 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Last month I discussed why standards-based parallel programming should be in your HPC toolbox. Now, I am highlighting the successes of some of the developers who have already made standards-based parallelism an integral part of their strategy. As you will see, success with standards-based programming isn’t limited to just mini-apps.
Fluid Simulation with Palabos

Palabos is an open-sourced library developed at the University of Geneva for performing computational fluid dynamics simulations using Lattice Boltzmann Methods. The core library is written in C++ and the developers desired a way to maintain a single source code between CPUs and GPU accelerators. ISO C++ parallel algorithms provide an attractive means to portable on-node parallelism that composes well with their existing MPI code.
Dr. Jonas Latt and his team started converting their code to use C++ parallel algorithms by first developing the STLBM mini-app. This enabled them to quickly determine the best practices that they would later apply to Palabos. The first thing they learned was that their existing data structures were not ideal for parallelization, on a GPU or modern CPU. They restructured STLBM to be data-oriented, rather than object-oriented.
After restructuring their data structures to be ready for parallelization, the team began to replace their existing for loops with C++ parallel algorithms. In many cases, this is as simple as using a std::for_each or std::transform_reduce, although choosing the right algorithm for the job will result in the best performance.
Once they’d addressed the on-node parallelism, it came time to optimize the scalability of their application. They found that they achieved the best scalability by mixing in the open source Thrust Library from NVIDIA to ensure MPI buffers were pinned in GPU memory. This optimization causes the MPI library to transfer directly between GPU buffers, eliminating the CPU from the communication altogether. The interoperability between ISO C++ and other C++-based libraries enabled this optimization.
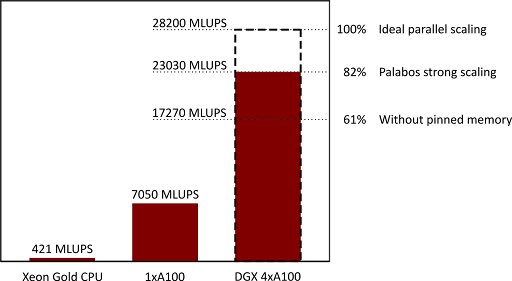
Even with using ISO C++ parallelism, instead of a lower-level approach like CUDA C++, the team is able to achieve a 55x performance speed-up from running on their four GPUs instead of all cores of their Xeon Gold CPU. In fact, they recorded a 82% strong scaling efficiency going from one GPU to four GPUs and a 93% weak scaling efficiency by running a 4x larger problem.
Dr. Latt has written a two-part blog post on his experience rewriting STLBM and Palabos to use MPI and ISO C++ parallel algorithms, on the NVIDIA developer blog.

Simulating Complex Solar Magnetic Fields
Predictive Science Incorporated is a scientific research company that studies the magnetohydrodynamic properties of the Sun’s corona and heliosphere. Their applications support several NASA missions to better understand the Sun. They have a number of scientific applications that use MPI and OpenACC to take advantage of GPU-accelerated HPC systems.
Dr. Ronald Caplan and Miko Stulajter asked the question whether support for the Fortran language has evolved to the point that it’s possible to refactor their applications to use Fortran’s do concurrent loop in place of OpenACC directives in their applications. They first attempted this with a mini-app called diffuse, which is a mini-app for their HipFT application. They found that they could replace OpenACC with do concurrent in diffuse and submitted their results to the “Workshop for Accelerator Programming using Directives”at Supercomputing 2021, winning the best paper award at that workshop.
Following the success of diffuse, they moved to a more complex code, POT3D, which solves a potential field model of the Sun’s coronal magnetic field and is a part of the SPEChpc benchmark suite. Unlike diffuse, POT3D uses MPI in addition to OpenACC, which they believed would make their refactoring more difficult. They found that they could remove all but three OpenACC directives from their application: one to select the GPU device and two to perform atomic array updates. After removing some 77 directives from their application, their performance using the NVIDIA nvfortran compiler and an NVIDIA A100 GPU was just 10% slower than their hand-written OpenACC code.

While a 10% loss in performance is a small cost for reducing their total lines of code by 147 lines, they wanted to understand the cause for this loss and whether they could make up the difference. After some experimentation they determined that the culprit for this performance loss is data migrations that occur due to the use of CUDA Unified Memory by nvfortran. By adding back only enough directives to optimize this data migration in their code, their application performance returned to that of the original baseline code.
Caplan and Stulajter now have a production application with 39 fewer directives and the same performance on both the CPU and GPU as their original MPI+OpenACC code. You can read more about their experience using Fortran do concurrent in POT3D, including example code, here.
In this article I’ve shown just two of the growing number of applications who have migrated their parallelism from specialized APIs to standard language-based solutions. The applications observed little to no performance downside to these changes and significant improvements in productivity and portability.
How to Get Started with Standards-based Parallel Programming
Interested in beginning to use standards-based parallel programming in your application? You can download the NVIDIA HPC SDK free today and experiment with our various compilers and tools.
NVIDIA GTC Fall 2022 just wrapped and has some great on-demand resources you can watch. I recommend checking out “A Deep Dive into the Latest HPC Software” and “Developing HPC Applications with Standard C++, Fortran, and Python”.

About Jeff Larkin
Jeff is a Principal HPC Application Architect in NVIDIA’s HPC Software team. He is passionate about the advancement and adoption of parallel programming models for High Performance Computing. He was previously a member of NVIDIA’s Developer Technology group, specializing in performance analysis and optimization of high performance computing applications. Jeff is also the chair of the OpenACC technical committee and has worked in both the OpenACC and OpenMP standards bodies. Before joining NVIDIA, Jeff worked in the Cray Supercomputing Center of Excellence, located at Oak Ridge National Laboratory.
























































