of resources to help you fall in love with standards-based parallelism.
Our HPC Software Development Kit (SDK) is a free software package that includes:
- NVIDIA HPC compilers for C, C++, and Fortran
- The CUDA NVCC Compiler
- A complete set of accelerated math libraries, communication libraries, and core libraries for data structures and algorithms
- Debuggers and profilers
The HPC SDK is freely available on x86, Arm, and OpenPOWER platforms, regardless of whether you own an NVIDIA GPU, and is even Amazon’s HPC software stack for Graviton3.
NVIDIA On-Demand also has several relevant recordings to get you started (try “No More Porting: Coding for GPUs with Standard C++, Fortran, and Python”), as well as our posts on the NVIDIA Developer Blog.
Finally, I encourage you to register for GTC Fall 2022, where you’ll find even more talks about our software and hardware offerings, including more information on standards-based parallel programming.

About Jeff Larkin
Jeff is a Principal HPC Application Architect in NVIDIA’s HPC Software team. He is passionate about the advancement and adoption of parallel programming models for High Performance Computing. He was previously a member of NVIDIA’s Developer Technology group, specializing in performance analysis and optimization of high performance computing applications. Jeff is also the chair of the OpenACC technical committee and has worked in both the OpenACC and OpenMP standards bodies. Before joining NVIDIA, Jeff worked in the Cray Supercomputing Center of Excellence, located at Oak Ridge National Laboratory.


























































