 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this regular feature, HPCwire highlights newly published research in the high-performance computing community and related domains. From parallel programming to exascale to quantum computing, the details are here.

Compressed basis GMRES on high-performance graphics processing units
An international team of researchers from Jaume I University (Spain), Karlsruhe Institute of Technology (Germany), the University of Tennessee at Knoxville (USA), and Valencia Polytechnic University (Spain) provided a review of a generalized minimal residual (GMRES) algorithm “that maintains the Krylov basis in a compressed (compact) form, in order to reduce the traffic between memory and the processor arithmetic units, while performing all arithmetic in double-precision, to preserve the hardware supported high precision arithmetic in all computations.” In this open access paper published in The International Journal of High Performance Computing Applications, researchers leveraged “Ginkgo’s memory accessor in order to integrate a communication-reduction strategy into the (Krylov) GMRES solver that decouples the storage format (i.e., the data representation in memory) of the orthogonal basis from the arithmetic precision that is employed during the operations with that basis.” The team’s work also resulted in a “high-performance implementation of the ‘compressed basis GMRES’ solver in the Ginkgo sparse linear algebra library using a large set of test problems from the SuiteSparse Matrix Collection.”
Authors: Jose I. Aliaga, Hartwig Anzt, Thomas Grützmacher, Enrique S. Quintana-Ortiz, and Andres E. Toas
A team of researchers from Nvidia, the National Energy Research Scientific Computing Center at Lawrence Berkeley Lab, and Caltech, introduce FourCastNet. According to the researchers, “FourCastNet produces accurate instantaneous weather predictions for a week in advance, enables enormous ensembles that better capture weather extremes, and supports higher global forecast resolutions.” The data-driven deep learning Earth system emulator, FourCastNet “can predict global weather and generate medium-range forecasts five orders-of-magnitude faster than NWP while approaching state-of-the-art accuracy.” It is optimized for “three supercomputing systems: Selene, Perlmutter, and JUWELS Booster up to 3,808 NVIDIA A100 GPUs, attaining 140.8 petaFLOPS in mixed precision (11.9% of peak at that scale). The time-to-solution for training FourCastNet measured on JUWELS Booster on 3,072 GPUs is 67.4 minutes, resulting in an 80,000 times faster time-to-solution relative to state-of-the-art NWP, in inference.”
Authors: Thorsten Kurth, Shashank Subramanian, Peter Harrington, Jaideep Pathak, Morteza Mardani, David Hall, Andrea Miele, Karthik Kashinath, and Animashree Anandkumar
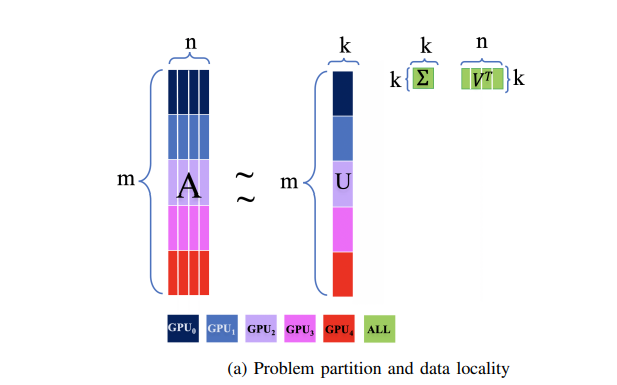
Distributed out-of-memory SVD on CPU/GPU architectures
Los Alamos National Laboratory researchers “propose an efficient, distributed, out-of-memory implementation of the truncated singular value decomposition (t-SVD) for heterogeneous (CPU+GPU) high performance computing systems.” In this paper, the researchers present “an implementation of SVD based on the power method, which is a truncated singular values and singular vectors estimation method.” Researchers demonstrate the “distributed out of core SVD algorithm to successfully decompose dense matrix of size 1TB and sparse matrix of size 128 PB with 1e-6 sparsity.” The researchers also demonstrated the scalability of their SVD algorithm “to successfully decompose dense matrix of size 1TB and sparse matrix of size 128 PB with 1e-6 sparsity.”
Authors: Ismael Boureima, Manish Bhattarai, Maksim E. Eren, Nick Solovyev, Hristo Djidjev, Boian S. Alexandrov
Japanese researchers from Tokushima University, the University of Tsukuba, and the University of Tokyo aim to predict “tsunami flow depth distribution in real time using regression and machine learning.” In this open access article, published in the Earth, Planets and Space journal, the researchers collect training data from 3,480 earthquake-induced tsunamis created by numerical simulations in the Nankai Trough region. In their study, researchers developed “multiple regression equations for a power law using these datasets and the conjugate gradient method.” In addition, they “employed the multilayer perceptron method, a machine learning technique, to evaluate the prediction performance.” They found that “both methods accurately predicted the tsunami flow depth calculated by testing 11 earthquake scenarios in the cabinet office of the government of Japan. The RMSE between the predicted and the true (via forward tsunami calculations) values of the mean flow depth ranged from 0.34–1.08 m.”
Authors: Masato Kamiya, Yasuhiko Igarashi, Masato Okada, and Toshitaka Baba

Nimble GNN embedding with tensor-train decomposition
In this open access research paper by a team of researchers from Amazon and the Georgia Institute of Technology, the researchers describe “a new method for representing embedding tables of graph neural networks (GNNs) more compactly via tensortrain (TT) decomposition.” The researchers take the following scenario where “(a) the graph data that lack node features, thereby requiring the learning of embeddings during training; and (b)… wish to exploit GPU platforms, where smaller tables are needed to reduce host-to-GPU communication even for large-memory GPUs.” According to the researchers, “when combined with judicious schemes for initialization and hierarchical graph partitioning, this approach can reduce the size of node embedding vectors by 1,659× to 81,362× on large publicly available benchmark datasets, achieving comparable or better accuracy and significant speedups on multi-GPU systems.”
Authors: Chunxing Yin, Da Zheng, Israt Nisa, Christos Faloutsos, George Karypis, Richard Vuduc
Accelerating task-based iterative applications
Barcelona Supercomputing Center researchers introduce taskiter, a new pragma for OmpSs-2 and OpenMP programming models. The newly created directives allow the “use of directed cyclic task graphs (DCTG) to minimize runtime overheads.” In addition, the researchers “present a simple immediate successor locality-aware heuristic that minimizes task scheduling overhead by bypassing the runtime task scheduler.” In this paper, researchers demonstrate that “applying both techniques to task-based iterative applications delivers significant scalability improvements and speedups, achieving an average speedup of 3.7x for small granularities compared to the reference OmpSs-2 implementation and a 5x and 7.46x speedup over the LLVM and GCC OpenMP runtimes, respectively. Moreover, the resulting task-based applications using the right granularity can compete or outperform work-sharing versions of all benchmarks.”
Authors: David Álvarez and Vicenç Beltran
In this open access article published in the ACM Transactions on Quantum Computing journal, mathematicians from the University of California, Berkeley, and Lawrence Berkeley National Laboratory “demonstrate that with an optimally tuned scheduling function, adiabatic quantum computing (AQC) can readily solve a quantum linear system problem (QLSP) with O(κ poly(log(κ/ϵ ))) runtime, where κ is the condition number, and ϵ is the target accuracy.” According to the authors, their “method is applicable to general non-Hermitian matrices, and the cost, as well as the number of qubits, can be reduced when restricted to Hermitian matrices, and further to Hermitian positive definite matrices.” The paper details that the “numerical results indicate that QAOA can yield the lowest runtime compared to the time-optimal AQC, vanilla AQC, and the recently proposed randomization method.”
Authors: Dong An and Lin Lin
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.
























































